对抗知识焦虑,从看懂这条开始
App 下载
老视频人脸修复:快且不“变脸”的新解法
上海交大与美团团队|时空导航仪|扩散模型|视频人脸修复|DVFace|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载上海交大与美团团队|时空导航仪|扩散模型|视频人脸修复|DVFace|多模态视觉|人工智能
当你点开手机里那段十年前的家庭录像,屏幕上爸妈的脸模糊成一团色块,嘴角的笑纹混着噪点,连眨眼都像在跳帧。你试过用AI修复,要么等十分钟出一帧,要么修复后的脸每三秒就换个“版本”——明明是同一个人,却像剧组换了三个替身。这不是个别软件的问题,而是视频人脸修复的“不可能三角”:清晰、连贯、快速,三者似乎永远无法同时实现。直到上海交大与美团的团队拿出了DVFace。
过去的视频修复,要么用多步扩散模型慢慢迭代,像用砂纸反复打磨一块木头,虽然能磨光滑,但要耗上几十倍时间;要么单帧处理,结果就是帧与帧之间“各自为政”,人脸跟着抽风。DVFace的思路是:既然扩散模型擅长生成细节,那就在它的生成路径上装个“导航仪”,让它一步就走到正确终点。
这个导航仪就是**时空双码本先验**。你可以把它理解成两本厚厚的“人脸百科全书”:一本是空间码本,收录了所有高清人脸的细节词条——比如“笑起来时眼角的细纹走向”“高鼻梁的光影角度”;另一本是时间码本,记的是人脸动态的规律——比如“从抿嘴到张嘴的肌肉运动轨迹”“眨眼时眼皮的下落速度”。
当模糊视频输入时,模型会先把每一帧拆成细碎的特征碎片,去空间码本里找最匹配的高清词条,拼出单帧的清晰细节;同时,它会把连续几帧的动作串联起来,去时间码本里查对应的动态规律,确保下一秒的脸和上一秒的动作逻辑连贯。
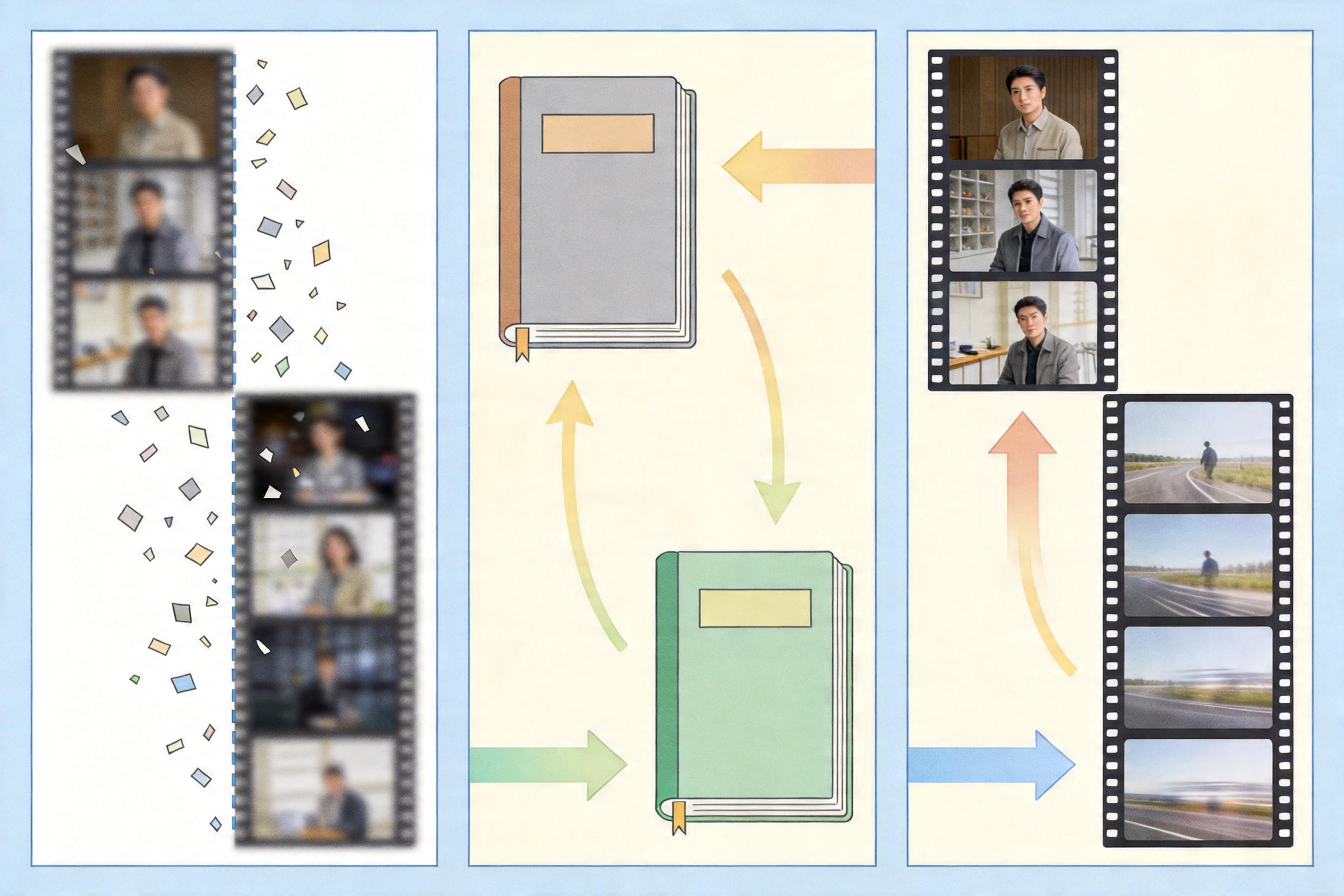
传统扩散模型要从纯噪声开始,一步步“去噪”生成清晰图像,就像从地下室爬楼梯到顶楼。DVFace直接把模糊视频定位成“楼梯的中间层”——它通过预训练的变分自编码器,把低清视频转换成扩散过程中的中间状态,然后让模型只走一步,就从中间层跨到顶楼。
这一步的关键,是**非对称融合机制**。时间码本的动态规律像总导演,给整个视频定下“全局基调”——它会生成一组参数,给扩散模型的每一层特征做统一的缩放和偏移,确保所有帧都在同一个动态频道上;而空间码本的细节则像化妆师,要先经过导演的审核:用时间码本的动态信息当“查询词”,筛选出那些和当前动作匹配的细节,比如“张嘴时的唇纹”而不是“闭嘴时的唇纹”,再把这些细节补到视频里。
实验数据最能说明问题:在VFHQ-Test等标准数据集上,DVFace的PSNR(画质保真度)比传统多步扩散模型高0.23dB,而推理速度是后者的30倍;在真实世界的老旧视频上,它修复后的人脸连续帧像素线平滑无断裂,而其他方法的线条满是锯齿状的跳变。

DVFace的突破很亮眼,但也藏着容易被忽视的边界。它的双码本是用海量高清人脸视频训练出来的,这意味着它对训练数据之外的人脸类型,比如特殊妆容、极端角度的侧脸,修复效果会打折扣——就像百科全书里没有的词条,它只能靠猜测补全。
更关键的是,它的“一步到位”依赖预训练的扩散模型,训练阶段依然需要庞大的计算资源,普通个人电脑很难复现整个训练流程。而且面对极端模糊的视频——比如分辨率只有100x100的老录像,它也会出现“脑补过度”的问题,把不存在的细节硬加到脸上。
不过这些局限反而指向了更有价值的方向:如果能给码本加上“动态更新”功能,让它能快速学习新的人脸类型;或者把预训练模型进一步轻量化,让它能在手机上运行,那它的应用场景会从专业影视后期,真正走进普通人的手机相册。
当我们为老视频里清晰重现的亲人笑容感动时,其实是在见证AI技术的一个转向:从追求“更快、更强”的绝对性能,转向解决“好用、能用”的具体问题。DVFace没有发明新的扩散模型,也没有创造新的码本技术,它只是把已有的工具,用更贴合用户需求的方式组合了起来。
技术的价值,从来都不是突破极限,而是填补缺口。 就像DVFace填补的,是我们对旧时光的清晰念想——那些模糊的、晃动的、带着噪点的瞬间,终于能以稳定的、温暖的模样,重新回到我们眼前。