对抗知识焦虑,从看懂这条开始
App 下载
无人车地下认路:快和准不再是二选一
布里斯托大学|厦门大学|LEADER方法|激光雷达点云|地下车库|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载布里斯托大学|厦门大学|LEADER方法|激光雷达点云|地下车库|自动驾驶|人工智能
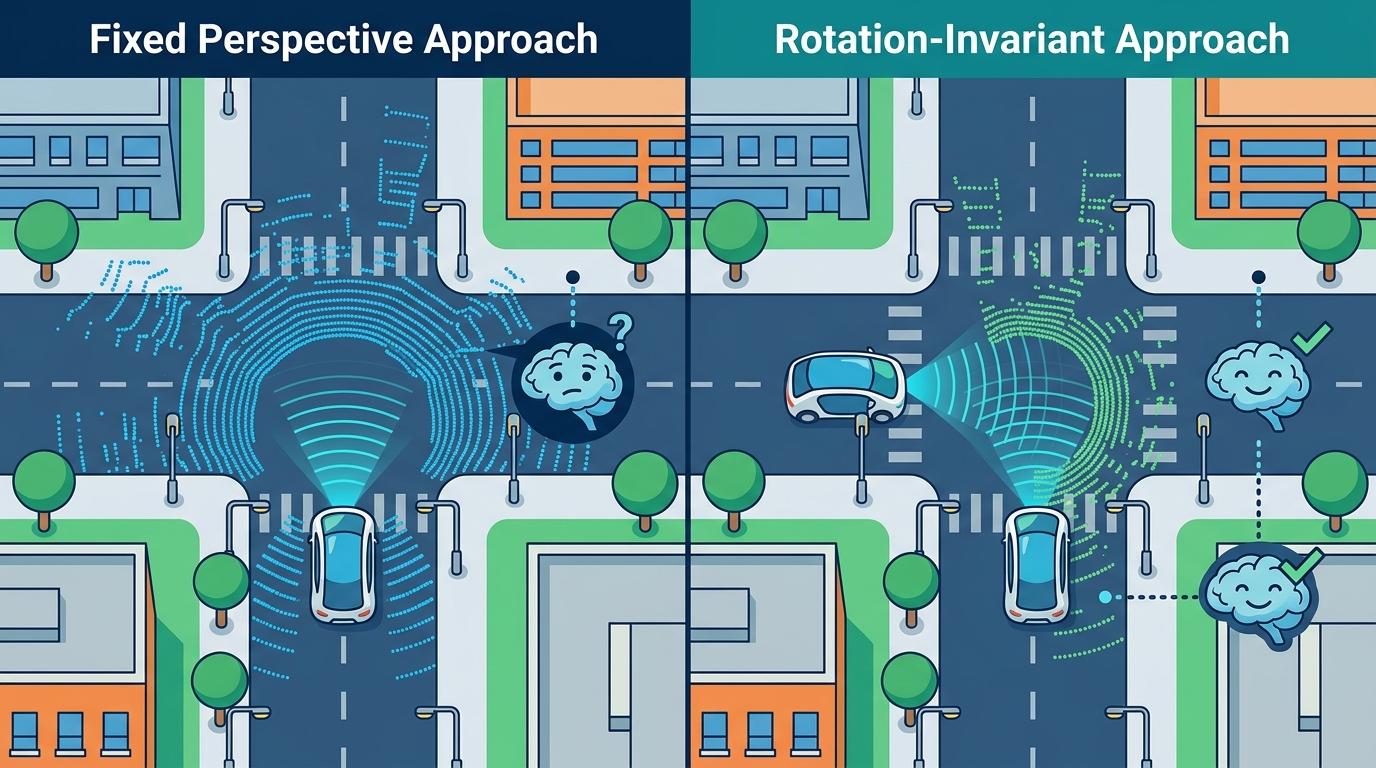
想象你蒙眼转三圈,睁眼面对一片一模一样的白墙走廊——要立刻说出自己站在哪、面朝哪,这就是地下车库里无人车的日常困境。GPS信号在这里彻底失效,只能靠激光雷达扫出的点云「认路」。过去十年,这件事一直是道两难选择题:要么像查字典似的「检索-配准」,精度能到分米级,但车库越大越卡;要么让AI直接猜位置,十毫秒就能出结果,转个弯就可能飘出去十米。直到2026年5月,厦门大学和布里斯托大学的团队把这道选择题做成了证明题:他们的LEADER方法,既能十毫秒「睁眼即定位」,精度还比传统方法更高。
无人车转个弯就迷路,核心问题出在点云的「视角依赖」——车头朝东和朝西扫出的点云,在AI眼里完全是两回事。传统的神经网络方法就像只认固定角度的照片,换个方向就认不出同款场景。
LEADER的解法是给点云做个「柱面投影」:把三维点云像卷画卷似的贴到圆柱侧面,这样不管车头转多少度,点云的相对结构都保持不变。配合上循环稀疏卷积,圆柱首尾的特征能自然衔接,不会出现「转一圈后画面断裂」的问题。就像你把世界地图印在地球仪上,不管转到哪个经度,相邻区域的连接都是连续的。
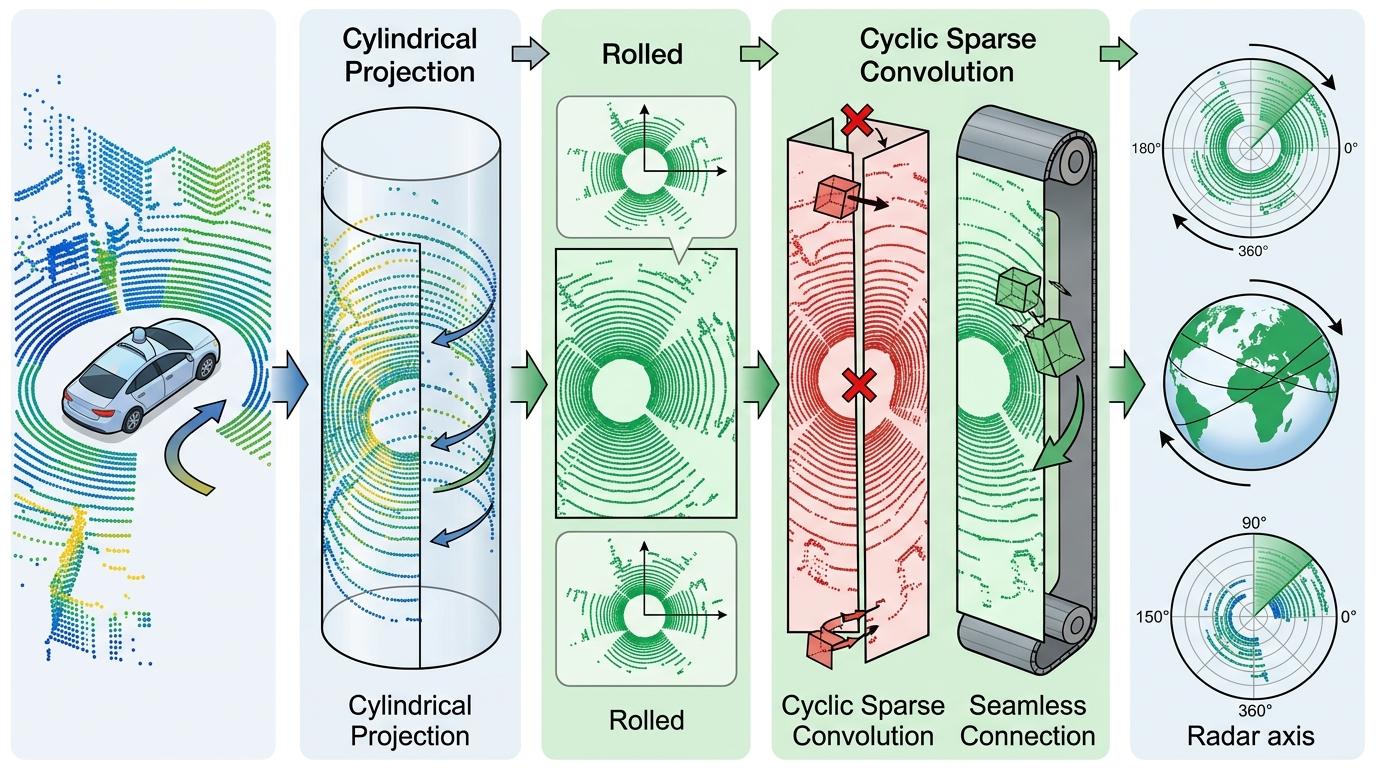
研究团队还加了个小细节:先通过地面点把点云校正到水平,相当于给点云「调平」,这样哪怕车辆上下坡、轻微颠簸,也不会影响定位精度。这套组合拳下来,无人车哪怕连续转三个U型弯,定位误差也不会超过0.5米。
解决了旋转问题,还有另一个坑:地下车库里满是「坏点」——光滑墙面的反射噪声、重复的立柱结构、路过车辆的动态点云,这些点就像试卷上的干扰项,会把AI的判断带偏。
LEADER的核心发明是TRR损失函数——简单说就是让模型自己学会「挑重点」。训练时,模型不仅要预测每个点的世界坐标,还要顺便给这个点打个「置信分」:好预测的点(比如墙角、地面标线)分高,难预测的点(比如光滑墙面)分低。如果某个点连续多次预测不准,模型就会自动降低它的训练权重,相当于告诉自己「这个点不重要,不用费力气记」。
到了实际定位时,模型只会选置信分前20%的点来计算位姿,直接把那些「捣乱」的坏点排除在外。在NCLT数据集的测试里,这套机制让高精度点的比例翻了一倍,定位失败率从传统方法的7%降到了0.28%——相当于每357次定位才会出错一次。
过去大家总说「鱼与熊掌不可兼得」,但LEADER用数据把这句话推翻了。
在NCLT数据集上,传统神经网络方法的平均定位误差是1.19米到1.51米,LEADER把这个数字压到了0.31米——相当于从「能看清哪栋楼」到「能看清哪扇窗」的精度提升。和传统「检索-配准」方法比,LEADER的平均误差低了0.07米,失败率更是只有前者的1/25。
更关键的是速度:LEADER单帧处理时间只有47毫秒,每秒能处理21帧点云,完全满足无人车实时定位的需求。而传统「检索-配准」方法,当地图数据超过100GB时,检索一次就要花上几百毫秒,车库越大越慢。LEADER不需要存储庞大的点云地图,所有计算都在端侧完成,相当于把一本厚重的字典压缩成了一张便携的思维导图。
LEADER的突破,本质上不是做了加法,而是做了减法——减去了对冗余数据的依赖,减去了对完美输入的苛求,把有限的计算资源集中在真正有用的信息上。这和我们常说的「断舍离」异曲同工:与其试图记住所有细节,不如学会抓住核心。
在AI模型越做越大的今天,这种「有所取舍」的思路反而更有价值。毕竟,真正的智能从来不是拥有无限的记忆,而是懂得在复杂世界里,快速找到那个最关键的锚点。
好的技术,都懂得有所取舍。