对抗知识焦虑,从看懂这条开始
App 下载
AI解数学题不再死套模板,会选新思路了
解题思路多样性|数学题解法|I²B-LPO框架|阿里达摩院|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载解题思路多样性|数学题解法|I²B-LPO框架|阿里达摩院|大语言模型|人工智能
给大模型一道数学题,让它写10份解题草稿,它真能学到更多解法吗?过去的答案往往是“不能”——哪怕写100份,草稿里的解题思路也高度雷同,无非是换了几种措辞,核心逻辑还是那套老模板。这就像让一个学生反复抄同一份正确答案,看似练了很多,实则没半点长进。直到阿里达摩院的团队拿出I²B-LPO框架:它让模型在解题的“犹豫时刻”主动分叉,尝试不同思路,还能自动把废话连篇的草稿扔掉。最终,模型在数学题上的准确率最高提了5.3%,解题思路的多样性翻了近一番。
你可以把大模型解数学题的过程,想象成走一条分岔路:大多数时候它都在走熟悉的主干道,哪怕有小路也不敢拐——这就是强化学习里的“探索-利用困境”:模型既想靠熟悉的模板拿高分,又怕走新路出错。过去的训练方法,要么让模型在整条路上乱晃(全局熵正则化),结果走了一堆没用的远路;要么只在路边的小石子上踢一脚(token级扰动),根本拐不进新方向。
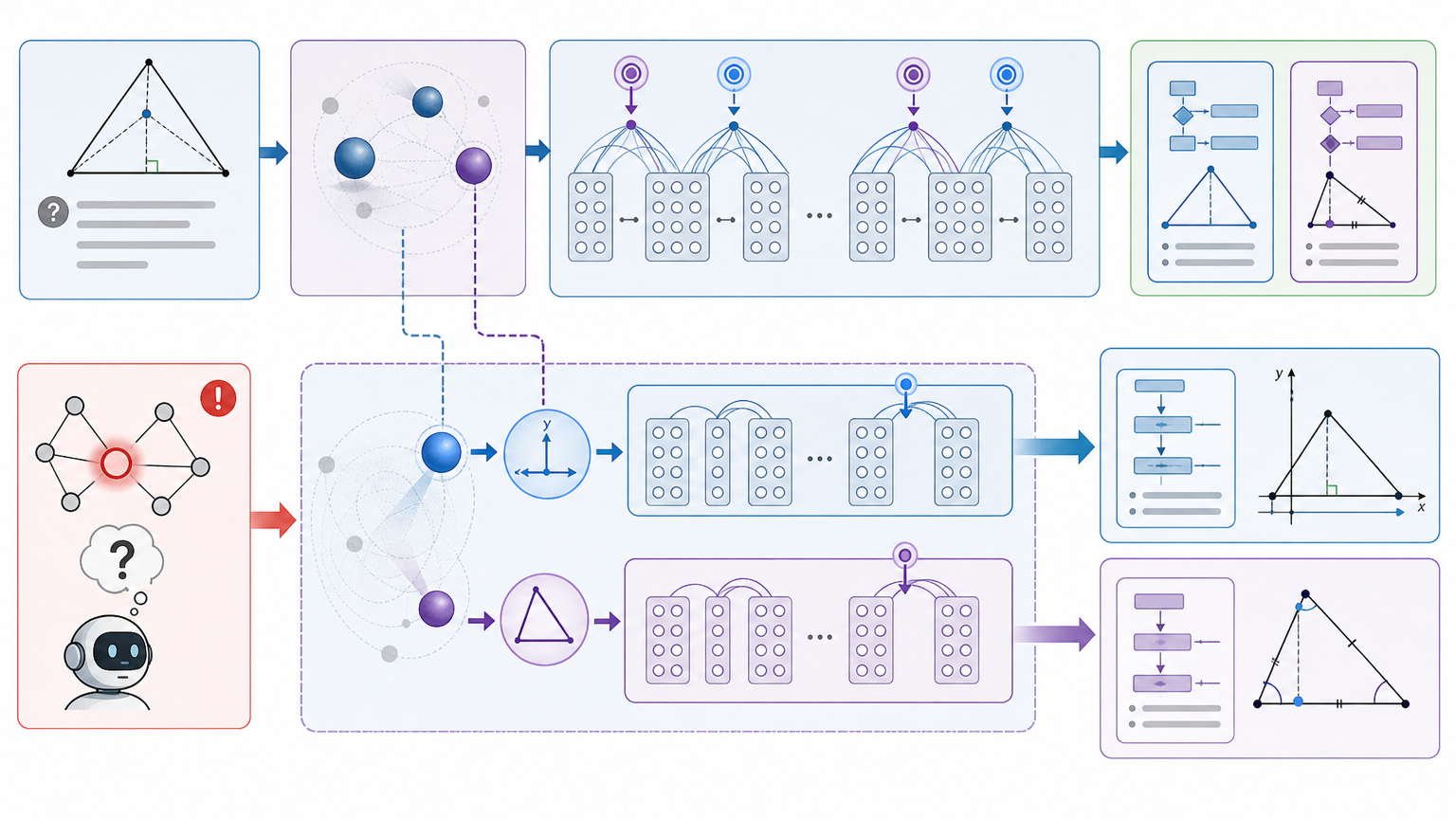
I²B-LPO的破局点,是找到路上真正的“分叉口”——也就是模型的“犹豫时刻”:用熵值(衡量不确定性的指标)定位那些模型拿不准下一步该写什么的节点,比如“到底用代数法还是几何法”“要不要先假设一个变量”。在这些节点上,模型不再只生成一个token,而是通过条件变分自编码器采样多个潜变量,每个潜变量代表一种潜在的解题方向。
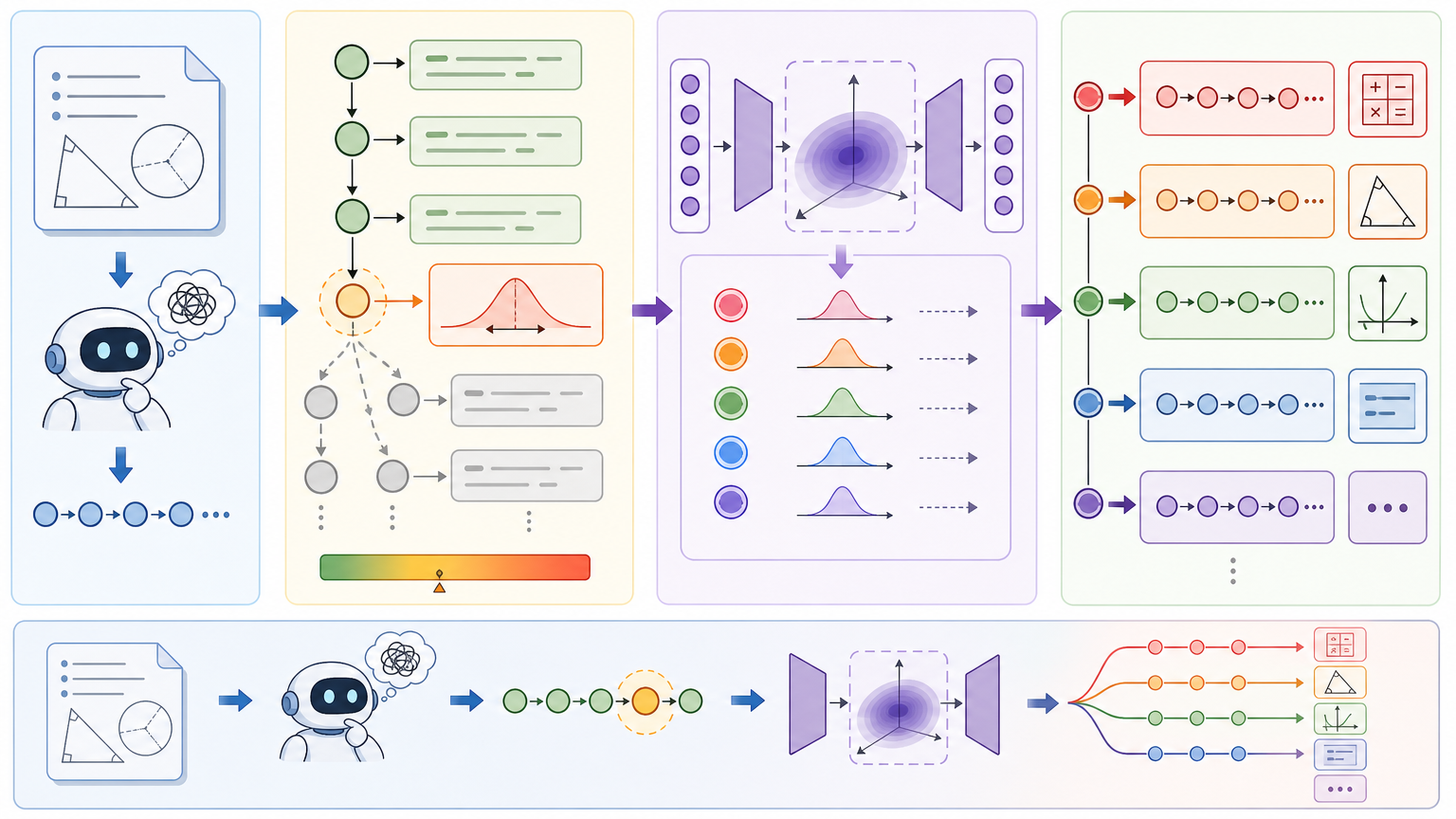
为了让这些新方向能持续影响后续推理,团队设计了伪自注意力机制:把潜变量像“隐形提示”一样注入模型的深层注意力层,而不是只改某个表面词汇。比如在一道几何题的高熵节点,一个潜变量可能引导模型优先考虑坐标系,另一个则引导它用几何定理,最终生成的草稿不再是换汤不换药,而是真正的两种解题思路。
生成一堆分叉的草稿还不够——如果里面全是“让我想想”“需要注意的是”这种废话,反而会干扰模型学习。I²B-LPO的第二个核心,是用信息瓶颈原理当“草稿批改老师”,只留下真正有用的解题路径。
这个“批改老师”的评分逻辑很简单:好的解题草稿,必须既简洁又能帮到最终答案。它用两个互信息指标打分:一是草稿和最终答案的关联度(关联越高分越高),二是草稿和原题的冗余度(冗余越低分越高)。最终得分高的草稿,往往是每一步都直奔答案的短路径;得分低的则逃不出三类问题:要么是铺垫一堆空话的“凑字数型”,要么是反复抄题的“循环型”,要么是思路直接跑偏的“离题型”。

团队在实验中发现,去掉这些低质量草稿后,模型的训练效率明显提升:同样的采样数量下,有效学习信号的浓度提高了30%以上。在AIME2025、MATH-500等数学基准测试中,I²B-LPO不仅把Qwen2.5-7B模型的准确率从54.4%拉到了81.5%,还让解题思路的语义多样性提升了7.4%——这意味着模型终于学会了“用不同方法解同一道题”,而不是“用不同措辞写同一种解法”。
不过,I²B-LPO也并非解决大模型推理问题的万能钥匙。目前它的优势主要集中在数学这类“答案可验证”的领域,换到需要主观判断的开放式问题上,信息瓶颈的筛选标准会失去明确依据。而且,它依赖模型自身生成的熵值来定位分叉点,如果模型本身对某些解题思路完全陌生,根本不会产生“犹豫”,自然也不会去探索。
更关键的是,当前的RLVR训练范式,本质上还是在优化模型“已有知识内的路径选择”,而非真正拓展模型的知识边界。比如面对一道超出预训练范围的前沿数学题,哪怕模型能生成100种解题思路,也可能全是错的——因为它根本没学过相关的定理。这也是未来大模型推理训练需要突破的核心:如何让模型不仅能在已知思路里选最优解,还能主动学习全新的解题逻辑。
从让模型“抄100份答案”,到让它“在关键路口选不同的路”,I²B-LPO的突破,其实是把大模型从“答题机器”往“会思考的学习者”推了一小步。它没有创造新的数学知识,只是让模型更懂得如何利用已有的知识——就像一个学生终于学会了“遇到难题时,试试换个思路”,而不是死啃同一种方法。
未来的AI推理,或许不用追求“无所不知”,但得先学会“灵活思考”。毕竟,真正的解题能力,从来不是记住多少模板,而是能在关键时刻跳出模板。