对抗知识焦虑,从看懂这条开始
App 下载
GPT-6带200万token记忆,要做你的专属智能伙伴
专属智能伙伴|Big Model Smell|200万token上下文|Spud|GPT-6|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载专属智能伙伴|Big Model Smell|200万token上下文|Spud|GPT-6|大语言模型|人工智能
想象一下:你和AI聊到一半去忙别的,三天后回来它不仅记得你上周提到的项目 deadline,还能顺着你上次没说完的科研思路,把相关的10篇论文摘要、代码逻辑甚至实验方案调整建议一起递过来——不用你再重复半句背景。这不是科幻小说里的设定,而是代号“Spud”的GPT-6要实现的日常。它带着200万tokens的超大上下文窗口和被称为“Big Model Smell”的主动对齐能力,即将在4月中旬上线。但真正的变革,远不止“记得更多”这么简单。
你可以把大模型的上下文窗口想象成手机的运行内存——以前的模型只有“6G内存”,聊到第10轮就会把前面的对话挤出去;而GPT-6的200万tokens,相当于把内存直接拉到了“1T”。
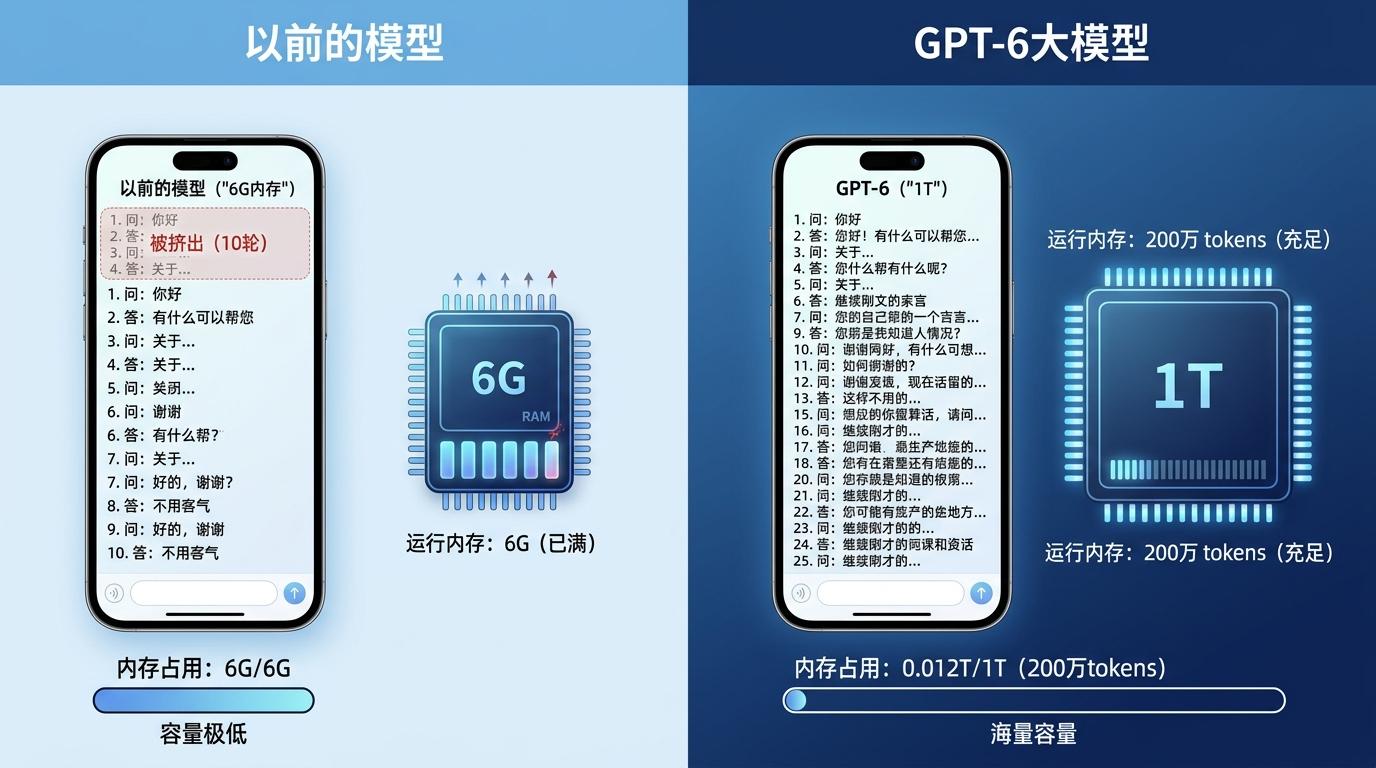
但真实的机制比这个类比更精确:它不是简单的“扩容”,而是重构了模型处理长文本的逻辑。传统模型在处理超过自身窗口的内容时,会像读一本书只能记住最后10页;GPT-6却能把整本书的逻辑脉络、细节关联甚至你在页边写的批注都留在“内存”里,需要时随时调取。比如处理一套10万行的代码库,它能直接定位某段函数的调用关系、历史修改记录,甚至预判你接下来要优化的模块——这是此前任何模型都做不到的。
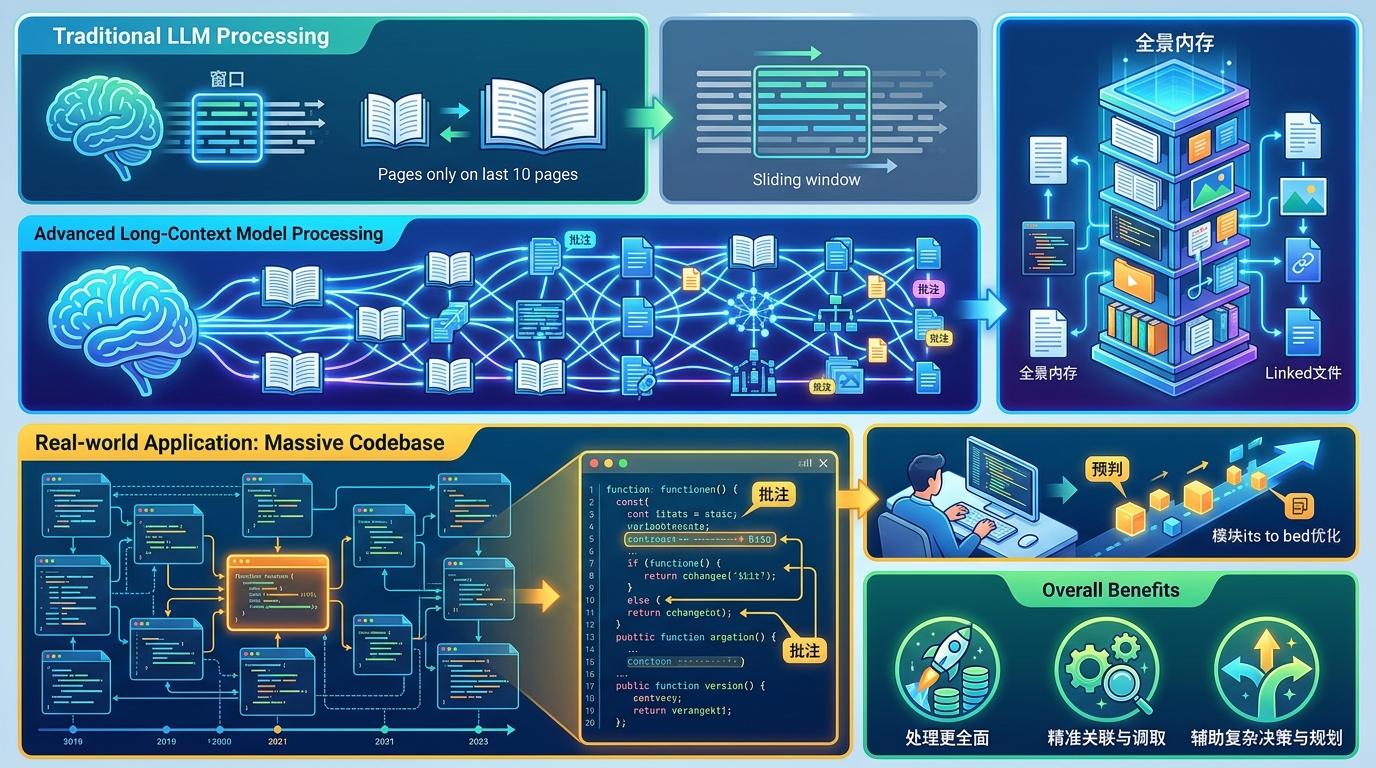
更关键的是,这个超大窗口不是为了“装更多文字”,而是为复杂推理搭建了舞台。它能在同一个上下文里完成“读文献→提假设→推公式→找漏洞”的全链条工作,不用像以前那样分多次对话、反复补充背景,推理效率直接提升40%以上。
奥特曼用“Big Model Smell”形容GPT-6,翻译过来就是——这个大模型终于有了“察言观色”的能力。
以前的AI像个听话但木讷的实习生:你说“帮我写个方案”,它就真的只写方案,不会问你是给客户看的内部版还是对外的宣讲版,也不会记得你上周说过“要突出成本控制”。但GPT-6的主动对齐机制,会把你过去的所有偏好、对话里的隐含需求,甚至你提问时的语气,都纳入“意图判断”。它会主动问:“你要的是10页的详细方案还是2页的精简版?要不要附上之前提到的成本对比表?”
这种能力的核心,是模型内部的自主对齐机制——它不再只靠人类标注的反馈来调整输出,而是能在对话中实时学习你的行为模式,甚至预判你的潜在需求。但这也带来了新的隐忧:它越懂你,就越需要处理好“懂”和“边界”的关系。比如它会不会过度解读你的需求?会不会把你随口说的一句抱怨当成正式指令?目前的测试数据显示,它的对齐准确率比前代提升了60%,但仍有12%的概率出现“过度脑补”的情况——这是未来需要持续优化的边界。
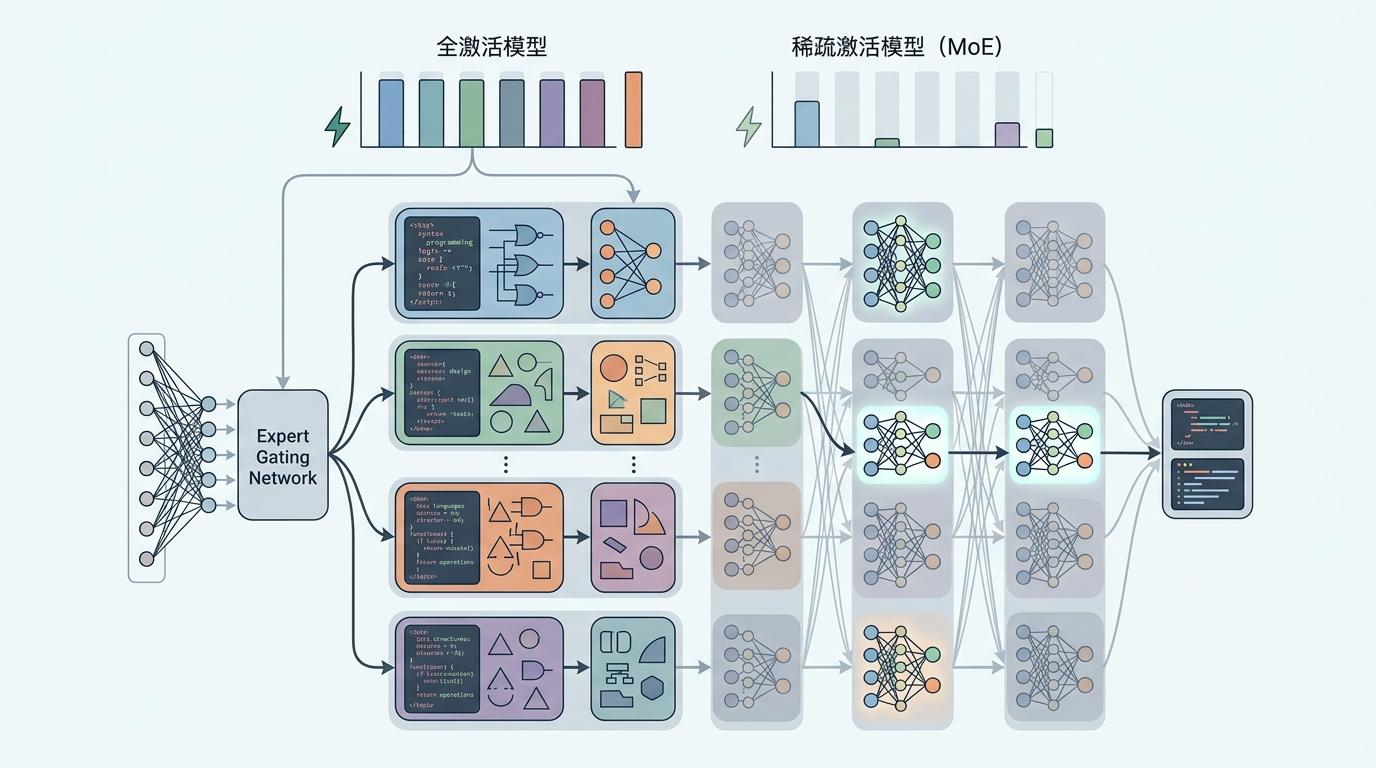
GPT-6的终极目标,是成为能统筹多任务的“超级智能体”——它不仅能聊天、写代码,还能调用图像生成、数据分析工具,甚至帮你规划一周的工作流程。而支撑这一切的,除了大窗口和主动对齐,还有混合专家架构(MoE)带来的效率革命。
你可以把MoE架构想象成一个有100个专家的团队:当你问代码问题,就只唤醒编程专家;问设计问题,就唤醒设计专家,不用让所有人都一起干活。这种“稀疏激活”的方式,让GPT-6在拥有万亿级参数的同时,把推理成本降低了30%——这意味着它能以可承受的成本,处理更复杂的多任务。
但它离真正的“通用智能体”还有距离。目前它的自主规划能力还局限在单一领域,跨领域的任务协同仍需要人类引导;而且它的“记忆”还只是被动存储,不会像人类一样对记忆进行整理、遗忘和提炼。这些未解决的问题,正是下一代智能体需要突破的方向。
当GPT-6带着200万token的记忆和主动对齐能力走来时,我们其实站在了一个拐点上:AI不再是需要你去“指挥”的工具,而是开始尝试理解你的“伙伴”。
这背后的逻辑,不是模型变“聪明”了,而是它终于学会了“把人放在中心”——不再让人类去适应模型的规则,而是模型主动适应人类的需求。但这种“适应”也需要边界:我们需要它懂我们,却不需要它“过度介入”;需要它主动帮忙,却不需要它替我们做决定。
智能的终极形态,从来不是机器像人,而是机器成为人的延伸。