对抗知识焦虑,从看懂这条开始
App 下载
旧照修复不用等,单步AI一秒还原真容
图像细节还原|旧照片修复|NTIRE挑战赛|单步扩散模型|人脸修复|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像细节还原|旧照片修复|NTIRE挑战赛|单步扩散模型|人脸修复|多模态视觉|人工智能
你手机里那张压箱底的童年模糊照,或是爷爷泛黄的参军旧相,过去要花几小时用专业软件磨皮、补细节,还容易把脸修成“陌生人”。现在,AI能在0.1秒内完成修复——不仅皱纹、发丝根根清晰,连你嘴角那颗小痣的位置都分毫不差。2026年NTIRE人脸修复挑战赛上,96支全球顶尖团队交出的答卷,宣告了一场技术革命的完成:人脸修复,终于从“慢工出细活”变成了“一键即得”。
传统AI修复人脸,像用砂纸慢慢打磨木雕——扩散模型要迭代几十上百次,逐步去除模糊、填充细节,一张512×512的图片要算上十分钟。而单步扩散模型,相当于直接用3D打印机“复刻”出清晰人脸:通过知识蒸馏技术,把多步模型的“经验”压缩进一个轻量模型,一次计算就能输出结果。

夺冠的MiPlusCV团队用的OSDFace模型,就是典型代表。它给低质量人脸拍了张“X光片”——用视觉表示嵌入器提取五官轮廓、身份特征等核心信息,再喂给单步生成器。不用反复调整,0.1秒就能输出一张身份准确、轮廓清晰的“半成品”,再交给Z-Image模型补上皮肤纹理、眼神光这些细节。整个流程下来,耗时不到传统方法的1%,修复效果却不相上下。
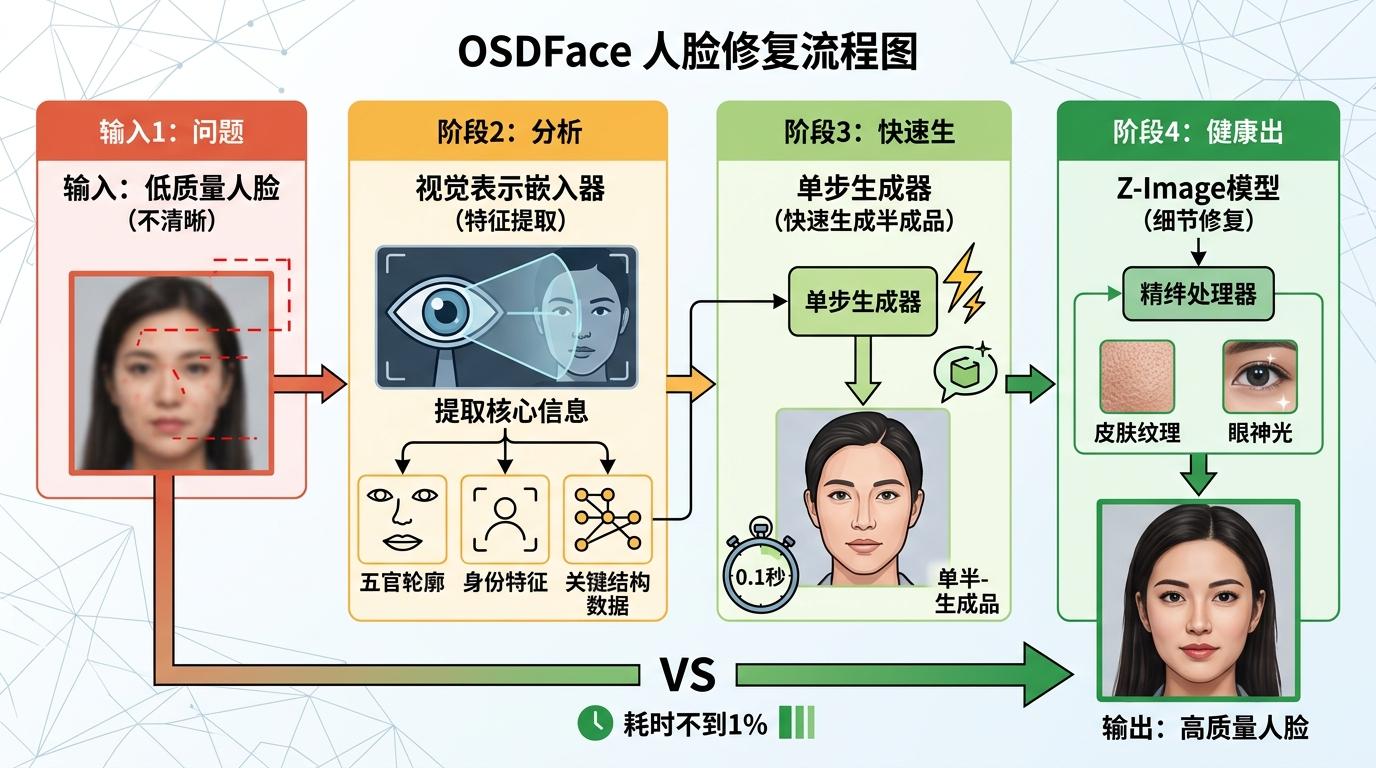
更关键的是,单步模型解决了“修着修着变了脸”的老问题。训练时加入ArcFace身份损失,相当于给AI装了个“人脸识别锁”,每生成一个像素都要比对原始人脸的特征向量,确保修出来的还是你。
过去做人脸修复,得专门训练一个模型,就像为了开一扇门,先造一整套开锁工具。现在的思路变了:直接用Stable Diffusion、FLUX.2这些通用图像大模型当“基建”,用LoRA、ControlNet这些“小插件”快速适配人脸修复任务。
LoRA(低秩适配)是最常用的“插件”。它不用改动大模型的上亿参数,只需要训练几MB大小的低秩矩阵,就能让大模型学会人脸修复的“技能”——相当于给手机装个App,不用换个新手机。MiPlusCV团队就是用LoRA微调Z-Image模型,只花了传统训练1/10的算力,就让模型能精准补上人脸的细微纹理。
这种“基建+插件”的模式,不仅降低了研发成本,还提升了模型的泛化能力。比如DeSC-Face团队给FLUX.2模型加了个“退化感知”插件,能自动识别照片是模糊、有噪点还是被压缩,再针对性调整修复策略,处理真实世界里千奇百怪的旧照片,比专门训练的模型更靠谱。
当大家都用上了单步模型和基础大模型,比拼的就变成了“细节功夫”。顶尖团队们开始像高考考生一样,“按评分标准答题”——直接用竞赛的评估指标指导模型训练。
MiPlusCV团队在模型训练完成后,又用CLIPIQA、MANIQA这些图像质量评估指标当“老师”,给模型做了一轮“考前冲刺”。模型生成一张图,指标就打个分,AI根据分数调整生成策略,直到输出的图能让所有指标都给高分。这种“指标导向优化”,让他们的修复图在机器评测里拿到了最高分。
还有团队给AI加了“语义眼镜”。CEVI-KLETech团队把人脸分成皮肤、眼睛、嘴巴等区域,用小波变换把图像拆成低频轮廓和高频细节,只对高频细节做针对性修复——就像给眼睛补光、给皮肤磨皮,但不动五官的位置。这种“语义结构引导”,彻底解决了AI“瞎编细节”的问题,修出来的脸既真实又不会走样。
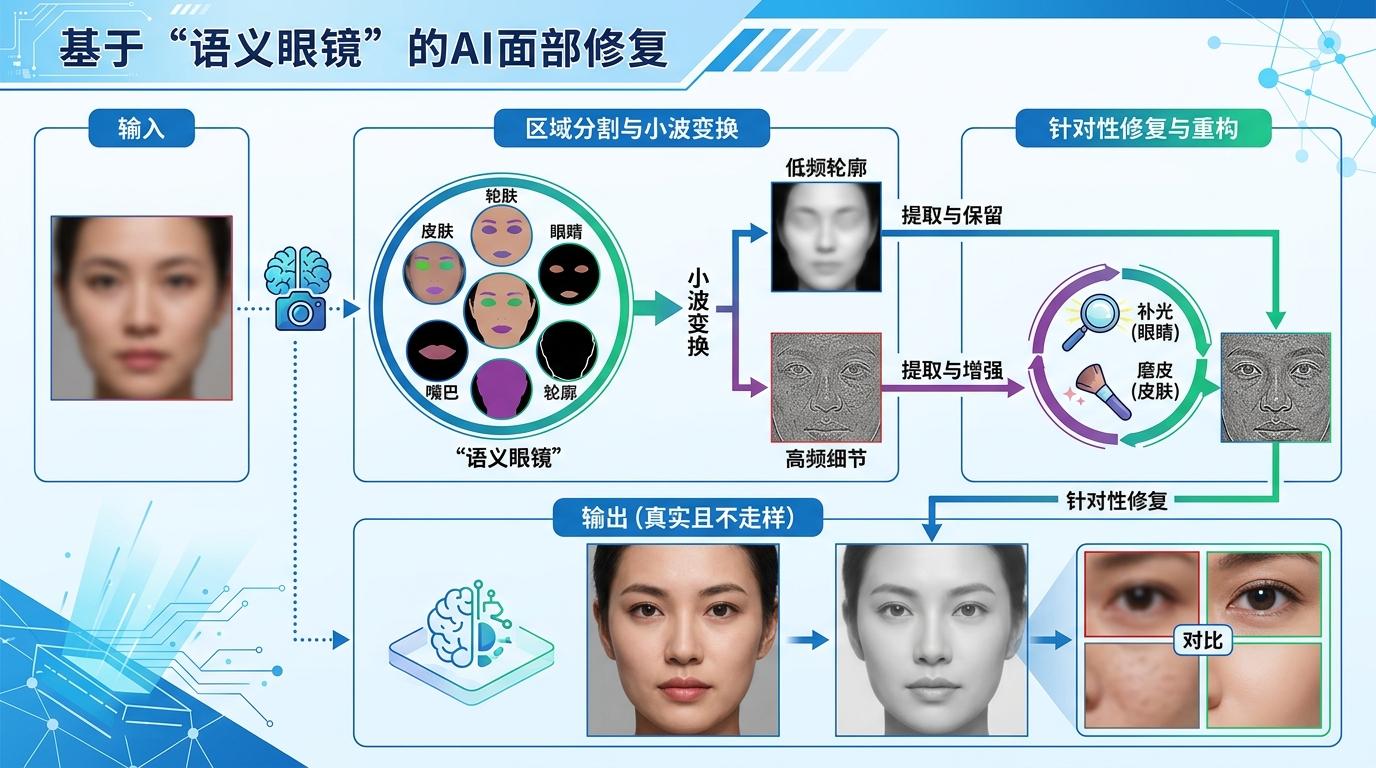
当AI能在0.1秒内还原一张旧照片的细节,我们修复的不只是图像,更是那些差点被时间模糊的记忆。但技术的进步也带来新的问题:当AI能精准复刻任何人的脸,如何防止它被用来伪造身份?当修复效果好到以假乱真,我们又该如何定义“真实”?
技术永远是双刃剑,但这一次,我们走在了平衡的路上——单步扩散和基础模型适配让人脸修复变得高效、普及,而指标导向和语义引导则给AI套上了“缰绳”,让它始终服务于“还原真实”的初衷。
效率与真实,终于可以兼得。