对抗知识焦虑,从看懂这条开始
App 下载
砸5亿美元造虚拟细胞,要本世纪治愈所有病
数字孪生|AlphaFold2|英伟达|虚拟细胞模型|陈-扎克伯格Biohub|合成生物学|AI产业应用|生命科学|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数字孪生|AlphaFold2|英伟达|虚拟细胞模型|陈-扎克伯格Biohub|合成生物学|AI产业应用|生命科学|人工智能
想象一下:不用在实验室养细胞、不用给小白鼠打针,科学家坐在电脑前,就能精准预测一款新药会不会损伤心肌,或者某个基因突变会不会让细胞癌变。这不是科幻——2026年4月,由陈-扎克伯格倡议创办的Biohub,联合全球6家顶尖科研机构、拉上英伟达,砸下5亿美元启动了一项为期5年的计划:打造能模拟真实细胞所有活动的「虚拟细胞模型」,目标是本世纪末治愈人类所有疾病。为什么一个虚拟细胞,能撑起如此疯狂的野心?
2021年AlphaFold2破解蛋白质结构预测难题时,生命科学家们就盯上了下一个目标:用AI模拟完整的生命单元——细胞。 你可以把虚拟细胞理解成一个「数字孪生细胞」:它不是简单的3D动画,而是用AI整合了基因组、蛋白质组、转录组等几十种生物数据,能像真实细胞一样「生长」「代谢」「对药物做出反应」。比如给它输入一种抗癌药的分子结构,它能立刻算出药物会绑定哪些蛋白、会激活哪些信号通路,甚至能预测会不会误伤正常细胞。
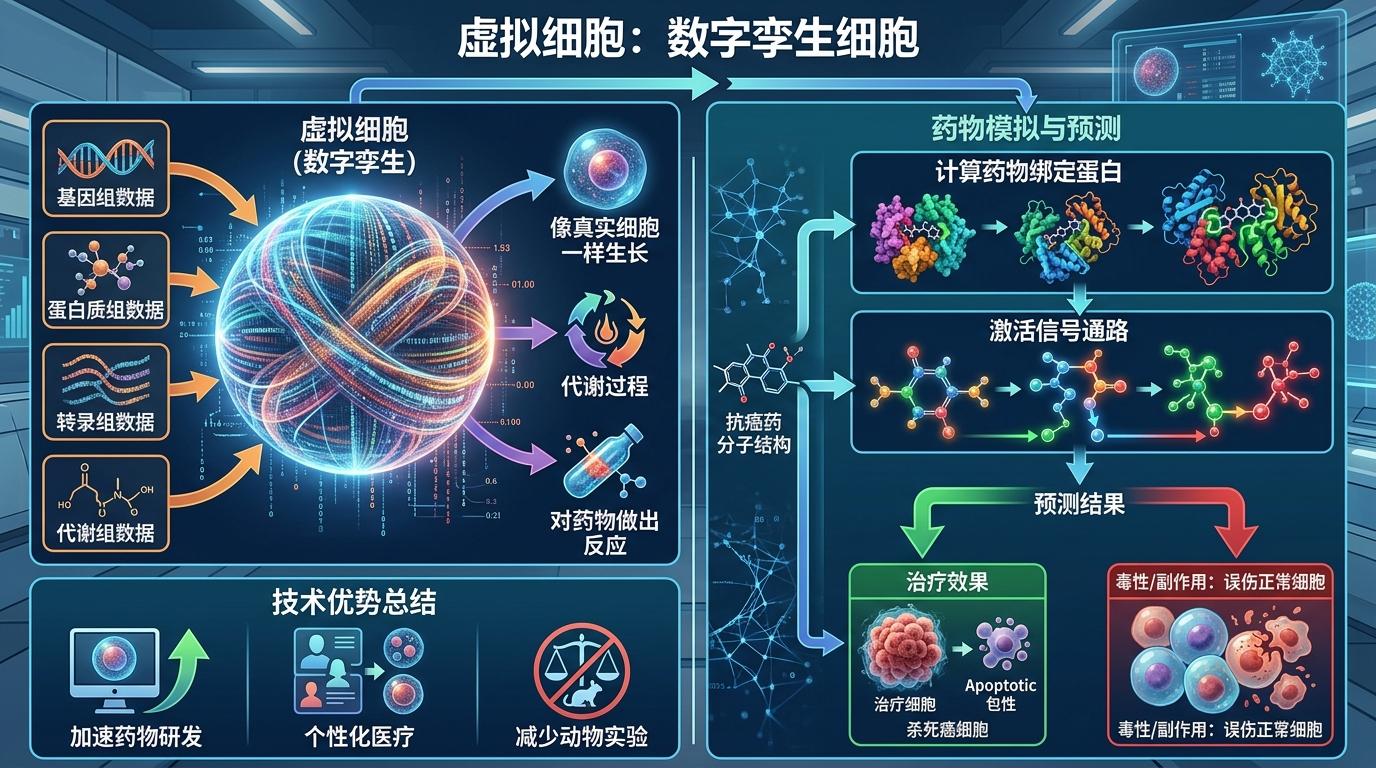
但要造这样一个「数字细胞」,难度比预测蛋白质结构高了几个数量级。单个细胞里就有上万个蛋白、数不清的分子相互作用,要模拟这些过程,需要的数据量是现有生物数据的几十倍——而且得是「多模态」的:从冷冻电镜拍的原子级细胞图像,到实时观测的活细胞动态,再到CRISPR基因编辑后的细胞反应,每一种数据都得精准整合。
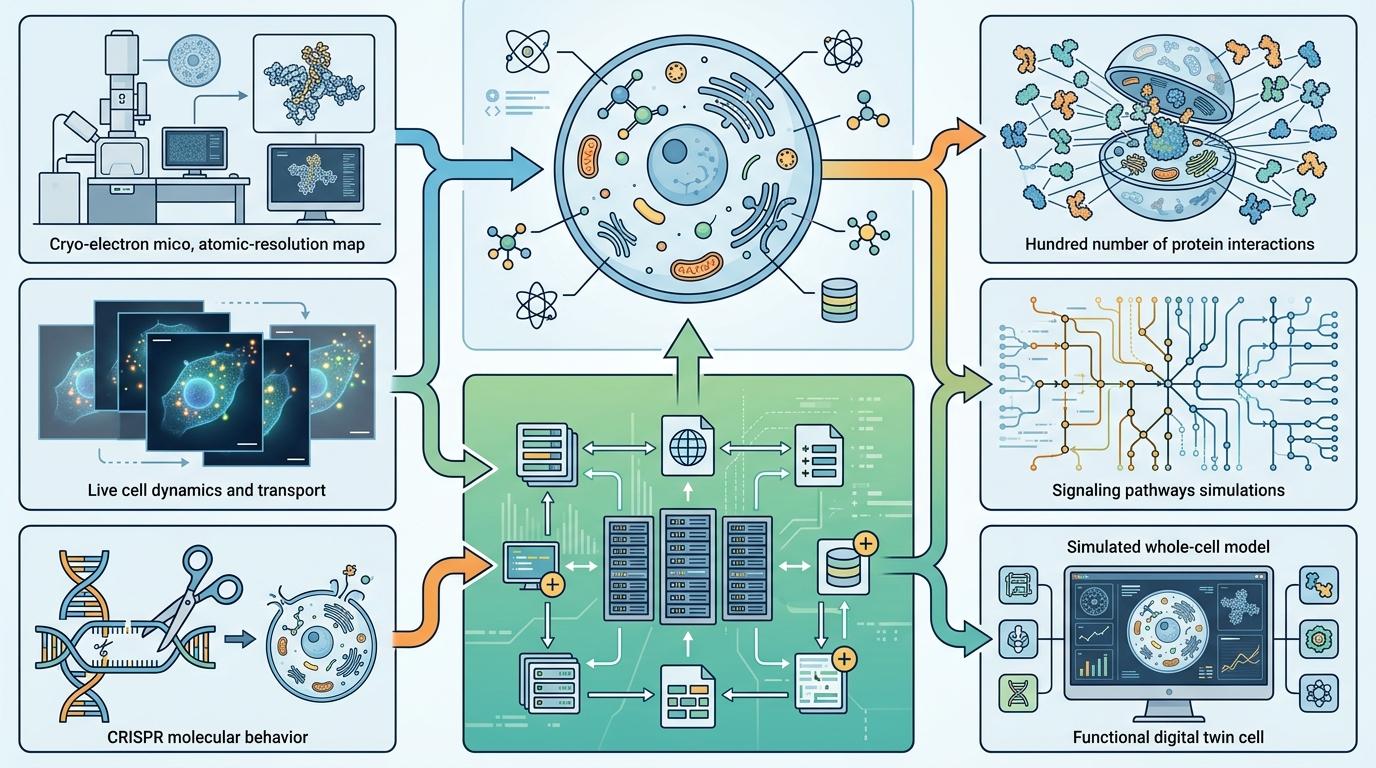
Biohub的5亿美元,4亿花在数据生成,1亿花在全球数据协同——这才是整个计划的核心:先凑齐足够大、足够全的生物数据拼图,再用AI拼出虚拟细胞。 这个数据拼图有多复杂?举个例子:要获取细胞的原子级结构,得用冷冻电子断层扫描,一次只能拍几个细胞;要观察细胞的动态变化,得用能同时盯着数十亿活细胞的显微镜;要知道基因和蛋白的联动关系,得整合转录组、蛋白质组等多组学数据。没有任何一家机构能单独凑齐所有数据,所以Biohub拉来了艾伦研究所、布罗德研究所等6家全球顶尖机构,甚至把人类细胞图谱计划、人类蛋白质图谱计划也拉了进来。 英伟达的角色则是「数据处理器」:用它的超级计算平台处理这些海量异构数据,把原子级图像、基因序列、细胞动态这些完全不同类型的数据,转换成AI能读懂的统一格式。就像把一堆散落在不同语言、不同格式的书籍,翻译成一本AI能快速学习的「细胞百科全书」。
虚拟细胞的前景足够诱人:能把药物研发周期从几年缩到几个月,能让医生给每个患者定制「数字孪生细胞」来测试最优疗法,甚至能彻底替代部分动物实验。但这个「本世纪治愈所有疾病」的野心,背后藏着几个绕不开的坎。 首先是数据的「真实性」:现在的生物数据大多来自细胞系,和真实人体里的细胞差异巨大;临床样本的多模态数据更是稀缺,尤其是罕见病。其次是AI的「黑箱问题」:虚拟细胞能预测细胞反应,但科学家可能不知道它是怎么算出来的——如果它预测错了,没人能找出问题出在哪个数据或算法环节。最后是成本:训练一个能模拟人体细胞的AI模型,需要的计算资源是AlphaFold2的几百倍,不是随便哪家机构都能承担的。 更现实的是,就算真造出了完美的虚拟细胞,也不可能「治愈所有疾病」——毕竟很多疾病不只是细胞层面的问题,还和环境、生活方式、甚至社会因素有关。但不可否认的是,虚拟细胞确实能把生命科学研究从「试错时代」,推进到「精准预测时代」。
当科学家们在电脑里敲出虚拟细胞的第一行代码时,他们其实在做一件和几千年前的祖先一样的事:试图理解生命的本质。只是这次,他们的工具不再是显微镜和培养皿,而是AI和超级计算机。 「用数字复刻生命,用精准替代试错。」这句话或许能概括虚拟细胞的真正价值——它不是要创造新的生命,而是要让人类在面对疾病时,多一份精准,少一点盲目。本世纪末治愈所有疾病可能是个遥远的梦,但至少,我们已经朝着这个方向,迈出了用数据和AI铺就的一步。