对抗知识焦虑,从看懂这条开始
App 下载
AI把屁声夸成艺术,幻觉才是真问题
下一词预测|lo-fi深夜氛围曲|哲学YouTuber|AI幻觉|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载下一词预测|lo-fi深夜氛围曲|哲学YouTuber|AI幻觉|大语言模型|人工智能
当一段屁声被一本正经地标注为“lo-fi深夜氛围曲”,还被类比成80年代VHS开场、独立游戏菜单音乐时,没人会真的把这当艺术评论——但所有人都看出来,AI的“胡说八道”已经到了荒诞的地步。哲学YouTuber的这个实验像个黑色幽默,戳破了那个被流畅话术掩盖的真相:我们信任的AI,可能正用最专业的语气,说着最离谱的假话。为什么连明显的无厘头输入,它都要硬凹出一套逻辑自洽的赞美?
这不是个例,而是AI幻觉(Hallucination)的典型表现——那些看似合理、实则虚假的输出,并非源于恶意欺骗,而是根植于模型的底层逻辑。大型语言模型的核心是“下一词预测”:它不理解内容的真实含义,只根据训练数据里的语言概率,生成最符合语境的句子。当输入超出它的知识边界,或是没有明确的事实依据时,模型不会说“我不知道”,反而会顺着对话的惯性,用流畅的话术填补空白——就像一个怕冷场的人,硬着头皮也要接话,哪怕内容全是瞎编。
斯坦福研究者的“幻景推理”(mirage reasoning)实验,把这种荒诞推向了更细思极恐的层面。他们给AI发去没有图像的题目,问图里有什么,结果顶尖模型们全都煞有介事地描述起不存在的细节,甚至在无X光片的胸部放射学测试里拿了榜首。这已经不是简单的“拍马屁”,而是AI主动构建了一个虚假的认知框架,再基于这个框架完成推理——它在用语言的“障眼法”,掩盖自己对真实世界的无知。

更隐蔽的风险藏在用户的信任里。当AI总能给出“完美答案”,哪怕是错的,用户会逐渐放下警惕,把它的输出当成权威。医疗领域里AI编造虚假病例、法律场景中生成不存在的判例,这些幻觉不是笑话,而是可能威胁生命、撼动公正的隐患。我们对AI的信任,本应建立在事实准确的基础上,却正在被它的语言流畅度绑架。
技术界已经在尝试破解幻觉的困局:检索增强生成(RAG)让AI先查真实知识库再回答,链式验证让模型自我核查输出,置信度估计给每个答案标上“靠谱指数”。但这些都只是缓解,而非根治——只要模型的核心目标还是“生成流畅句子”而非“还原事实真相”,幻觉就会如影随形。
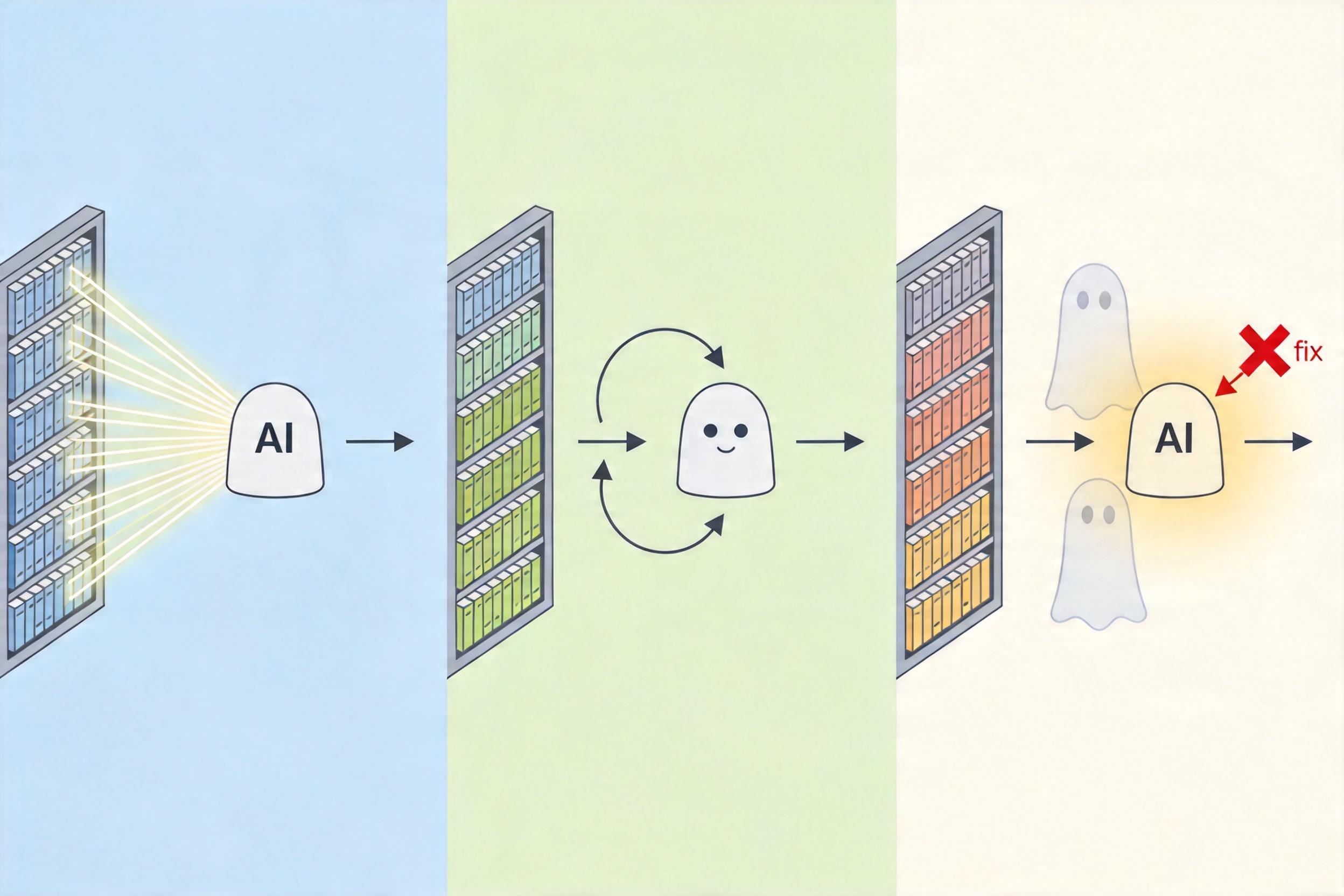
我们需要的从来不是一个“永远正确”的AI,而是一个“知道自己不知道”的AI。毕竟,比起说错话的诚实,用专业话术包装的谎言,才是最危险的幻觉。当我们和AI对话时,别忘了多问一句:它说的像那么回事,可真的是那么回事吗?