对抗知识焦虑,从看懂这条开始
App 下载
3D视觉不再只画样子,要懂物理和空间了
物理约束|空间结构理解|自监督学习|3D重建|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载物理约束|空间结构理解|自监督学习|3D重建|多模态视觉|人工智能
你有没有过这种体验:刷到AI生成的3D图片,乍看逼真得离谱,可盯着看两秒就觉得不对劲——沙发的扶手在某个角度里“穿”过了靠背,杯子的阴影和光源方向完全相反,虚拟人走路时膝盖弯成了违背骨骼结构的角度。这些“一眼假”的破绽,本质上是AI只学会了模仿2D图像的“皮”,没搞懂真实3D世界的“骨”。而在2026年的CVPR大会上,一批研究正在把AI从“画皮”的误区里拉出来:它们要求AI不仅能生成好看的画面,还要理解物体的空间结构、运动规律,甚至得懂物理。
过去训练3D模型,得先给AI喂大量标注好的3D数据——比如告诉它“这是一个杯子的侧面”“这是沙发的深度图”,成本高得离谱。CMU、Adobe和哈佛团队提出的E-RayZer,直接跳过了人工标注这一步:给它喂同一场景的多张普通照片,它会自动估算相机角度,用一个个3D高斯点拼出场景的立体结构,再把这些结构“渲染”成新视角的图像,最后通过和真实照片的差异自己修正错误。 你可以把这个过程想象成:给AI看从客厅门、沙发旁、窗户边拍的三张照片,它自己琢磨出客厅的布局,然后画出站在电视前能看到的画面。如果画出来的电视位置和真实照片对不上,它就调整自己对空间结构的理解。
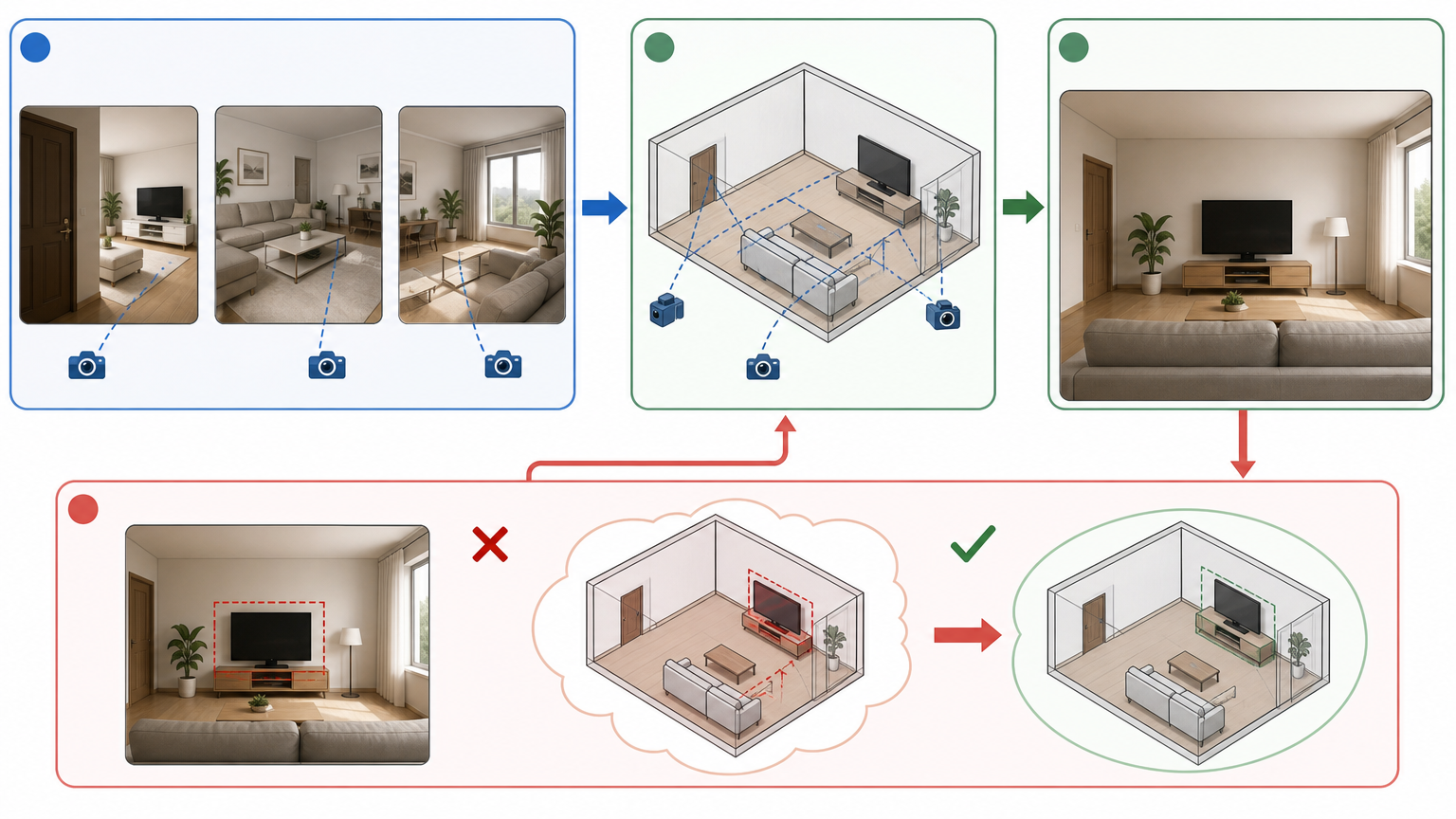
这种“自监督3D重建”的核心,是逼AI学懂几何关系,而不是死记硬背图像的像素规律。实验显示,用这种方法训练的模型,在相机位姿估计、深度预测上的表现,比只学图像相似性的模型提升了近20%。更重要的是,它让AI第一次不用依赖人类标注,就能自己“悟”出3D世界的底层逻辑。
传统3D建模像搭积木,得先把物体的每个面都建出来,才能渲染新视角的画面——这就导致渲染一张图要等好几秒,根本没法实时用。牛津大学和Meta团队的LagerNVS,干脆跳过了“搭积木”的步骤:它先让AI从照片里提取带有3D信息的特征,比如“这个地方是桌子的边缘,从任何角度看都应该是直的”“这个曲面是杯子的弧度,不同视角下的曲率要一致”,然后直接用这些特征生成新视角的图像。 你可以把它理解成:AI记住的不是桌子的每个面,而是“桌子是有四条腿、平桌面的立体物”这个“3D感知”,不管从哪个角度看,它都能根据这个感知画出符合逻辑的桌子。在单张H100显卡上,它能以30帧以上的速度实时渲染新视角画面,比传统NeRF方法快了几十倍。 但这一方法也有局限:它的3D逻辑是隐含在特征里的,不像显式重建那样能直接编辑物体的结构。比如你想把桌子的腿改粗,显式重建模型能直接调整3D结构,而LagerNVS得重新生成整个画面,灵活性上打了折扣。
如果说前面的研究解决了“物体长什么样”的问题,那北京理工大学团队的PhysGM,就是要解决“物体怎么动”的问题——而且得符合物理规律。过去要让AI生成动态的3D物体,得先建好静态模型,再手动设置物理参数,比如“这个气球是橡胶做的,捏一下会变形”,最后再模拟运动,整个过程要花几个小时。 PhysGM则是“一步到位”:给它一张气球的照片,它不仅能重建出气球的3D形状,还能直接预测出气球的材质、弹性等物理属性,然后用物理模拟算法生成气球被风吹动、被手挤压的动态画面,整个过程只需要1分钟。它甚至能通过人类偏好数据微调模型,让生成的动态更符合真实观感——比如气球被戳破时,碎片会向四周飞溅,而不是凭空消失。
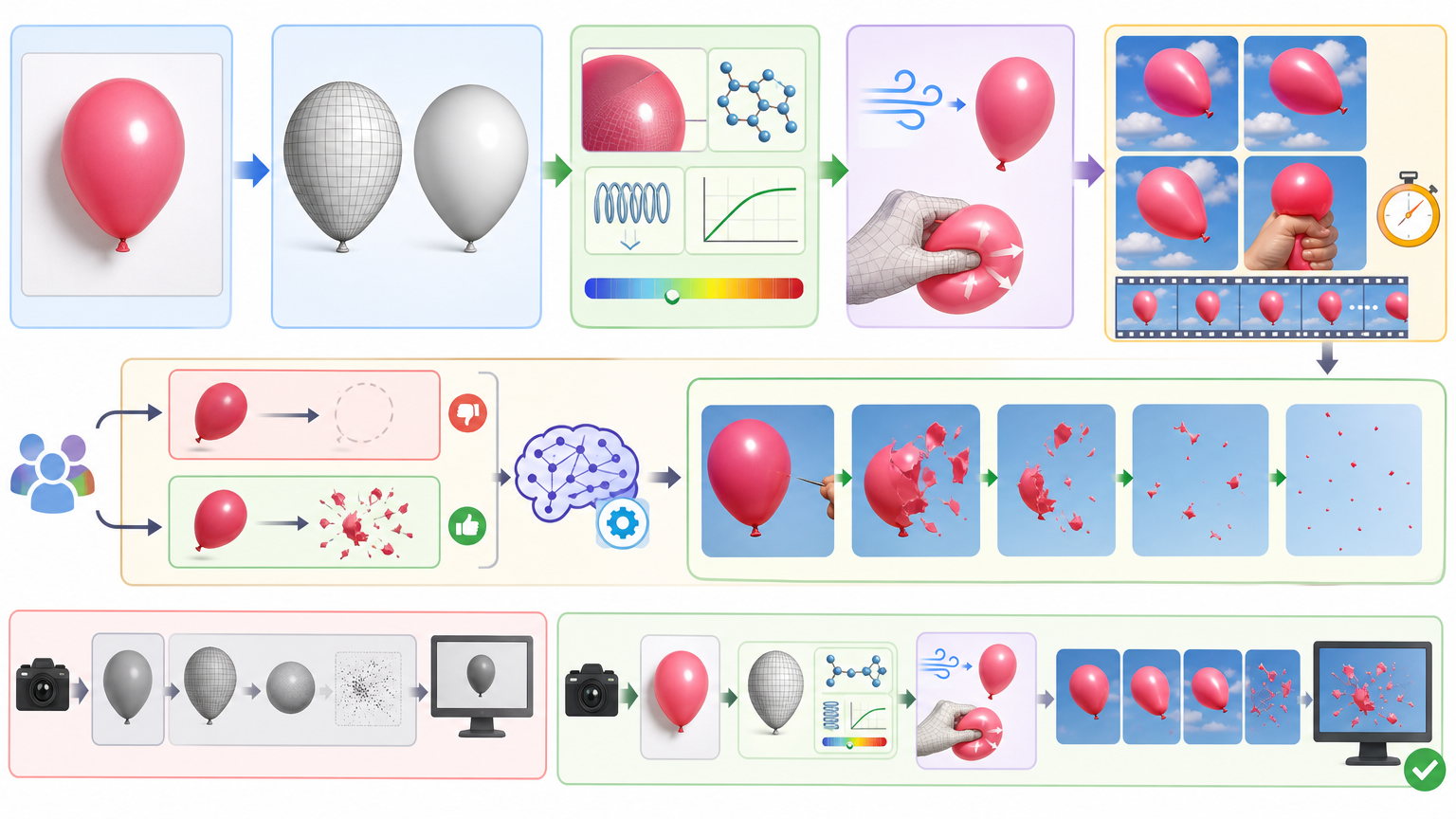
不过目前PhysGM还只能处理单个物体的动态,对于多个物体的交互,比如杯子掉在桌子上的碰撞反弹,还很难精准模拟。这也是未来3D视觉要攻克的核心难题:让AI理解不同物体之间的物理关系。
当我们谈论3D视觉的进化时,本质上是在谈论AI认知方式的转变:从“看图像的奴隶”,变成“理解世界的学习者”。过去AI的3D能力,更像一个只会临摹的画家,画得再像也不知道自己画的是什么;而现在的AI,开始像一个建筑师,先在脑子里搭好结构、算好力学,再动手“画”出符合逻辑的画面。 更值得关注的是,这些技术的落地速度正在加快:SAM 3D已经能从普通照片里重建出可用的3D模型,Realiz3D解决了3D生成的“塑料感”问题,NERFIFY则把论文变成可运行代码的时间从几周压缩到了几分钟。 懂空间,晓物理,才是AI看世界的正确方式。 当AI真正理解了3D世界的规律,它才能在自动驾驶里准确判断障碍物的距离,在机器人抓取时避开易碎的物品,在元宇宙里创造出和真实世界一样可信的虚拟空间。