对抗知识焦虑,从看懂这条开始
App 下载
不追顶尖的DeepSeek V4,正在补AI的课
国产芯片|推理成本|上下文窗口|DeepSeek V4|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载国产芯片|推理成本|上下文窗口|DeepSeek V4|大语言模型|人工智能
当行业都在喊着「吊打」「碾压」的时候,有个团队偏要做「差一点」的模型。2026年4月发布的DeepSeek V4,公开承认自己比顶尖闭源模型落后3到6个月——这在习惯了「世界第一」叙事的AI圈,简直是异类。但就是这个「异类」,悄悄把大模型的上下文窗口拉到了100万token,相当于能一口气装下《指环王》三部曲;还把推理成本压到了顶尖闭源模型的几十分之一,甚至适配了国产芯片。为什么有人放着「爆款」不做,非要当「补课生」?这背后藏着AI行业最务实的逻辑。
你可以把大模型的上下文窗口想象成电脑的内存——内存越大,能同时处理的文件就越多。过去的大模型最多只能装下12.8万token的内容,要是给它一本百万字的小说,它读到后半段就会忘了开头。 DeepSeek V4解决这个问题的核心,是一套叫DSA的稀疏注意力机制。你可以把它理解成一个聪明的秘书:面对堆积如山的文件,它不会逐字逐句读完全部,而是先快速扫过所有内容,用「闪电索引器」挑出最关键的部分,再集中精力处理这些重点。 但真实的机制比这更精确:它先对所有token做维度压缩,再用自研的稀疏算法只保留和当前任务相关的信息,把注意力计算的复杂度从平方级降到了近线性。数据显示,在100万token的上下文下,它的内存占用只有传统模型的1%,推理算力仅为上一代的27%。
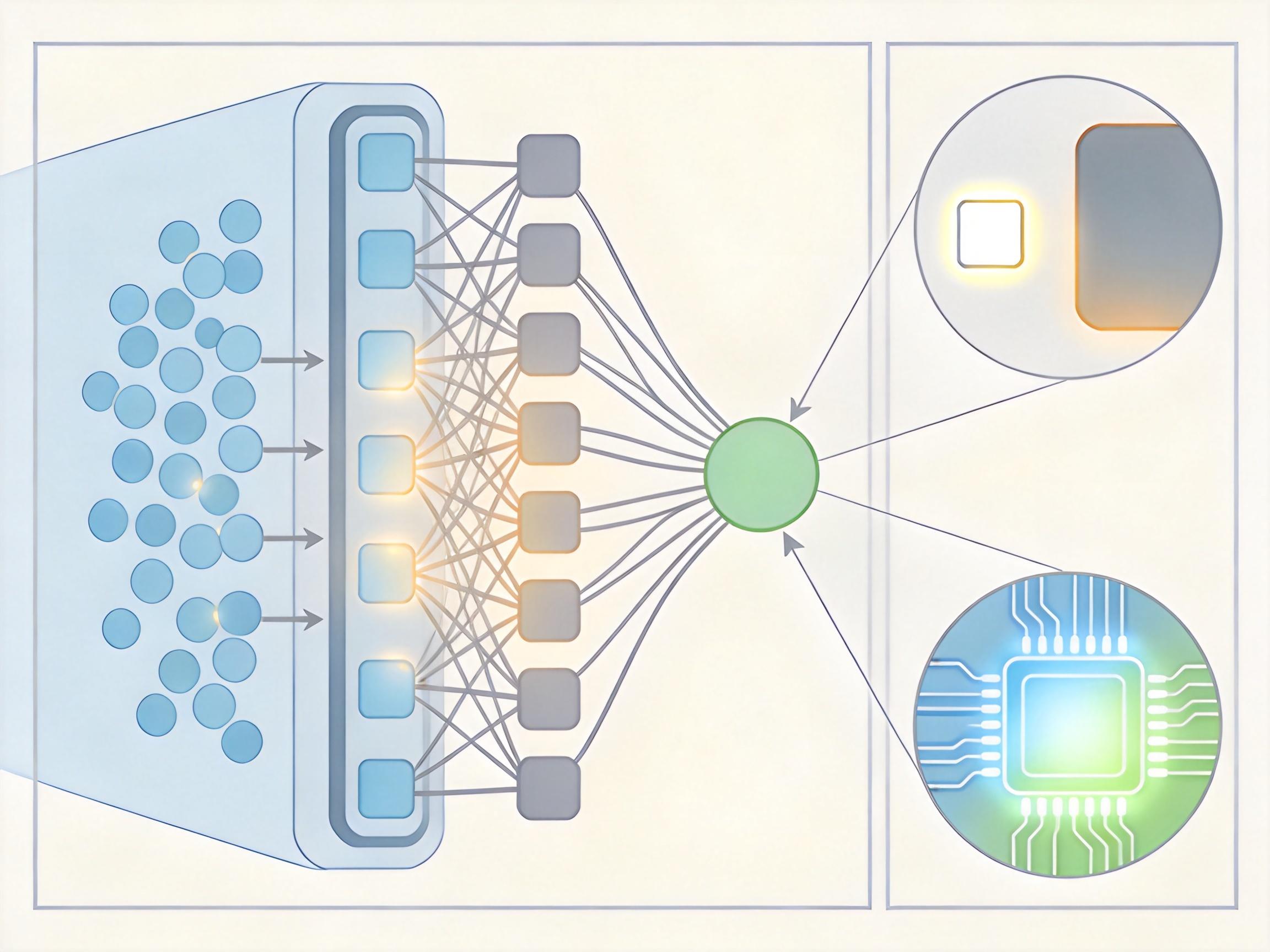
这不是炫技,而是解决了真实世界的痛点——比如律师可以用它一次性分析上百份合同,程序员能让它直接读懂整个代码库,科研人员不用再把论文拆成几段喂给模型。
如果说上下文窗口是模型的「内存」,那训练策略就是模型的「学习方法」。DeepSeek V4这次换了一套叫On-Policy Distillation(OPD)的后训练路径——简单说,就是先让模型分别学透各个领域的技能,再把这些技能融合成一个全能选手。 过去的训练方法更像「题海战术」:把所有数据混在一起喂给模型,让它自己慢慢摸索。但OPD是「分科培优」:先训练出擅长编程的「代码专家」、擅长推理的「逻辑专家」、擅长写作的「文案专家」,再用蒸馏技术把这些专家的能力提炼出来,融合进同一个模型里。
这种方法的好处是精准——模型不会再出现「编程厉害但写文章啰嗦」的偏科问题。实测数据显示,它在编程基准测试HumanEval上拿到了76.8%的得分,能直接生成可运行的3D魔方模拟代码,还能根据一篇文章自动生成排版精美的PPT。 当然它也有局限:在创造性写作上,它偶尔会生硬地拽出技术术语,流畅度不如GPT-5;Agent多步任务的稳定性也还比不上顶尖闭源模型,处理复杂任务时偶尔会「卡壳」。
DeepSeek V4最特别的地方,是它的「补课」定位——它不追求一时的惊艳,而是盯着行业的短板补。 第一个短板是「国产芯片适配」。过去国内大模型几乎全靠英伟达GPU训练,一旦供应链出问题,整个行业都会停摆。DeepSeek V4首次全面适配了华为昇腾系列芯片,训练和推理都能在国产硬件上完成。这不是简单的兼容,而是从模型架构层面做了优化,比如调整了参数分布和计算逻辑,让国产芯片的算力能充分发挥。 第二个短板是「开源生态的空白」。顶尖闭源模型虽然好用,但价格贵、不能本地化部署,中小企业根本用不起。DeepSeek V4不仅开源,还推出了两个版本:1.6万亿参数的Pro版负责复杂任务,2840亿参数的Flash版主打低成本快速响应,后者的API价格比上一代降了50%。 第三个短板是「长文本推理的实用性」。之前很多模型号称支持长上下文,但实际用起来要么速度慢,要么会丢失信息。DeepSeek V4把100万token做成了标配,而且真的能在这个长度下保持推理的准确性——有软件工程公司用它分析85万token的代码库,成功定位了跨文件的内存泄漏问题,准确率达97%。
当大家都在盯着「下一个GPT」的时候,DeepSeek V4选择做「能落地的大模型」。它没有炫技式的突破,却把那些被忽略的细节做扎实:让长上下文从「实验室指标」变成「实用功能」,让国产芯片从「备选方案」变成「核心支撑」,让开源模型从「玩具」变成「企业能用的工具」。 斯坦福2026年的AI指数报告显示,中美顶尖模型的性能差距已经几乎持平,而中国在AI专利、工业应用上的优势正在扩大。这种优势不是靠一两个「爆款」堆出来的,而是靠无数像DeepSeek V4这样的「补课生」,把每一块短板都补上,把每一步都走稳。 真正的技术进步,从来都是慢工出细活。