对抗知识焦虑,从看懂这条开始
App 下载
谷歌扔了所有视觉AI专用工具,只用一个模型
计算机视觉任务|图像生成|通用视觉模型|何恺明|Vision Banana|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载计算机视觉任务|图像生成|通用视觉模型|何恺明|Vision Banana|多模态视觉|人工智能
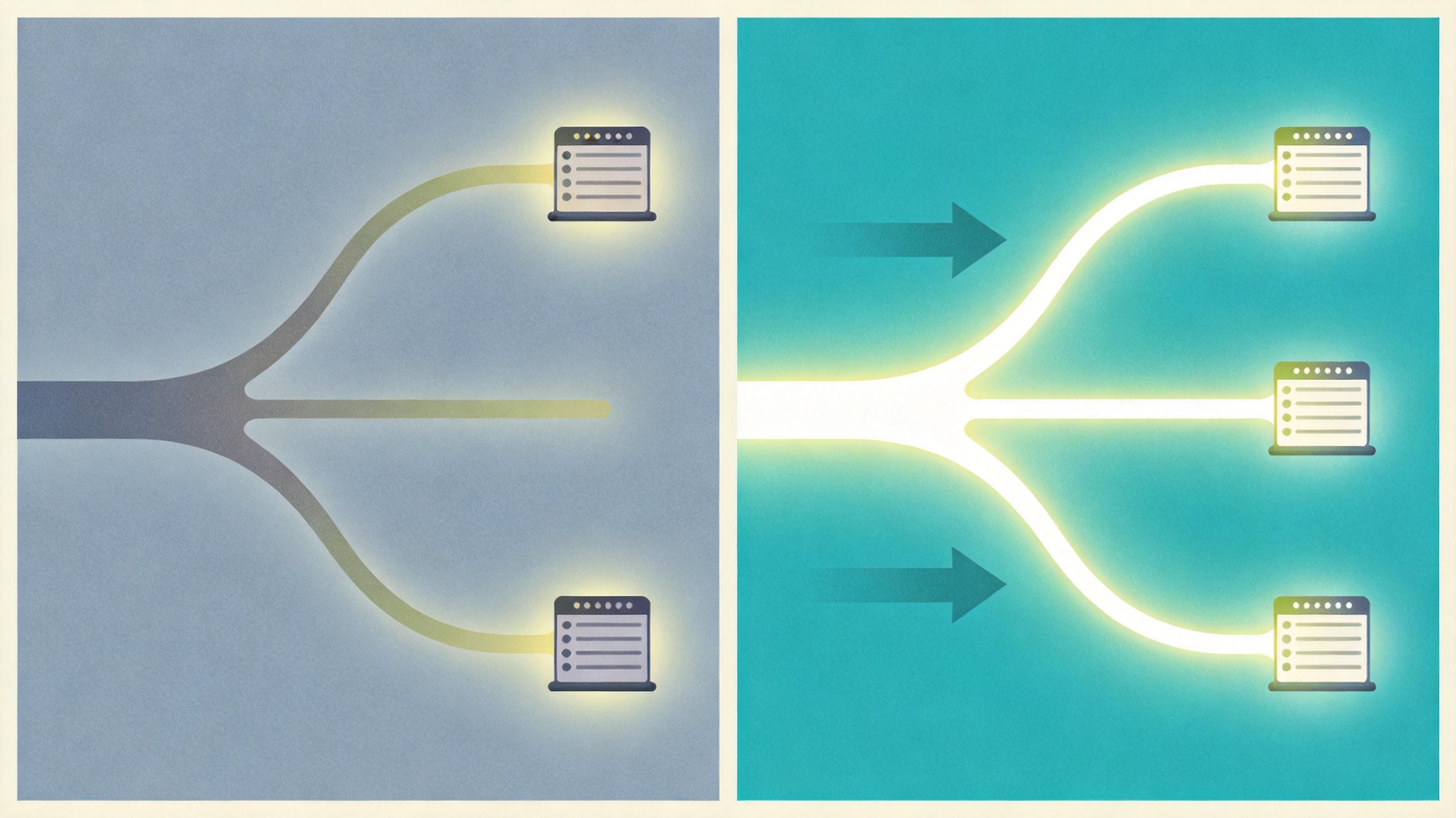
想象一下:你家里有十几把钥匙,分别开大门、卧室、书房、储物间——每加一个新房间,就得焊一把新钥匙。过去二十年,计算机视觉工程师干的就是这事:检测物体焊一把钥匙,分割图像焊一把,生成新图再焊一把。直到谷歌联合何恺明等一众顶级学者,把这些钥匙全扔进了垃圾桶。他们发布的Vision Banana,用一个模型搞定了所有视觉任务。更反常识的是,它靠「画画」学会了「看懂」——生成能力越强,理解精度反而越高。这到底是怎么做到的?
传统视觉AI的逻辑是「分而治之」:检测物体靠算框坐标,分割图像靠逐像素分类,生成图像靠去噪——三条线各有各的训练流程,各有各的排行榜。Vision Banana的逻辑完全反过来:不管你要检测、分割还是估算深度,答案都是一张图。
你可以把它想象成一个只会画画的天才:你让它「检测这张图里的猫」,它就画一张带黄色框的图;你让它「分割出所有树」,它就画一张树被涂成绿色的图;你让它「估算这场景的深度」,它就画一张用颜色代表远近的伪彩图。所有任务都被「伪装」成了绘画指令,而它的画笔,就是训练出来的生成能力。
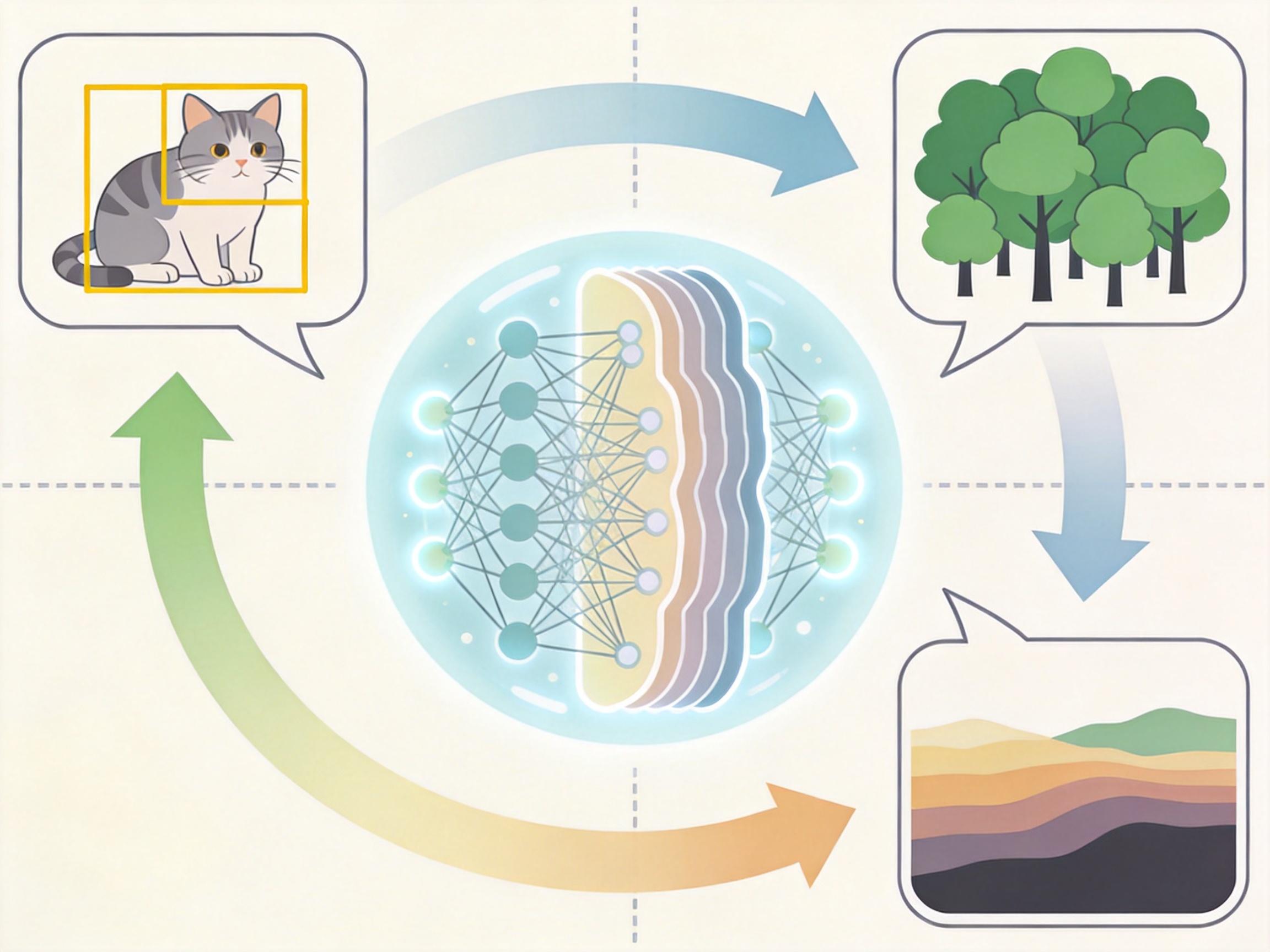
这背后的关键是**指令微调**——你可以理解成给这个天才画家上几节「命题画小课」。研究者只往它的训练数据里加了极少量「命题画」样本,比如「用红色框出汽车」的图,既没洗掉它原有的绘画天赋,又让它学会了把抽象的视觉任务,转化成具体的像素输出。
过去的常识是:理解是「压缩信息」,生成是「展开信息」,两者方向相反,不可能互相帮忙。但Vision Banana的实验数据推翻了这个结论:在语义分割任务上,它的准确率超过了专门训练的SAM 3;在深度估计上,它不需要相机参数,精度就打败了Depth Anything 3;更关键的是,它在文本生图和图像编辑任务上,还保持着和原模型几乎相当的胜率——它没因为学会「看懂」就忘了「怎么画」。
这背后的逻辑,和人类的视觉认知不谋而合:我们看到被半遮的椅子,会自动「脑补」出完整的椅子——这个脑补过程,就是一种生成。Vision Banana把这个直觉工程化了:它不是在「看」图像,而是在「想象」图像应该是什么样。当面对被遮挡的物体、模糊的细节时,它能靠生成能力补全信息,这是只会「看」的专用模型做不到的。
当然,它也有局限:生成的像素图需要额外解码才能得到深度、分割掩码等实用数据,在极端追求速度的场景,专用模型依然有优势。而且它的物理真实性还不够完美,偶尔会生成不符合现实逻辑的细节。
Vision Banana的野心,远不止是统一视觉任务。它指向的是一种全新的视觉AI:不再是「看图识字」的工具,而是具备「视觉想象力」的系统。
比如在自动驾驶场景,传统AI需要靠复杂的算法规划路径,而拥有Vision Banana能力的系统,只需要在脑中「生成」一段成功避开障碍的像素序列,再照着这段序列去行动;在机器人领域,它不用预先编程每一个动作,只需要「想象」自己拿到杯子的画面,就能反向推导出要做的动作。
这像极了NLP领域的Transformer时刻——2017年Transformer用一个模型统一了所有语言任务,现在Vision Banana要在视觉领域做同样的事。当它和谷歌的多模态模型打通,一个能理解又能想象的「世界模型」雏形就会出现:它不仅能看懂眼前的世界,还能预测、模拟甚至创造未发生的场景。
十年前,视觉工程师们为每一个新任务焊一条新流水线;十年后,一个模型用同一个动作回答所有视觉问题。这不是简单的技术整合,而是对「视觉智能到底是什么」的重新定义:最好的视觉模型,不是完美的分类器,而是拥有完美想象力的观察者。
生成即理解,想象即推理。未来的视觉AI,或许会像人类一样,靠「脑补」看懂整个世界。