对抗知识焦虑,从看懂这条开始
App 下载
AI图像编辑新范式:1%数据如何解两大瓶颈?
百度|风格迁移|结构保持|数据稀缺|AI图像编辑|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载百度|风格迁移|结构保持|数据稀缺|AI图像编辑|多模态视觉|人工智能
想象一下,你试图教会一位画家,如何将一张白天的照片,在保持建筑结构不变的前提下,巧妙地转变为夜晚的迷人景象。这需要无数的“白天-夜晚”对比图,每一对都需精确标注,才能让画家领悟光影与色彩的奥秘。这正是AI图像编辑技术长期以来面临的严峻挑战:它像一位拥有无限创意的艺术家,却苦于没有足够的“教材”来学习如何精准地描绘世界的万千变化。AI图像编辑的核心诉求,是在保持图像原有结构不变的前提下,进行天马行空的风格或内容修改。但长期以来,这就像一道无解的数学题:数据稀缺让AI巧妇难为无米之炊,而结构保持与纹理修改的权衡困境则让它陷入“顾此失彼”的泥沼。
然而,就在2025年12月6日,一则来自百度的前沿研究新闻,为这道难题撕开了一道曙光。百度的Video4Edit团队,以一个看似简单的“点子”,为AI图像编辑领域带来了颠覆性的理论突破:将图像编辑视为退化的时间过程(Degenerate Temporal Process)。他们提出,如果将源图像看作视频的第0帧,编辑后的图像视为第1帧,那么一次图像编辑任务,不就自然地转化成了一个“2帧的极短视频生成过程”吗?正是这一“灵光一现”,让Video4Edit得以巧妙地利用视频预训练模型中蕴含的“单帧演化先验(Single-Frame Evolution Prior)”,实现了从视频生成到图像编辑的知识迁移。最令人震惊的是实验结果:Video4Edit仅需主流编辑模型约1%的监督数据,便能达到与当前第一梯队模型相当,甚至更优的性能。这意味着,AI图像编辑不再需要海量昂贵的标注数据,就能学会“从心所欲而不逾矩”的编辑魔法。
这一突破的魅力,在于其对“时间”的巧妙借用。传统的图像编辑模型,像是在学习一本本独立的画册,每页都是静态的“编辑前”与“编辑后”的对比。而Video4Edit则让AI观看了一部部“电影”,从中学习物体如何自然地演变,结构如何保持,纹理如何变化。
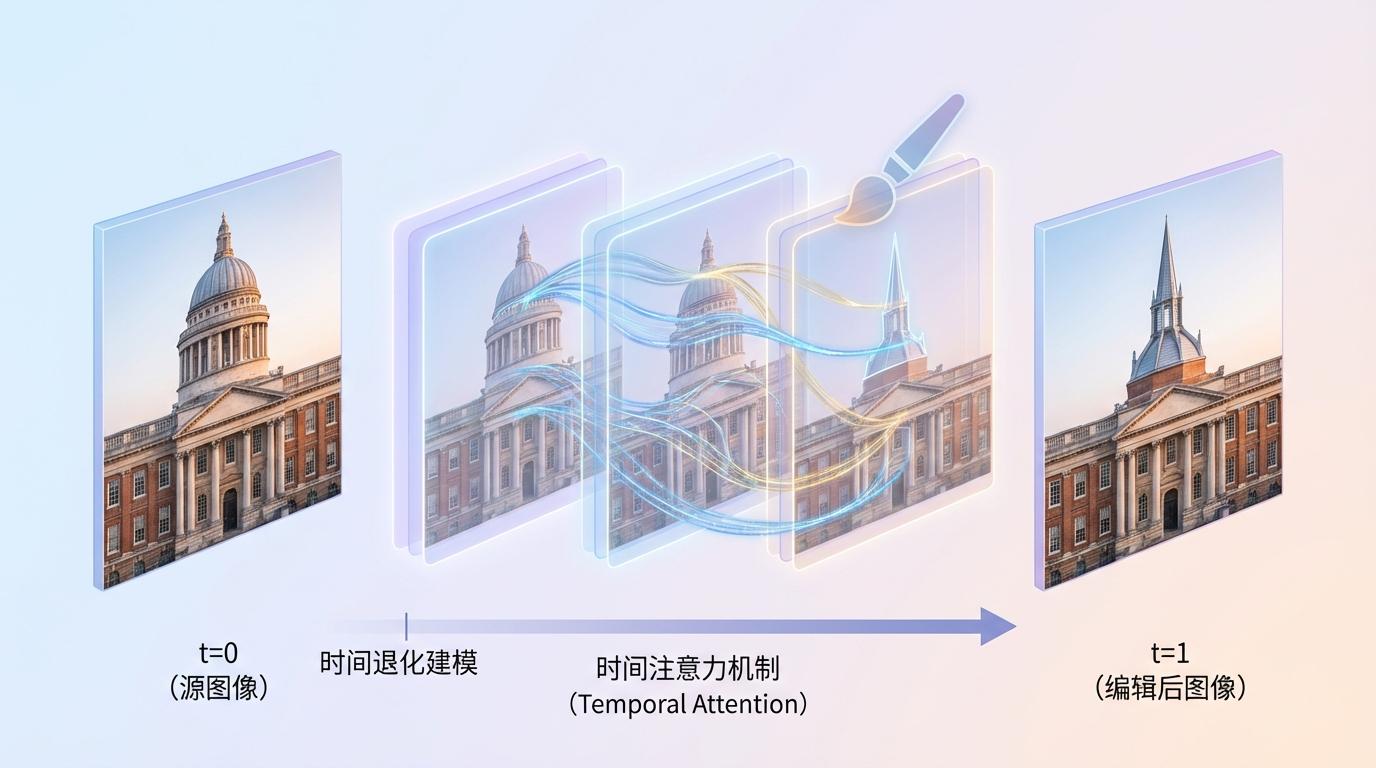
时间退化建模是其核心。Video4Edit将图像编辑过程建模为从t=0(源图像)到t=1(编辑后图像)的时序演化。通过这种转化,原本需要模型显式学习的“结构保持”约束,被巧妙地融入到视频生成中成熟的**时间注意力机制(Temporal Attention)**里。这种机制天然倾向于在相邻帧之间保持高频细节和几何结构,让AI在修改图像时,能像经验丰富的画师一样,在局部挥洒创意的同时,不破坏整体的平衡。
接着是先验知识迁移。视频生成模型在海量视频数据上预训练后,学习到了强大的时序一致性约束和帧间演化规律。这些知识,就像是AI的“世界观”,包含了结构保持与语义变化之间的微妙平衡。Video4Edit在潜在空间(Latent Space)中,将视频模型学习到的zt→zt+1转移概率分布,通过文本指令进行条件化引导。这意味着模型不再需要从零开始学习如何生成图像,而是高效地复用已有的视频生成能力,只需专注于理解和对齐用户的编辑意图。
从信息论角度看,引入视频先验极大地降低了假设空间的熵,提供了更强的有效泛化能力。这解释了为何仅需约1%的监督数据,Video4Edit就能实现高性能。它不再是“死记硬背”,而是“举一反三”,从视频的动态演化中领悟图像编辑的精髓。
回溯AI图像编辑的发展历程,我们不难发现其面临的重重挑战。早期的扩散模型方法,如同蹒跚学步的孩子,需要大规模、高质量的“指令-源图像-编辑后图像”三元组数据才能学会编辑。这种数据依赖不仅成本高昂,且难以覆盖多样化的用户编辑意图,就像仅凭教科书难以培养出真正的艺术家。
更深层次的难题在于“结构保持”与“纹理修改”之间的权衡困境。过度强调结构保持,会导致编辑的灵活性受限,修改后的图像显得生硬;而追求大幅度的语义修改,又容易导致几何失真,让图像面目全非。这就像一个雕塑家,既要改变雕塑的材质,又要保持其原有的形体,稍有不慎便会功亏一篑。
Video4Edit的出现,恰如其分地解决了这些痛点。它不再将图像视为孤立的静态实体,而是将其置于一个动态的“时间流”中考量。这种范式转变,不仅为图像编辑提供了更经济、更可扩展的训练方案,也预示着AI在理解和重构视觉世界方面,正迈向一个更加智能和自然的阶段。

Video4Edit的实测表现,无疑是其理论突破最强有力的证明。在多种图像编辑任务上,包括风格迁移、物体替换和属性修改,Video4Edit都展现出卓越的能力。无论是将文本“TRAIN”替换为“PLANE”,还是以高清晰度还原和着色老照片,亦或是将背景替换为雪山,它都能实现自然的语义融合,边缘处理质量高,无明显伪影。
在标准评估协议下,Video4Edit使用的监督数据量约为MagicEdit等基线方法的1%,但在关键评估指标上却达到了可比较甚至更优的性能。在衡量语义对齐质量的CLIP Score和衡量结构保持能力的Structure Score等指标上,Video4Edit与使用全量数据的基线方法性能相当,部分场景下甚至实现了性能提升。
这一结果颠覆了传统认知,表明通过利用视频预训练先验,可以显著降低对监督数据的依赖,同时保持高质量的编辑效果。它不仅提升了AI图像编辑的效率,更拓展了其应用边界,让过去因数据和算力门槛而难以企及的创意,变得触手可及。
Video4Edit的成功,并非孤例,它与NVIDIA的ChronoEdit等前沿研究共同指向了AI内容创作的未来。ChronoEdit同样将图像编辑视为视频生成任务,引入“时间推理令牌”来模拟编辑过程中的中间帧,确保物理一致性和时间连贯性,在自动驾驶、人形机器人等对物理真实性要求极高的场景中表现出色。
麻省理工学院的研究人员更是提出了一种颠覆性的“无生成器”图像生成和编辑范式,利用1D tokenizers将高分辨率图像压缩成简短的数字序列,通过操纵这些tokens实现对图像属性的精细控制,甚至能将红熊猫变为老虎,显著提高了效率和灵活性。
这些进展共同描绘了一幅AI内容创作的新图景:
然而,技术之光越是璀璨,其阴影也越是深邃。AI图像编辑与视频生成能力的飞跃,特别是“极短视频”范式的普及,必然带来深度伪造(Deepfake)技术的滥用风险。一张静态图像即可生成逼真的“编辑视频”,使得虚假信息、诈骗、侵犯肖像权和名誉权的门槛大幅降低。
全球各国已高度警惕。中国《互联网信息服务深度合成管理规定》要求深度合成内容进行标记;欧盟《人工智能法案》规定生成内容需符合透明度标准;美国田纳西州通过“ELVIS Act”保护个人形象权,并提出“NO FAKES Act”等联邦立法草案,旨在创设“数字复制权”。
这些法律框架和伦理准则,共同构筑起一道防线,旨在平衡技术创新与社会安全。未来,我们需要:
AI的强大能力,既是创作者的福音,也是伦理的考量。我们必须警惕“幻觉”的蔓延,确保AI在“生成”的同时,不“编造”;在“模仿”的同时,不“误导”。
百度Video4Edit团队以“将图像编辑建模为极短视频生成过程”这一理论突破,不仅以惊人的1%数据效率,成功破解了AI图像编辑长期以来的数据稀缺和结构-纹理权衡两大瓶颈,更重要的是,它为我们揭示了一个全新的视角:时间,才是AI理解和重构视觉世界的深层密码。
这场“时间魔法”的施展,让AI从静态的图像中解放出来,学会了动态的演化规律,从而以更少的“教材”交出了“满分答卷”。这不仅是技术上的胜利,更是对AI学习范式的一次深刻反思。
未来,随着这种“时间先验”的智慧迁移在更多AI任务中得到应用,我们将看到一个更加智能、高效、且富有创造力的AI世界。它将不再是冰冷的算法,而是能够理解万物演变、洞察用户意图的“智慧之眼”,为人类开启前所未有的视觉内容创作与交互体验。但同时,我们也必须清醒地认识到,每一次技术飞跃,都伴随着伦理的挑战,唯有审慎前行,方能让AI的“时间魔法”真正造福人类,而非带来新的迷途。