对抗知识焦虑,从看懂这条开始
App 下载
AI假图能骗过人类,却躲不过这两套算法
社交媒体传播|AI生成图片|CVPR挑战赛|图像篡改识别|AI假图检测|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载社交媒体传播|AI生成图片|CVPR挑战赛|图像篡改识别|AI假图检测|多模态视觉|人工智能
你刷到过这样的新闻吗?一张领导人签署新政策的高清照片,细节逼真到能看清文件上的水印;或是一张从未见过的历史遗迹图,光影纹理完全符合真实场景。但它们可能是AI在10秒内生成的假图——人类肉眼的识别准确率已逼近随机猜测,社交媒体上的假图正以每天数百万张的速度扩散。2026年CVPR的一场挑战赛,把全球最顶尖的AI打假团队聚到了一起,他们要解决的核心问题是:当假图被压缩、模糊、加滤镜甚至被恶意篡改后,还能被揪出来吗?
这场挑战赛的数据集堪称AI打假界的“魔鬼训练班”:29.5万张图片里,混着来自42种AI生成器的18.6万张假图,每张图还会被随机施加1到5种“易容术”——从常见的JPEG压缩、高斯模糊,到专业级的散斑噪声、有机摩尔纹,甚至是专门针对检测模型的对抗性水印擦除。
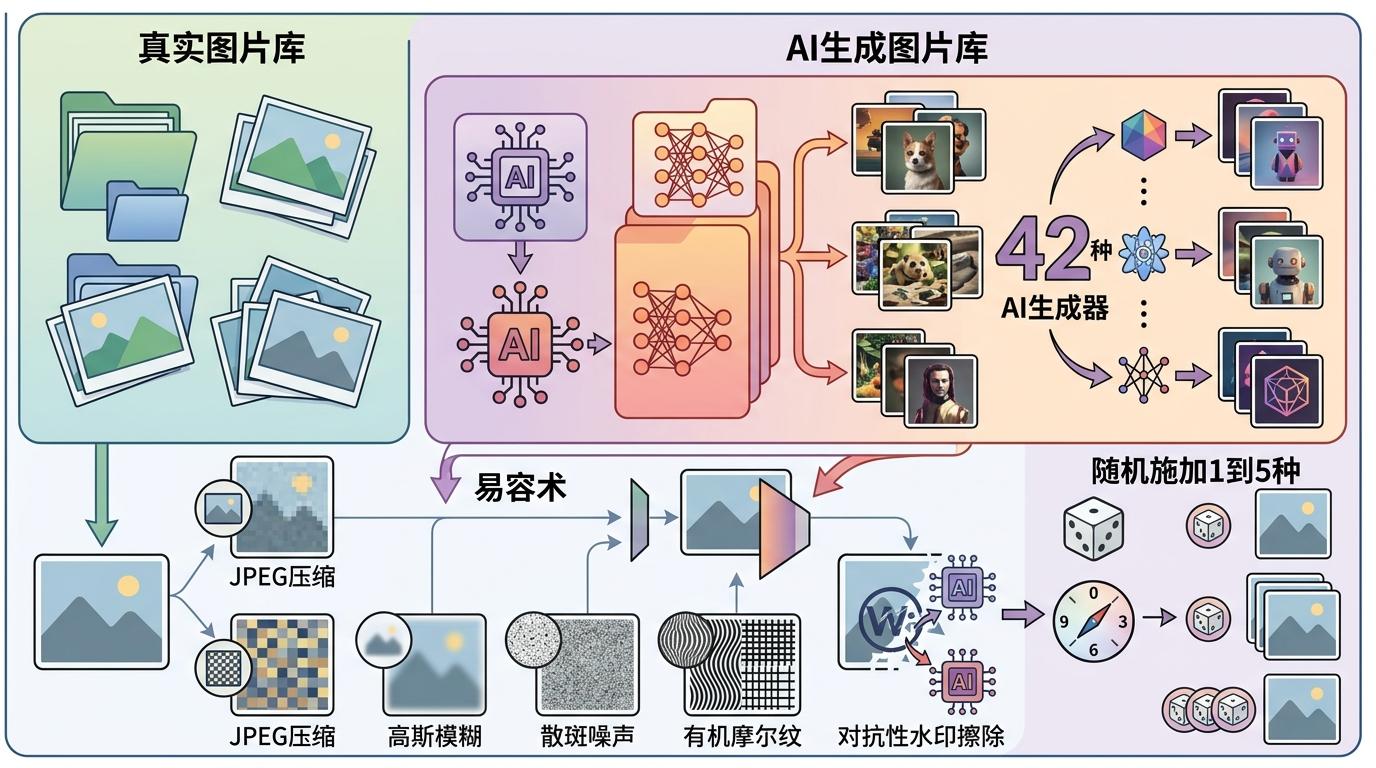
测试结果划出了一道清晰的分水岭:在未经处理的“干净”假图上,几乎所有参赛模型的检测准确率都能达到99%以上,ROC AUC值接近完美的1;但经过“易容术”改造后,绝大多数模型的准确率直接跳水,最低的甚至跌到了83%。只有不到10%的顶尖团队,能把鲁棒ROC AUC稳定在0.97以上——这意味着他们的模型在现实场景里,依然能保持极高的打假精度。
背后的核心逻辑很简单:实验室里的假图是“裸奔”的,而现实中的假图会经历各种传播中的损耗,就像罪犯作案后会精心伪装。普通模型只能认出“素颜”的假图,而顶尖模型能看穿层层伪装下的本质。
夺冠的MICV团队和亚军蚂蚁集团的方案,核心思路高度一致——用超大视觉模型当“火眼金睛”的基础,再用分层数据增强和专家集成练出“抗干扰体质”。
他们都选择了Meta的DINOv3-7B作为核心骨干。这个拥有70亿参数的自监督模型,在17亿张图片上训练出了极强的通用视觉表征能力——你可以把它想象成一个见过世间所有图像的“老刑警”,能一眼捕捉到普通人忽略的细节。蚂蚁团队的实验显示,模型参数越大、输入分辨率越高,对未知生成器的泛化能力就越强,甚至能认出训练数据里从未出现过的新型假图。
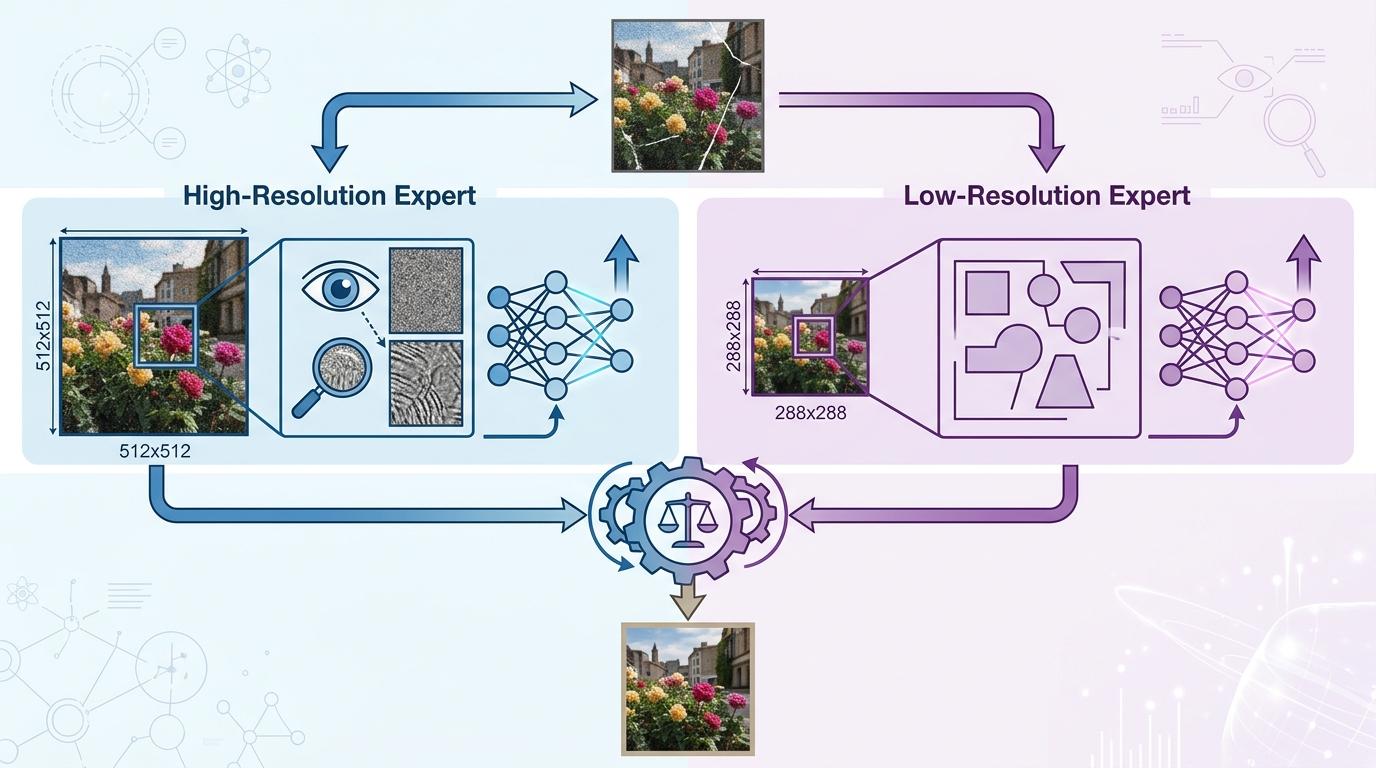
更关键的是他们的“双专家”策略:一个专家用512×512的高分辨率输入,专注学习中重度失真图片的细节纹理;另一个专家用288×288的低分辨率输入,专门捕捉对失真不敏感的本质特征。最后把两个专家的判断加权融合,就像让两个不同领域的医生共同诊断,既能看清细节,又不会被表面的伪装迷惑。
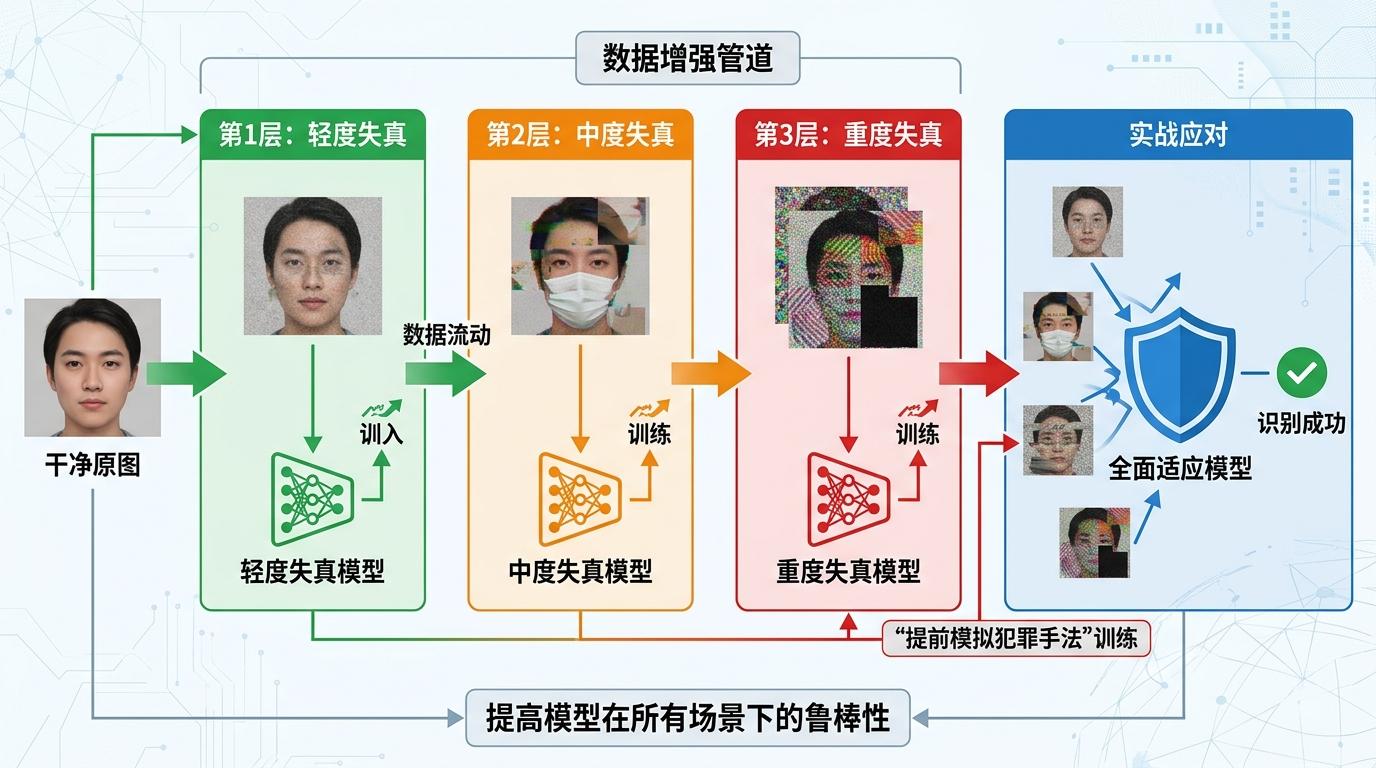
为了让模型适应各种“易容术”,他们还构建了四层离线数据增强管道:从干净原图到轻度失真,再到中度、重度失真,让模型在训练时就见过所有可能的伪装场景。这种“提前模拟犯罪手法”的训练方式,让模型在实战中遇到任何情况都能从容应对。
但这些顶尖方案离真正的大规模落地,还有三道难以跨越的坎。
首先是算力成本的问题。蚂蚁团队的双专家模型需要78GB的显存,在A100 GPU上每秒只能处理2.21张图片——这个速度远不能满足社交媒体平台每秒数百万张的检测需求。如果要在抖音、微信这样的平台部署,光是硬件成本就是天文数字。
其次是对抗性攻击的威胁。挑战赛里的36种“易容术”都是已知的,但现实中恶意用户会针对性地设计新的攻击手段——比如专门针对某个检测模型的对抗性扰动,或是用最新的生成模型制作假图。就像警察的破案手法升级,罪犯的作案手段也会跟着进化,这场猫鼠游戏永远不会结束。
最后是“黑箱”带来的信任危机。现在的检测模型只能告诉你“这是假图”,但无法像人类专家那样指出“哪里假了”——是纹理不自然,还是光影逻辑错误?在司法、新闻审核等需要绝对可信的场景里,这种“只给结论不给理由”的判断,很难被当作有效证据。
这场挑战赛更像是一次AI打假技术的“压力测试”,它证明了我们已经能在实验室里造出接近完美的打假工具,但要让这些工具走进现实,还有很长的路要走。未来的AI打假,不能只追求更高的准确率,还要兼顾效率、适应性和可解释性——就像一个真正的好警察,不仅能快速抓到罪犯,还要能说出犯罪的证据,并且能跟上罪犯不断变化的作案手法。
鲁棒性,才是AI从实验室走向现实的分水岭。 这句话不仅适用于AI打假,也适用于所有想要落地的AI技术:在实验室里表现再好,经不起现实的考验,终究只是纸上谈兵。