对抗知识焦虑,从看懂这条开始
App 下载
北大团队给AI植入生物分类树,识别准确率跳级
蓝锥嘴雀|分层识别|生物分类体系|TARA方法|北京大学彭宇新团队|多模态视觉|人工智能
当你指着一张蓝锥嘴雀的照片问AI,它大概率能说出“这是鸟”,但要它报出“动物界-脊索动物门-鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”的完整分类链,几乎所有多模态大模型都会卡壳。它们能精准认出最细的物种,却搞不清物种背后层层嵌套的类别关系——就像能说出每个零件的名字,却不知道怎么拼成一台完整的机器。直到北京大学彭宇新教授团队的TARA方法出现,这个困扰AI界的分层识别难题,终于有了新的破局思路。
机器看不懂的“分类树”逻辑
你可以把生物分类体系想象成一棵倒置的大树:最顶端是“界”,往下分叉出“门”“纲”“目”,直到最末端的“种”——每一片叶子都是一个独一无二的物种。人类能轻松在这棵树上上下穿梭:看到蓝锥嘴雀,既知道它属于“雀形目”,也能和同属的其他锥嘴雀区分开。但AI不行。
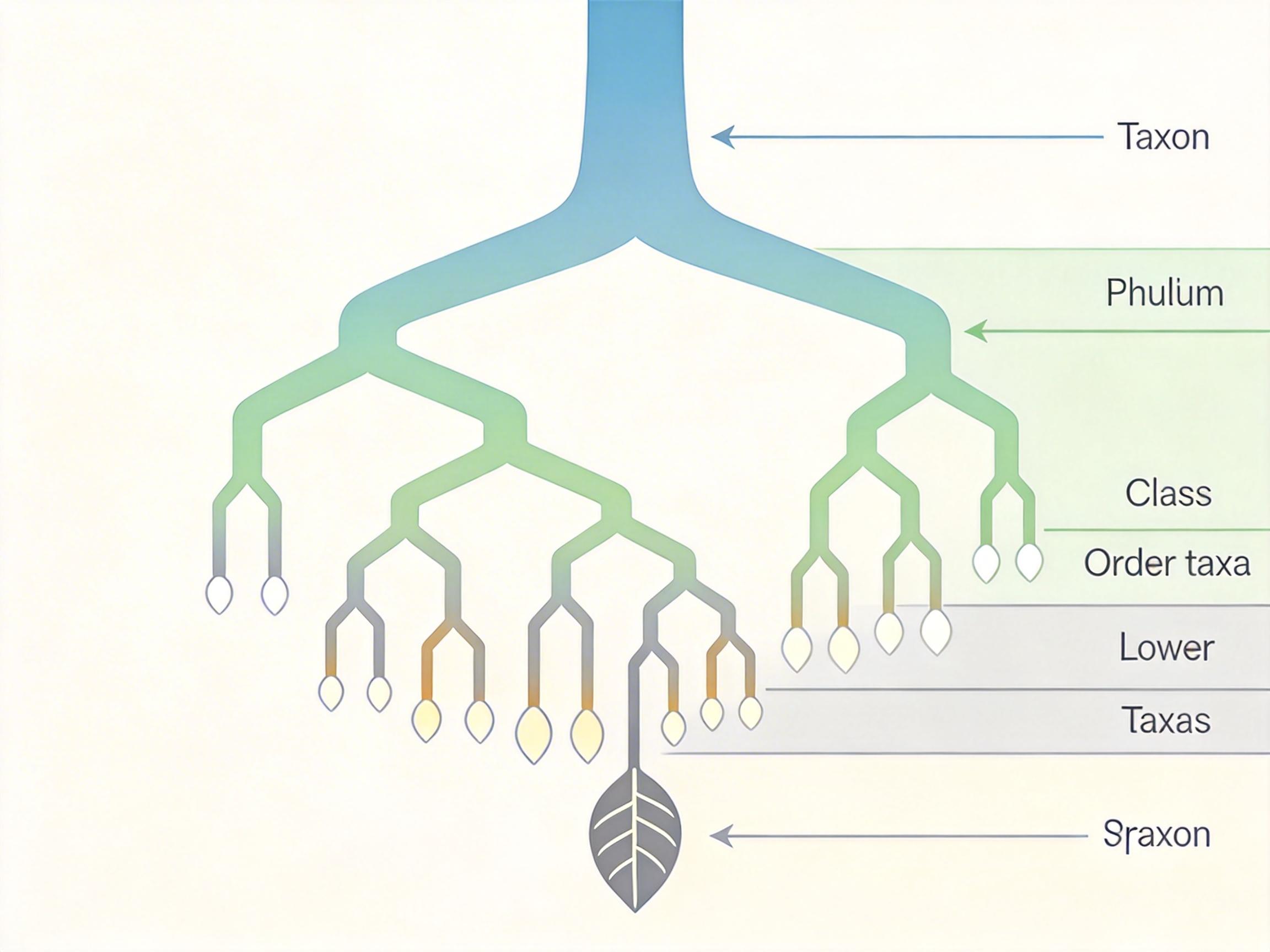
传统多模态大模型的问题在于,它们要么只会盯着最细的叶子,要么只能模糊识别顶端的大树枝,完全没搞懂这棵树的生长逻辑。比如它可能把“裸鼻雀科”归到“鹦鹉目”,完全违背了分类树的父子节点关系;遇到从没见过的稀有物种,更是连它属于哪个“目”都猜不准。这背后藏着三个核心死结:同层相似类别分不清,跨层类别关系理不顺,新类别完全摸不着头脑。
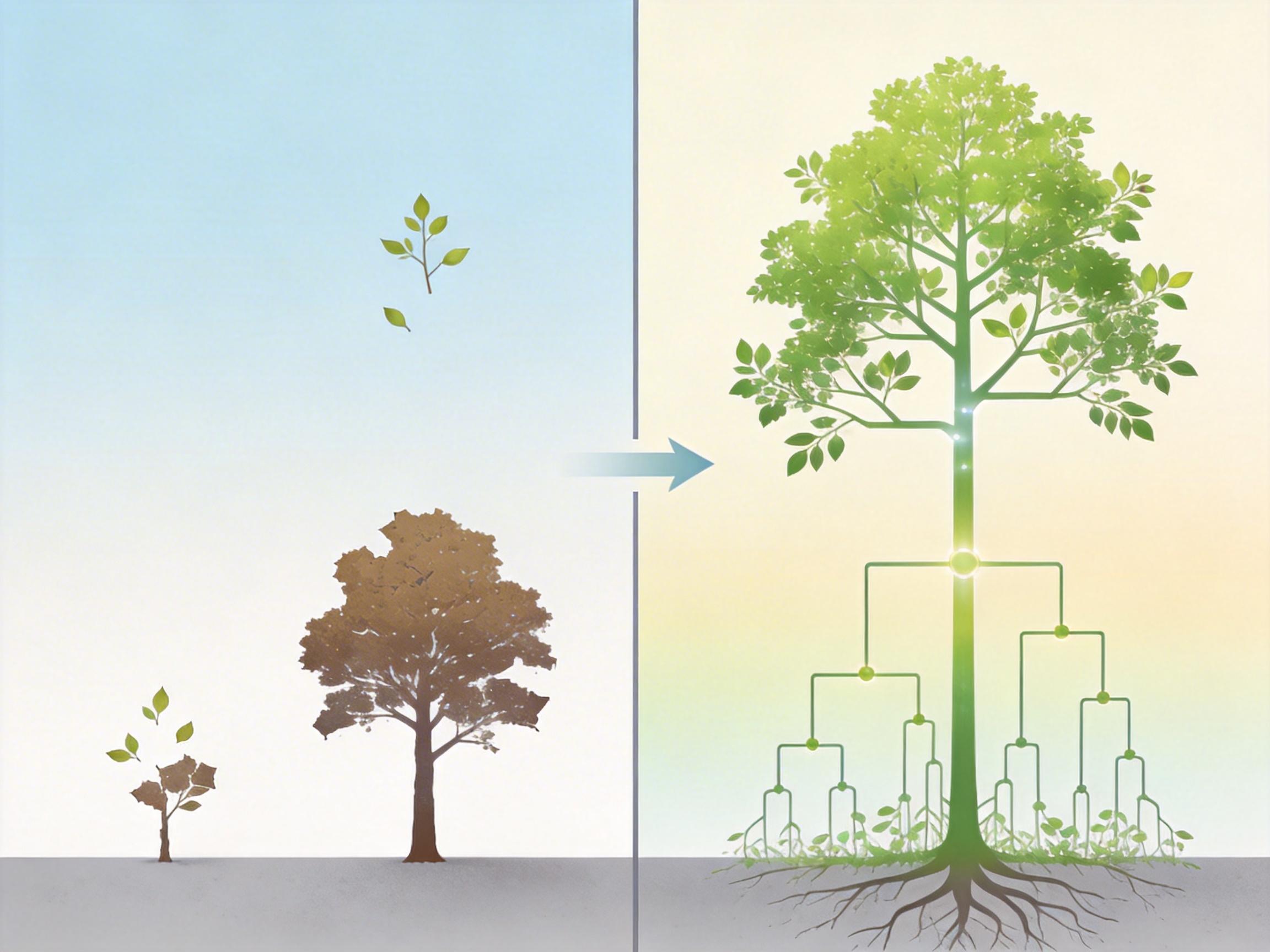
TARA给AI“补课”分类学
彭宇新团队提出的分类感知表征对齐方法(TARA),本质是给AI开了一门生物分类学速成课——但不是让它死记硬背,而是通过“表征对齐”的方式,把分类树的逻辑刻进它的视觉和语言系统里。
第一步是**分层视觉表征对齐**:就像让AI跟着生物领域的“学霸”BioCLIP系列模型抄作业。BioCLIP是专门用层次对比学习训练的生物视觉模型,它的视觉特征天然符合分类树的层级结构。TARA会把多模态大模型的中间层视觉特征,和BioCLIP的特征空间对齐,让AI学会从宏观到微观分层提取视觉信息——比如先认出“鸟的轮廓”,再聚焦“锥状的喙”,最后锁定“蓝色的羽毛”。
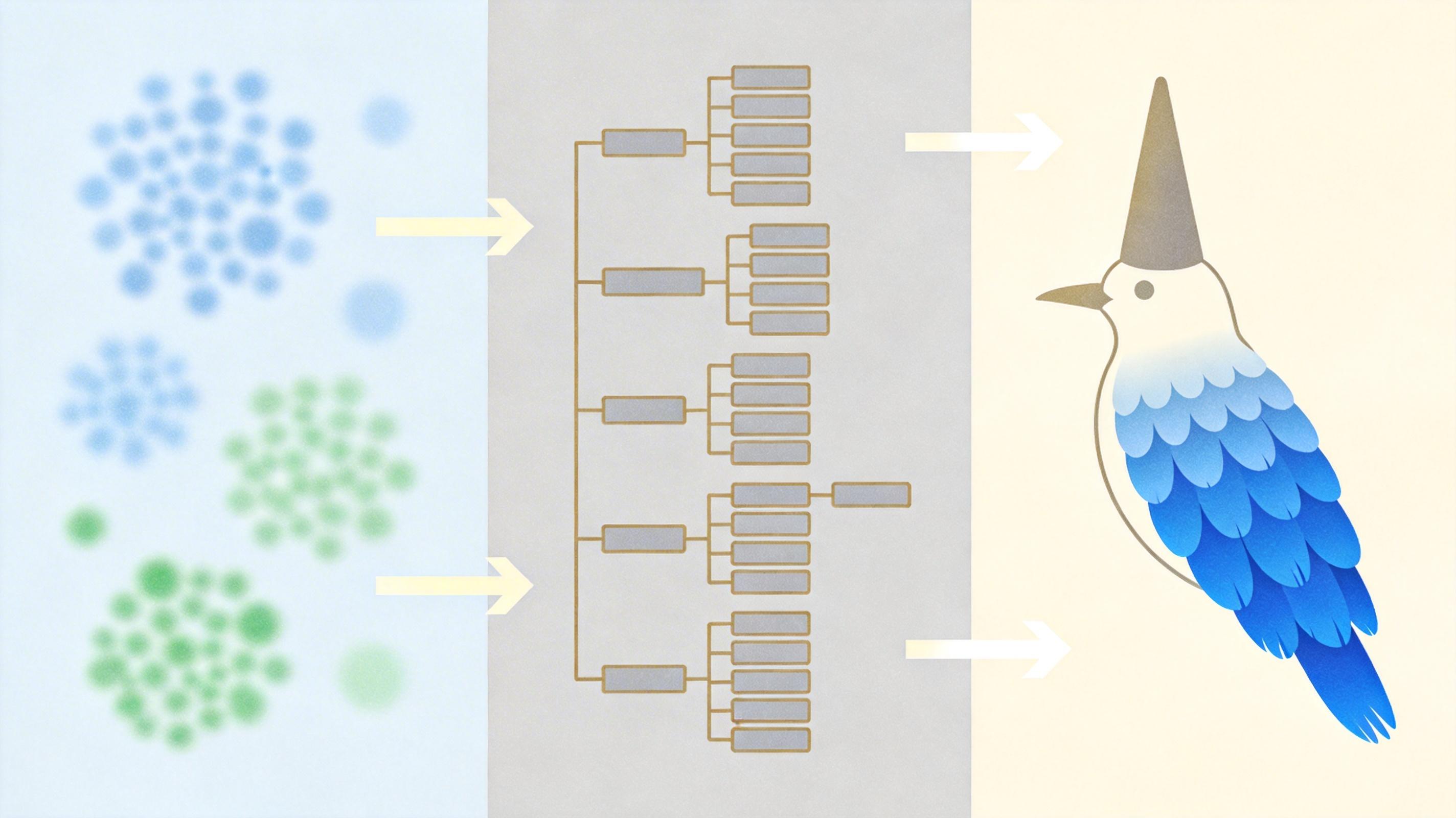
第二步是自由粒度类别表征对齐:AI输出的第一个答案词元,会和BioCLIP编码后的真实类别表征对齐。比如问它“这是什么目”,它输出的“雀形目”就会和BioCLIP里“雀形目”的标准表征比对校准,确保每一层的回答都精准对应分类树的节点。
训练时还用到了“无思考强化微调”策略,只让AI专注输出答案,跳过不必要的推理步骤,既保证了效率,又强化了分类树的逻辑记忆。
不止是认鸟,AI学会了“看门道”
实验数据给出了最直接的证明:在iNaturalist的动植物数据集上,TARA让多模态大模型的分层识别一致性指标提升了数个百分点,细粒度物种识别准确率也明显上涨;更关键的是在TerraIncognita的稀有物种测试集上——那些连训练数据都没有的新物种,TARA能依托分类树知识,准确推断出它们的上层分类,比如认出从未见过的鸟类属于“雀形目”。
当然,TARA目前也有局限:它现在主要针对生物分类树,要推广到产品分类、医学影像分级等其他领域的层级结构,还需要适配不同的领域基础模型;而且它依赖BioCLIP这类已经具备层级知识的模型,要是没有现成的领域“学霸”,TARA的效果也会打折扣。但不可否认的是,它给AI注入层次知识的思路,已经打开了通用视觉理解的新大门。
从只会“认东西”到能“懂逻辑”,TARA的突破,本质上是让AI从“看图片”升级到“理解世界的结构”。我们总说要让AI更像人,而人类认知世界的方式,从来都不是孤立地识别一个个事物,而是在层层嵌套的知识网络里,给每个事物找到精准的位置。
给AI植入知识结构,比喂它更多数据更重要。 未来的AI或许不用记住所有物种的样子,但只要掌握了分类树的逻辑,就能像生物学家一样,从一片羽毛、一根骨头出发,一步步推理出它在自然界中的位置——这才是真正的“通用视觉理解”。