对抗知识焦虑,从看懂这条开始
App 下载
AI答对了67年前的医学考题,比医生还快
《科学》杂志|急诊推理模型|免疫抑制|坏死性筋膜炎|哈佛医学院|大语言模型|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载《科学》杂志|急诊推理模型|免疫抑制|坏死性筋膜炎|哈佛医学院|大语言模型|临床诊疗技术|医学健康|人工智能
2026年春的一个急诊室,器官移植患者捂着睾丸走进来,还带着点咳嗽。人类医生的注意力立刻被呼吸道症状牵走——这是最直观的主诉。但AI推理模型扫过分诊记录里的“免疫抑制”四个字,直接在病历上标记了坏死性筋膜炎:一种拖12小时就可能致命的感染。它比人类医生早了整整一天做出关键判断。这不是科幻片里的桥段,而是哈佛医学院团队发表在《科学》杂志上的真实病例。67年前,有人第一次提出“机器能不能像医生一样思考”,今天,AI不仅给出了答案,还在某些场景下跑得更快。
1959年,Robert Ledley和Lee Lusted在《科学》杂志抛出一个问题:让机器做麻省总医院的临床病理讨论会(CPC)病例题,能不能像医生一样推理?这些病例是医学界公认的“地狱级考题”——来自真实患者,被专家刻意塞满罕见病表现和干扰信息,专门用来考验医生的诊断逻辑。
67年后,哈佛团队带着AI推理模型交了卷:143个CPC病例,AI在78.3%的病例里把正确答案放进了鉴别诊断清单;如果放宽到“给出有帮助的方向”,这个数字是97.9%。在真实急诊室的76个病例里,分诊阶段AI的诊断准确率是67.1%,而参与测试的两位人类主治医生分别是55.3%和50.0%。
你可以把AI的这种能力理解成“超级医学学霸”——它用链式思维(Chain-of-Thought)拆解诊断任务:先根据症状提出多个假设,再像医生一样一步步用线索验证、排除,最后锁定方向。区别在于,它能瞬间调用训练过的海量医学文献和病例,不会被直观症状干扰,也不会漏掉“免疫抑制”这种藏在文本里的关键细节。
人类医生诊断时,容易陷入“锚定效应”——先抓住最显眼的症状,再顺着这个方向找证据。但AI的推理模型是“全局扫描式”的:它会把所有文本信息拆成最小的语义单元,比如“免疫抑制”“睾丸疼痛”“呼吸道症状”,然后用训练出的医学关联知识,把这些点连成网。
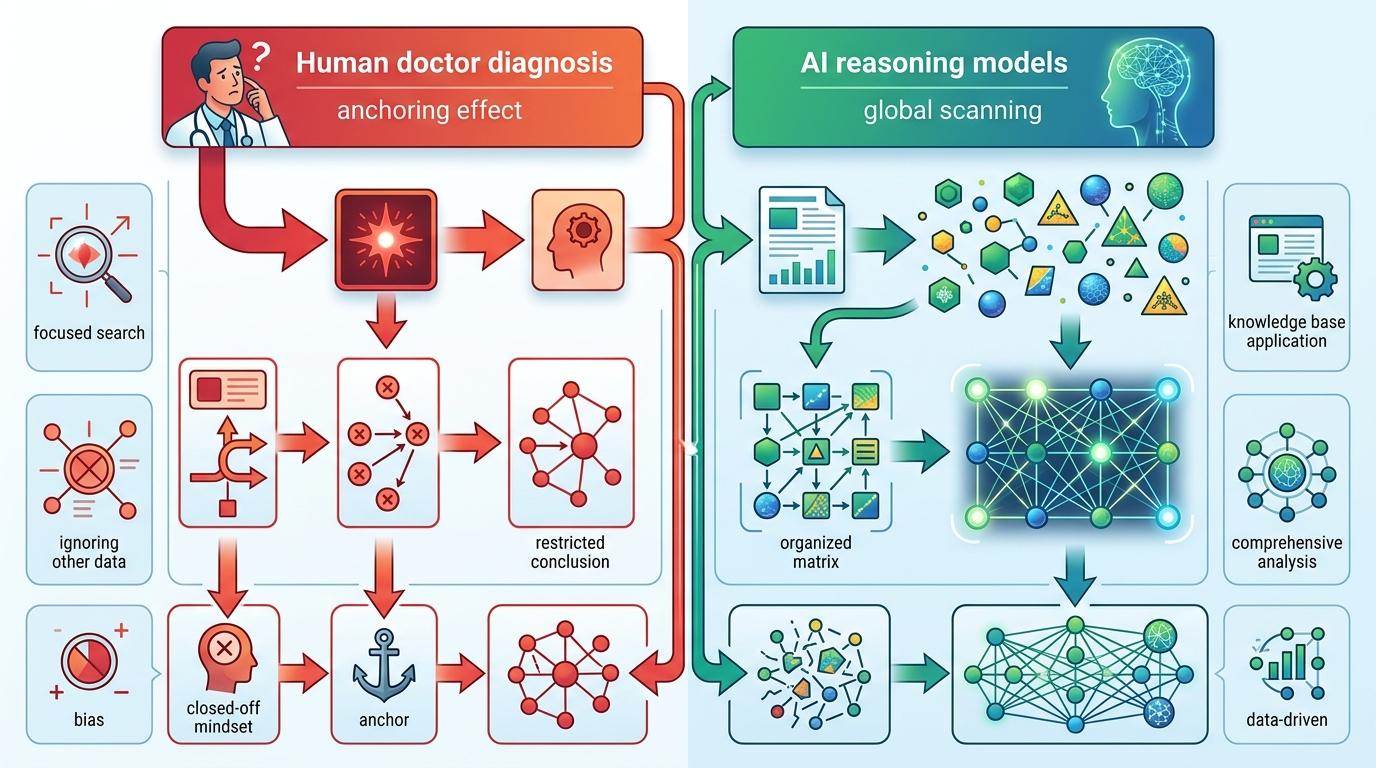
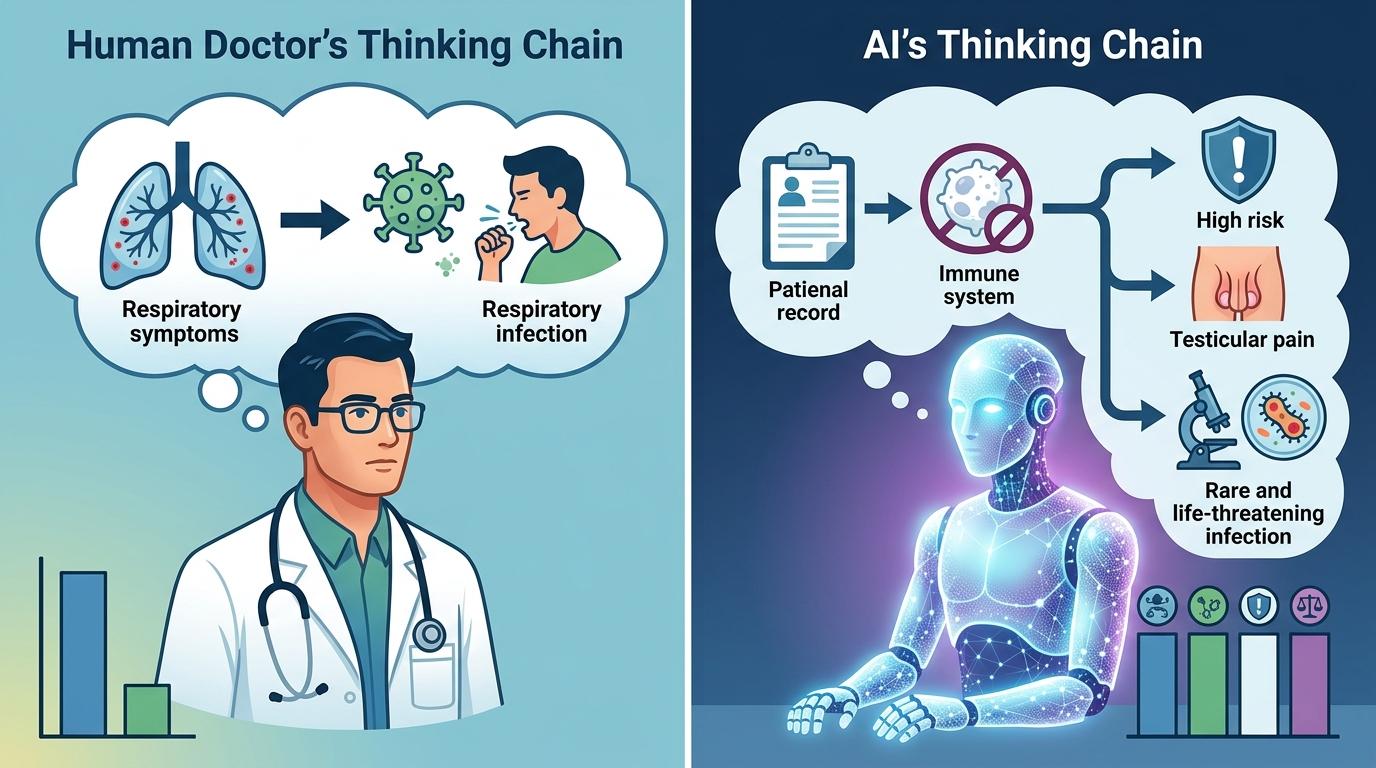
在那个移植患者的病例里,人类医生的思维链是“呼吸道症状→呼吸道感染”,而AI的思维链是“免疫抑制→感染风险极高→睾丸疼痛+免疫抑制→罕见致命感染”。它不会被症状的“显眼程度”影响,只会严格按照医学逻辑关联信息。
但AI也有自己的短板。它目前只能处理文本信息,读不了X光片,摸不出患者皮肤的红肿温度;它的“知识”来自训练数据,遇到超出训练范围的罕见病例,可能会生成看似合理却完全错误的“幻觉”答案。更重要的是,它不懂患者的情绪——不会在给出致命诊断时,握住患者的手说一句“我们会尽力”。
研究团队最强调的不是AI的分数,而是“该怎么用它”。2025年的一项全球调查显示,五分之一的临床医生已经开始用AI拿第二意见,这个数字还在快速增长。但没人认为AI能替代医生——它更像一个“不会走神的助手”:在急诊室的嘈杂环境里,帮医生盯着那些容易被忽略的细节;在信息不足的分诊阶段,提前圈出高危病例;在写病历的时候,快速整理出符合规范的诊断逻辑。
目前的AI还需要人类的“把关”:比如它给出的诊断,需要医生结合患者的实际体征和影像结果验证;它的“幻觉”错误,需要医生用临床经验识别。研究团队正在做的,就是让AI和医生形成“互补”:AI补人类的“注意力缺口”,人类补AI的“临床温度”和“现实判断”。
还有一个不能忽视的局限:这次测试的病例主要集中在内科和急诊,儿科、外科这些需要更多实操和特殊经验的领域,AI的表现还是未知数;参与测试的医生多来自哈佛、斯坦福的精英网络,普通基层医生和AI的协作效果,还需要更多验证。
67年前,Ledley和Lusted想知道机器能不能像医生一样思考;今天,我们知道AI不仅能思考,还能在某些时候思考得更快、更全。但真正的考题从来不是“AI能不能赢过医生”,而是“人和AI怎么一起给患者更好的治疗”。
未来的急诊室里,可能会出现这样的场景:AI在后台扫过分诊记录,弹出一个“高危预警”;医生看到预警,再结合自己的临床判断,提前安排检查和治疗——没有谁替代谁,只有两个不同的“思考者”,一起为同一个目标努力。
金句:AI补人类的漏,人类补AI的缺。