对抗知识焦虑,从看懂这条开始
App 下载
SAR图像去噪新解法:空间频率加知识三重协同
电子科技大学|知识三重协同|空间频率特征|斑点噪声|合成孔径雷达|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载电子科技大学|知识三重协同|空间频率特征|斑点噪声|合成孔径雷达|多模态视觉|人工智能
想象你在暴雨夜的监控画面里找一辆车——雨点糊满镜头,车灯和路灯的反光搅成一片,目标和背景几乎融为一体。这就是合成孔径雷达(SAR)图像识别每天要面对的困境:那些像雪花一样铺满画面的斑点噪声,是雷达主动成像时微波干涉的天生产物,会把坦克的棱角、船舶的轮廓搅成模糊的色块,让AI模型频频认错。
2026年3月,电子科技大学的团队拿出了一套新解法:他们不只是在图像上“磨皮”,而是同时从空间细节、频率特征和经验传递三个维度下手,让AI在噪声里精准锁定目标。更关键的是,这套方法还能在“高精度”和“轻量易部署”之间自由切换。
过去处理SAR图像的斑点噪声,要么在空间域用卷积核“磨平”噪声,要么在频率域过滤掉干扰信号,但都有局限:空间卷积容易把目标细节一起磨没,傅里叶变换的频率分析又找不到噪声在图像里的具体位置。
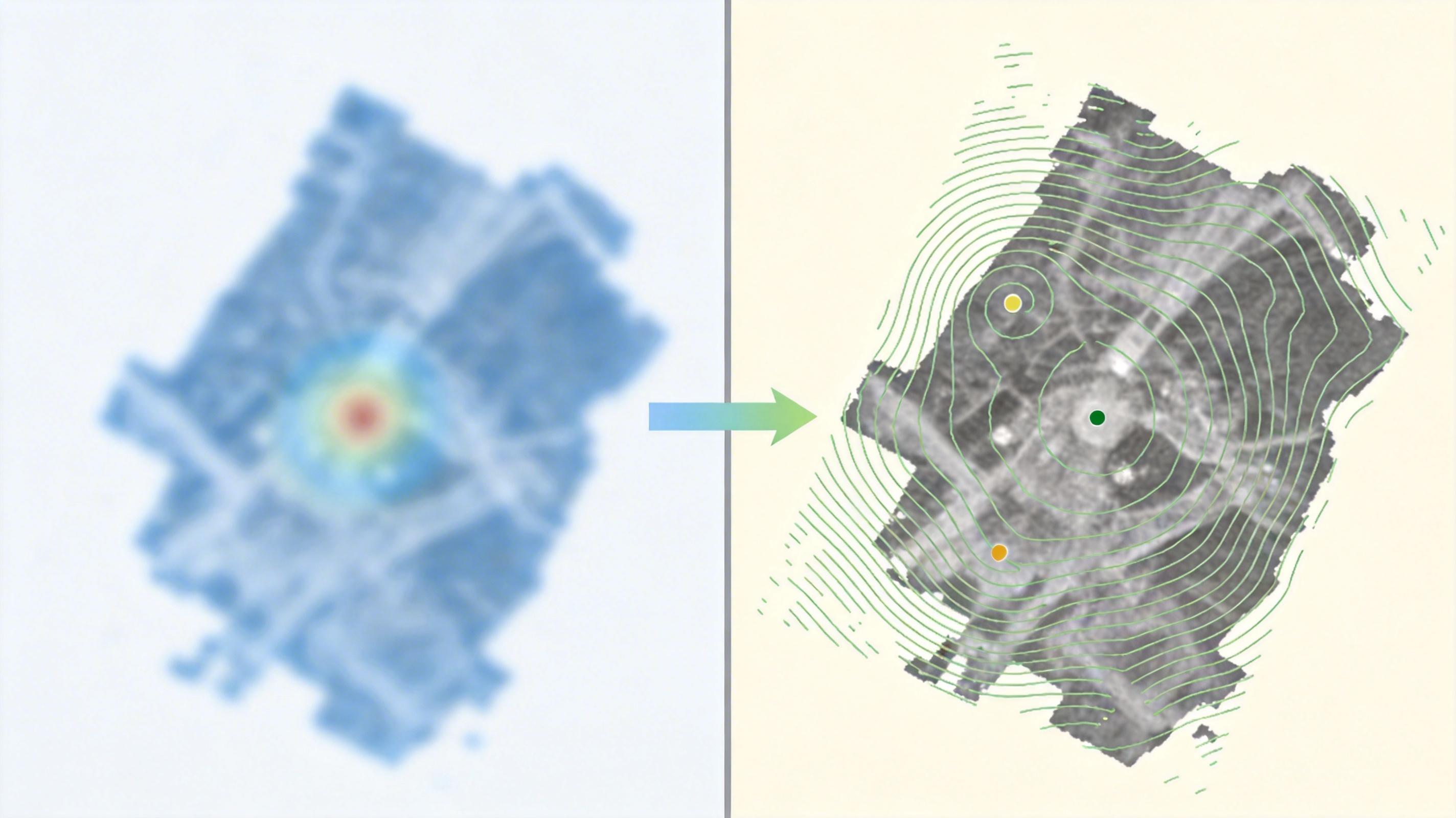
这次的核心突破,是把空间多尺度卷积和哈尔小波变换结合成一个叫DSAF的模块。你可以把它想象成同时用两种工具找东西:空间多尺度卷积像一套不同粗细的放大镜——小放大镜看坦克的履带齿、船舶的舷窗细节,大放大镜抓目标的整体轮廓;哈尔小波变换则像一个精准的音频编辑器,把图像里的“噪声杂音”和“目标信号”分开,它能定位到哪个位置的高频信号是噪声,哪个是目标的边缘特征,这是傅里叶变换做不到的。
具体来说,DSAF模块会先对图像做哈尔小波分解,得到低频的整体轮廓和三个方向的高频细节,用自适应卷积增强目标相关的高频、抑制噪声高频,再转换回空间域;同时用3×3、5×5、7×7、9×9四种卷积核并行提取空间特征,最后通过注意力模块(CBAM)给目标区域的特征“加权”,让AI只盯着有用的部分看。实验里,经过DSAF处理的图像,背景噪声被平滑了70%以上,目标的纹理细节却清晰了一倍。
有了强大的特征增强模块,团队还做了一件更聪明的事:让一个训练成熟的大模型(ResNet101)当“师父”,实时指导轻量模型(ResNet18或ShuffleNetV2)学习。这就是在线知识蒸馏——和传统“师父先学完再教徒弟”的离线蒸馏不同,师徒俩是同步训练的,师父会随时把自己“怎么在噪声里找目标”的经验传给徒弟。
这里的关键是“软标签”:师父给出的不是“这是坦克”“这是船舶”的硬判断,而是“90%是坦克,8%是装甲车,2%是卡车”的概率分布。这种模糊的判断里藏着师父对噪声的理解——比如坦克和装甲车在噪声里的相似特征,徒弟能从中学到更细致的区分逻辑,而不是只会机械匹配标签。
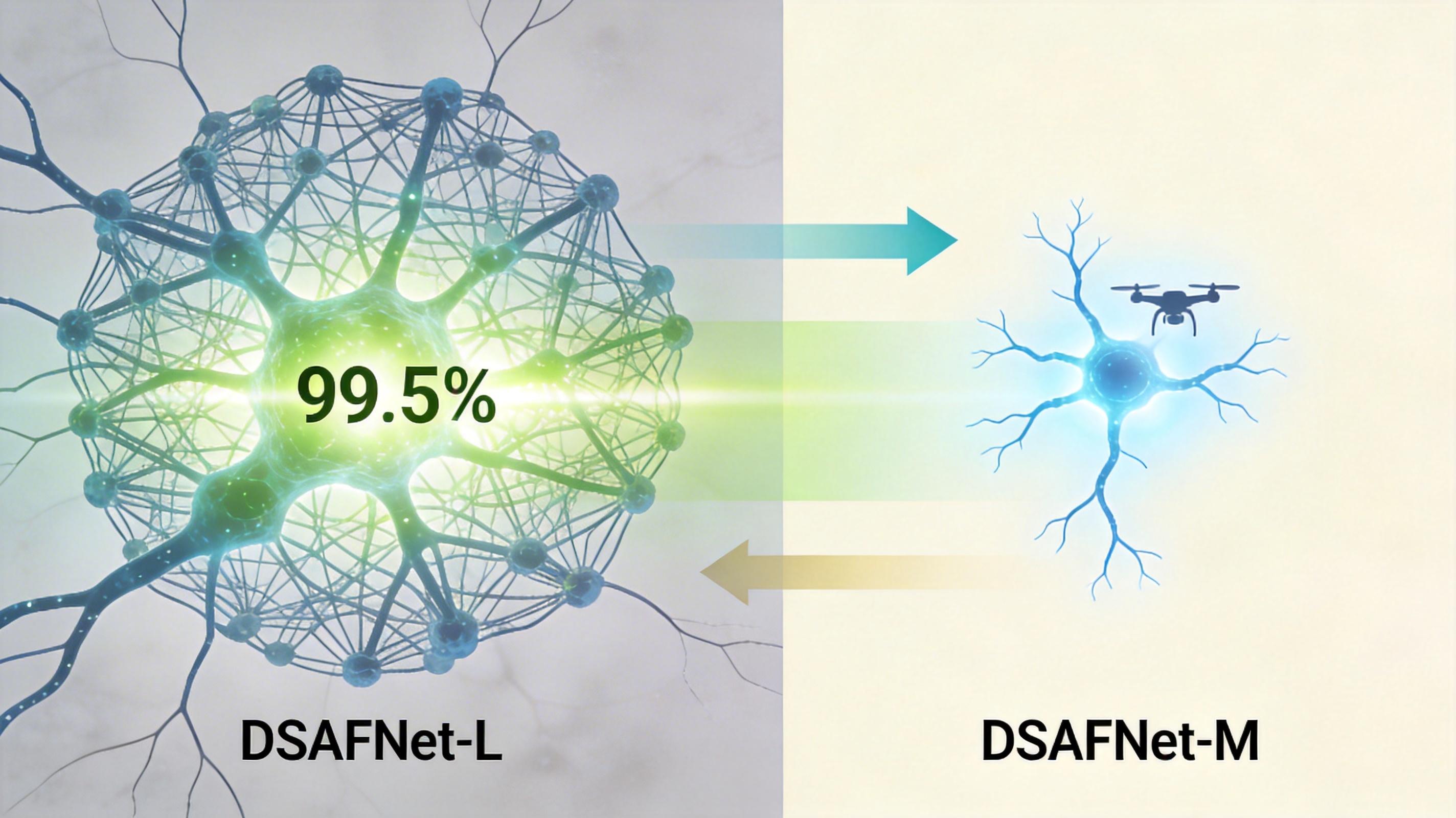
团队做了两套模型:高精度版DSAFNet-L用ResNet18当骨干,在军用车辆数据集MSTAR上准确率达到99.5%,比之前的最优模型高了1.2%;轻量版DSAFNet-M用ShuffleNetV2当骨干,参数只有0.17M(是DenseNet的1/5),计算量减少了90%,但准确率只降了不到2%,刚好能装在无人机、卫星这类资源有限的设备上。
这套方法虽然效果显著,但离真正的落地还有距离。首先是复杂噪声的挑战——现在的测试都是单一的斑点噪声,而现实中SAR图像还会遇到电磁干扰、系统噪声等混合噪声,模型能不能扛住还需要验证。其次是极低信噪比场景:当目标信号几乎被噪声完全淹没,比如藏在树林里的小型装备,现有的特征增强方法可能就失效了。
更重要的是模型的可解释性。现在我们能通过热图看到AI盯着目标的哪个部位,但不知道它为什么盯着那里——是因为那个位置的散射特征符合坦克的物理特性,还是只是刚好和训练数据匹配?如果能把AI的关注区域和SAR目标的物理散射机理关联起来,比如“AI盯着的是坦克炮管的强散射中心”,那模型的可靠性会大大提升,也更容易被军事、灾害监测这些对可信度要求高的领域接受。
SAR技术的价值,从来都不是拍一张清晰的“照片”,而是在光学成像失效的地方——暴雨夜的海面、云雾笼罩的战场、地震后的废墟——提供可靠的目标信息。这次的FSCE框架,本质上是给AI补上了“在复杂环境里做判断”的能力:不只是靠算法算力,还要结合对物理世界的理解,以及“老司机带新司机”的经验传递。
抗噪的本质,是学会在混乱里找规律。 这句话不只是说AI,也是说我们对复杂信号的理解——从单一维度的“对抗噪声”,到多维度的“利用噪声里的有效信息”,这才是SAR图像识别真正的突破方向。