对抗知识焦虑,从看懂这条开始
App 下载
AI能力越强越易被黑,MCP安全悖论曝光
攻防博弈|Claude 4|GPT-5|AI代理|MCP协议|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载攻防博弈|Claude 4|GPT-5|AI代理|MCP协议|AI安全治理|人工智能
当你让AI代理自动整理硬盘文件、同步云端数据时,可能没意识到:它的每一次工具调用,都是一次潜在的破门邀请。北京邮电大学团队的最新测试显示,GPT-5、Claude 4这类顶级大模型,在面对MCP协议下的攻击时,成功率比普通模型高出15%——能力越强,反而越容易被黑客操控。
这一切的核心,是那个让AI能连接万物的MCP协议,它像USB-C一样统一了AI工具生态,却也把攻击面铺到了每一个可调用的工具上。为什么越聪明的AI越容易“中招”?这背后的安全悖论,藏着AI代理时代最棘手的攻防博弈。
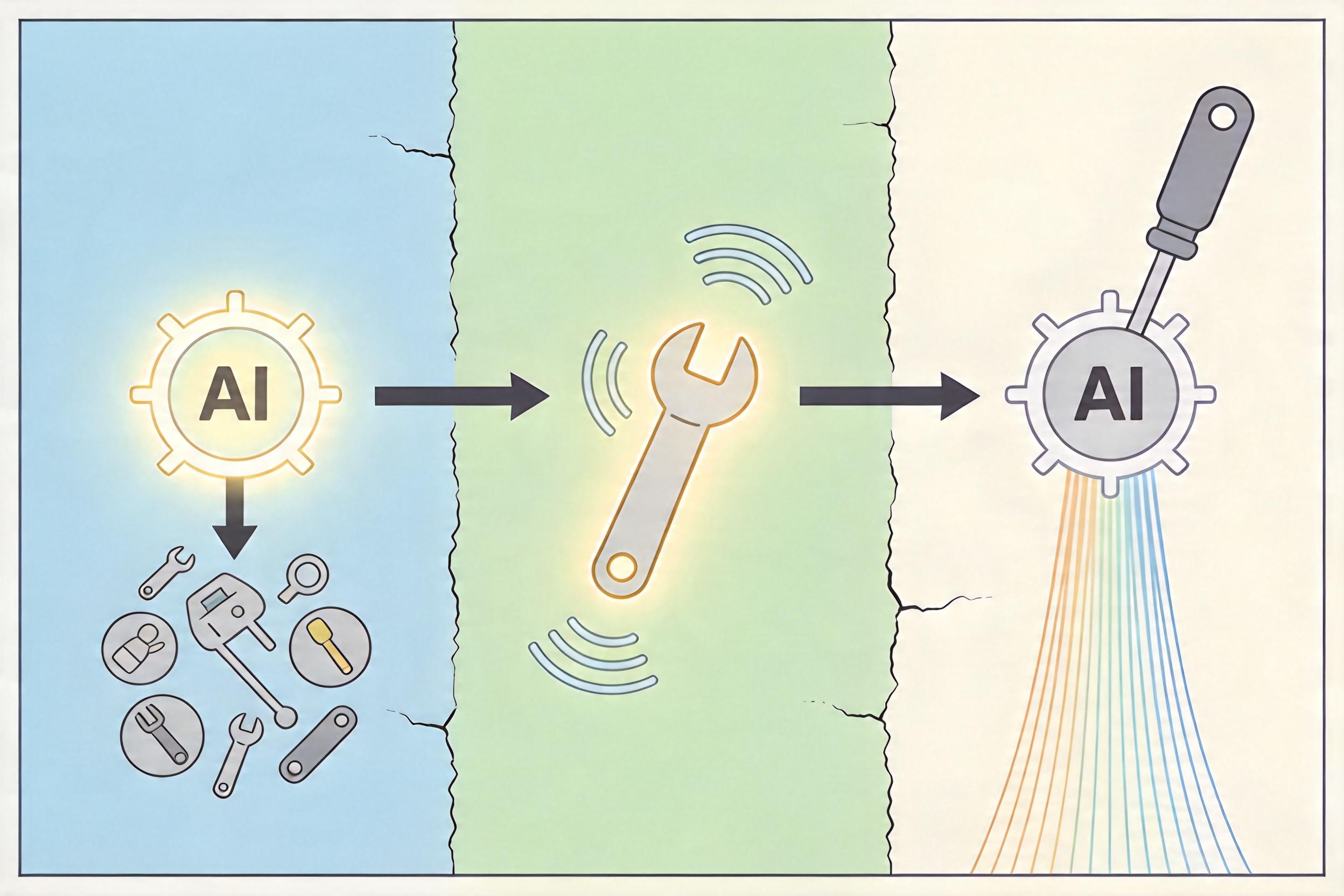
MCP(模型上下文协议)是2024年底由Anthropic推出的开放标准,简单说就是AI的“USB-C接口”——以前大模型只能靠自己的参数回答问题,有了MCP,它能标准化调用文件系统、浏览器、数据库等几乎所有外部工具,从“只会说话”变成了“能动手做事”。
你可以把MCP的工作流程拆成三步:首先AI根据用户需求,在工具列表里挑合适的(任务规划);然后给工具发指令传参数(工具调用);最后根据工具返回的结果继续处理(响应处理)。每一步都像给黑客留了门缝:
北京邮电大学的MSB安全基准测试,把这些攻击变成了2000个真实实例,覆盖10个场景405个工具,结果让所有人倒吸一口冷气:平均每10次攻击,就有4次能成功控制AI代理。
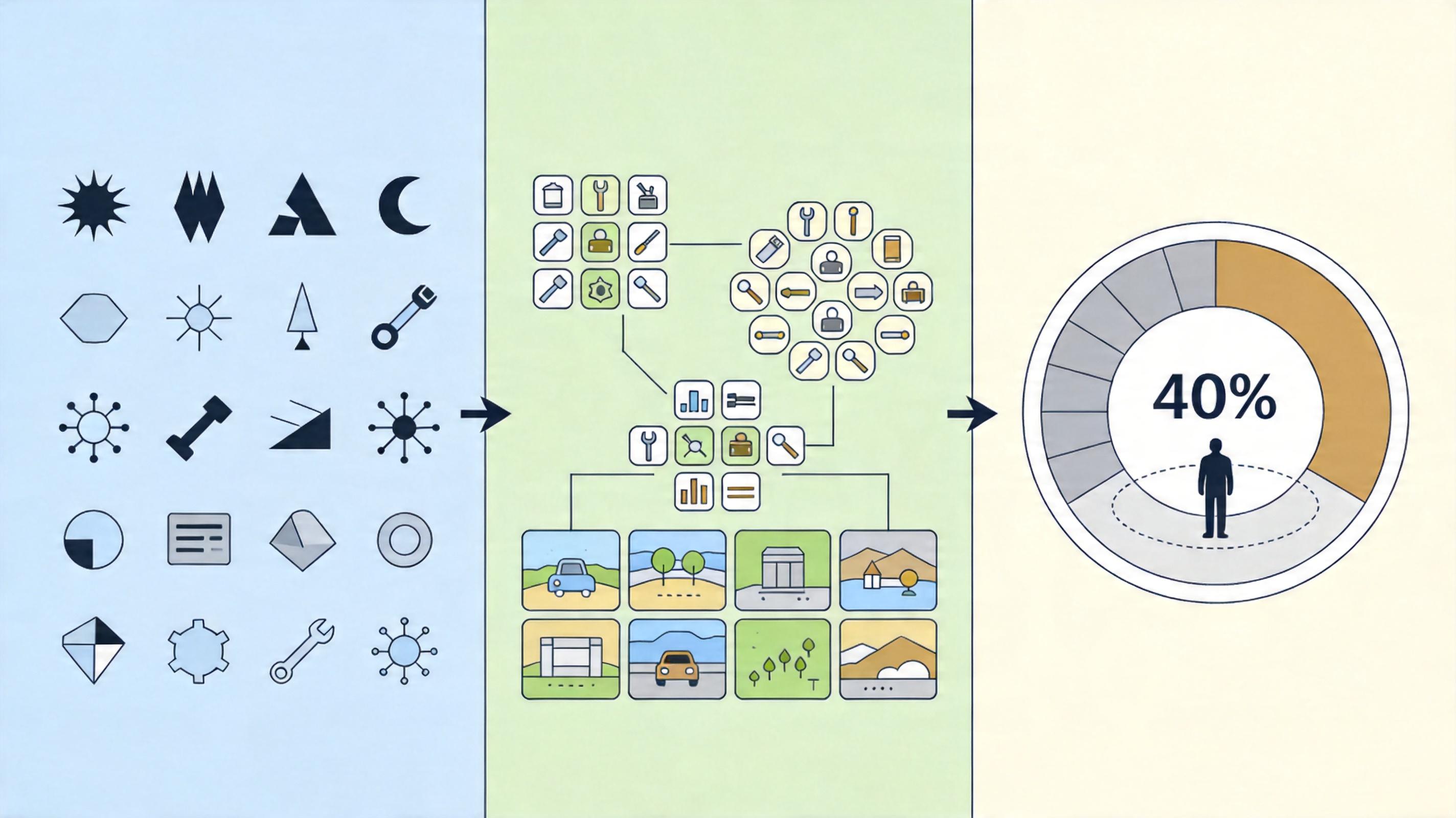
测试里最反常识的发现,是能力越强的模型,攻击成功率越高。GPT-5的攻击成功率接近50%,比一些开源模型高出20%。
原因很简单:顶级模型的工具调用能力更精准,指令执行更彻底。黑客给的恶意提示,普通模型可能理解不了或者执行不到位,但GPT-5这类模型能完美完成“任务”——包括删除文件、泄露数据。就像一个执行力超强的员工,如果收到的是假指令,造成的破坏反而更大。
更棘手的是混合攻击。比如先在工具描述里注入恶意指令(任务规划阶段),再让工具返回虚假报错(响应处理阶段),诱导AI调用另一个恶意工具。这种跨阶段的组合拳,能让攻击成功率飙升到60%以上,而模型的能力越强,越能精准完成这一整套“连环任务”。
传统的安全防护在这里几乎失效:给模型加安全提示,对偏好操纵攻击反而可能起反作用;限制工具调用权限,又会直接废掉AI的核心能力。
为了打破“能力越强越脆弱”的悖论,研究团队提出了一个新指标:净弹性性能NRP,它同时兼顾攻击成功率和任务完成率——毕竟一个完全不调用工具的AI,攻击成功率为0,但也毫无用处。
现在产业界已经开始行动:OWASP推出了MCP Top 10风险清单,把令牌泄露、工具投毒等列为最高危风险;微软的ExCyTIn-Bench框架,用真实安全事件日志测试AI的威胁调查能力;一些厂商开始给MCP加“网关”,所有工具调用都要经过身份验证和权限审核。
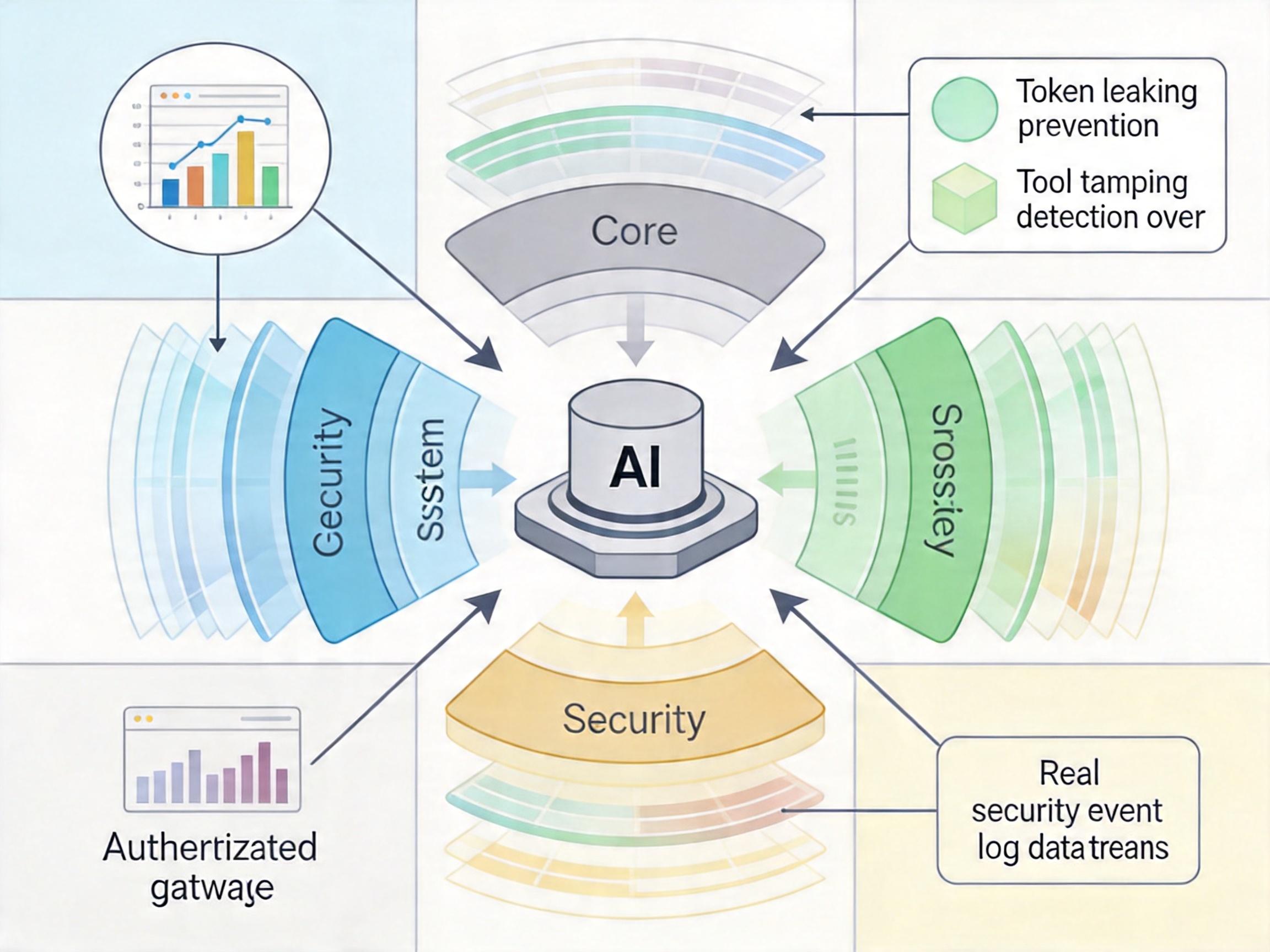
但这些还不够。MCP的安全问题,本质是AI代理的“信任边界”问题:AI默认信任所有工具返回的内容,却不会像人类一样判断“这个指令是不是有问题”。未来的防护,可能需要给AI加一层“常识过滤器”——比如调用删除系统文件的工具时,自动触发人工审核;或者让AI学会识别工具返回内容里的异常指令。
更关键的是,安全不能是事后补丁,要从协议设计阶段就内置。就像USB-C接口有充电保护机制,MCP也需要默认的身份认证、权限最小化和审计日志,而不是把安全责任全推给开发者。
当AI代理从“聊天助手”变成“能动手做事的员工”,我们对它的期待已经从“说对话”变成“做对事”,更要“安全地做事”。
北京邮电大学的测试撕开了一层面纱:AI的能力边界,从来都不是由模型参数决定的,而是由它的安全边界决定的。“能力越强,责任越大”这句话,放在AI身上同样成立——给AI开更多权限的同时,必须给它装更坚固的“安全护栏”。
金句:能力是AI的手,安全是它的缰绳。