对抗知识焦虑,从看懂这条开始
App 下载
L4自动驾驶不只是开车,是在造数字劳动力
数字劳动力|AI司机|自动驾驶拖拉机|乌鲁木齐机场|L4级自动驾驶|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数字劳动力|AI司机|自动驾驶拖拉机|乌鲁木齐机场|L4级自动驾驶|自动驾驶|人工智能
乌鲁木齐机场的停机坪上,曾经凌晨3点就要顶着风雪上岗的老司机,如今坐在监控室里盯着屏幕——他不用再握着方向盘重复跑运输,只需要偶尔处理系统预警,剩下的全交给自动驾驶车辆。同样的场景也出现在新疆的农牧场:自动驾驶拖拉机在非铺装路面上精准作业,减少了91%的人猪接触,把疫病传播风险压到最低。这些不是科幻片里的镜头,而是L4级自动驾驶落地后的真实日常。当行业还在争论Robotaxi何时普及,一批技术团队已经把「AI司机」塞进了机场、厂区、港口甚至农田,让无人驾驶从「炫技」变成了能算账的生产力。
全场景L4自动驾驶,本质是让一套算法能像人类司机一样,在机场、厂区、农田等完全不同的环境里灵活切换——这背后的关键是跨场景迁移技术。你可以把它理解成:一个会开城市出租车的司机,不用重新考驾照,就能快速上手开矿区卡车、机场摆渡车。
实现这种迁移,首先要搭建一套统一的技术底座:用模块化的软硬件架构,把感知、决策、控制等核心功能拆成可复用的模块,再搭配场景参数模板——就像给不同场景准备好「驾驶手册」,系统能自动读取场景里的道路规则、障碍类型,调整驾驶策略。比如在机场,系统会优先识别行李拖车和停机坪标线;到了农田,就自动切换成识别非铺装路面和农作物的模式。
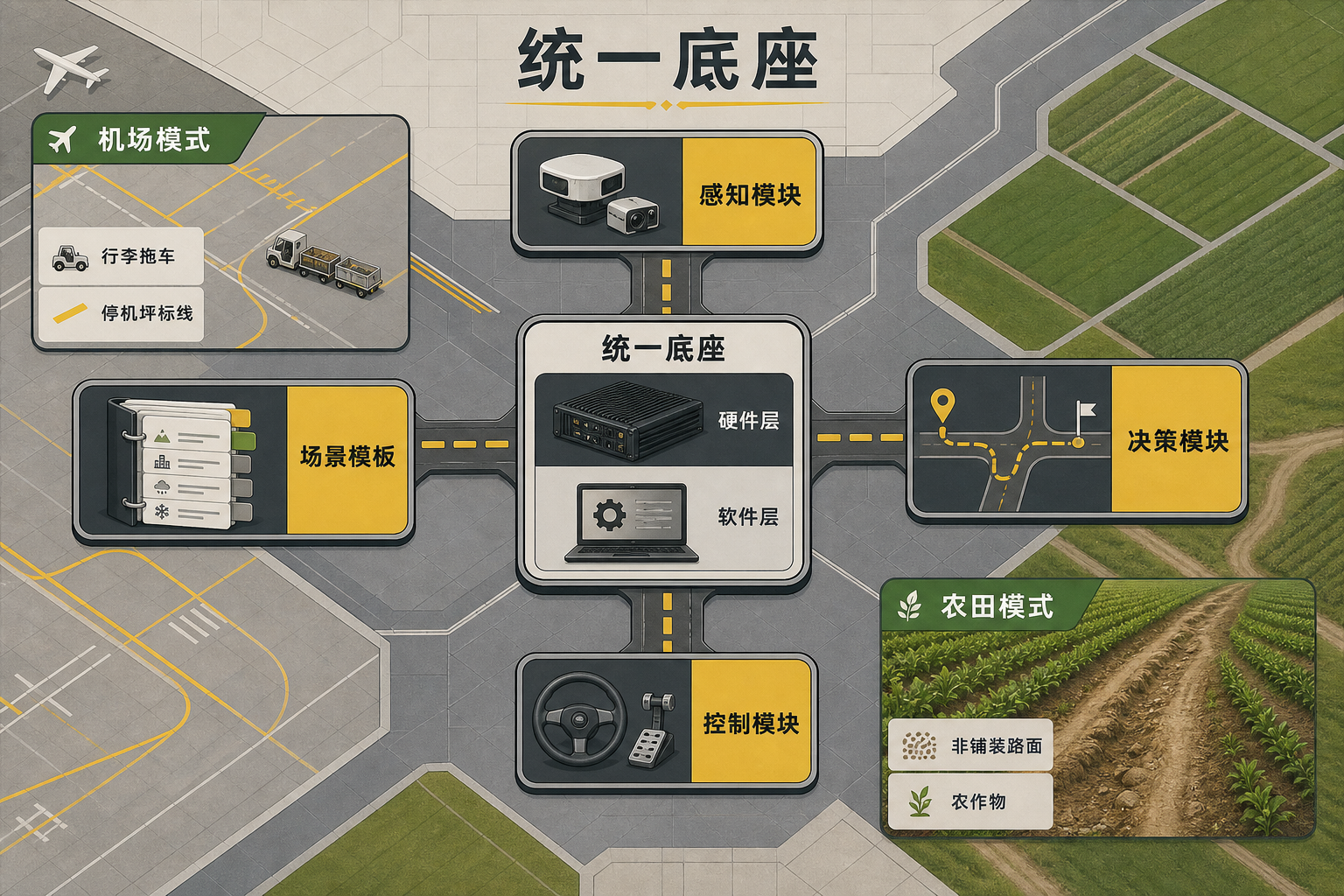
还有更关键的一步:用自动化工具链把适配成本打下来。传统的自动驾驶方案,每进入一个新场景就要重新训练模型、调试硬件,成本高得离谱。而现在的技术可以通过算法库自动匹配场景,再用自动化测试快速验证,把新场景的适配周期从几个月压缩到几周。
如果说统一底座解决了「能开车」的问题,那视觉-语言模型(VLM)和世界模型就是让AI司机「会思考」的关键。
视觉-语言模型相当于给AI装上了「会读题的眼睛」——它不仅能看到交通标志,还能理解标志上的文字含义,甚至能读懂场景里的隐性规则:比如看到机场的「禁止驶入」牌,它不会只识别图形,还能理解这是针对特定车辆的禁令。而世界模型则是AI的「大脑模拟器」,它能像人类一样预判环境变化:看到路边的行人抬手,就知道对方可能要过马路,提前减速避让。
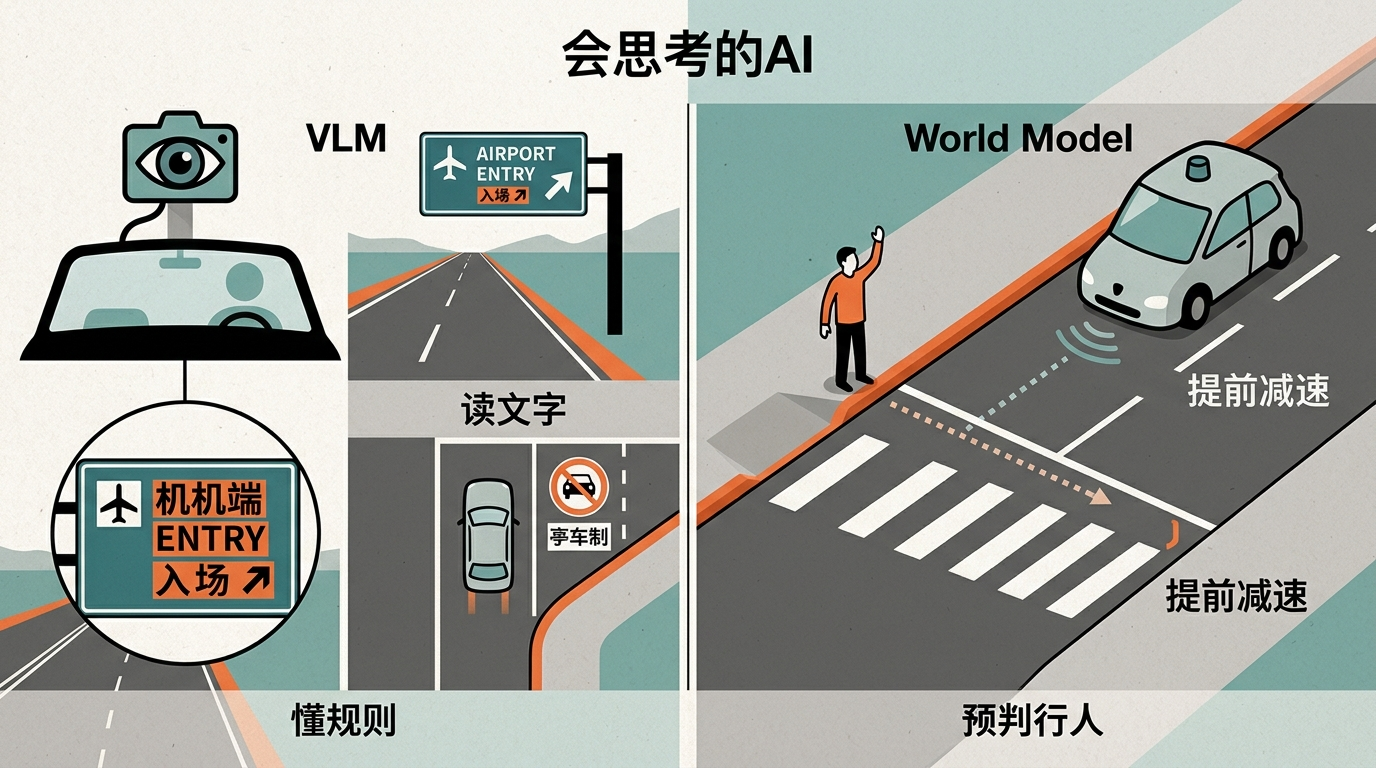
最新的技术还用上了高斯过程的概率模型,让AI能判断自己的「不确定」——遇到没见过的极端场景,比如被洪水冲毁的路面,系统会主动触发远程人工干预,而不是硬着头皮往前开。这解决了自动驾驶最头疼的「长尾场景」问题:毕竟人类司机也会遇到从没见过的路况,关键是知道什么时候该求助。
很多人担心自动驾驶会抢了司机的饭碗,但从实际落地的案例看,它更像是在重塑劳动力结构。乌鲁木齐机场的老司机没有失业,而是转型成了无人车管理员,负责监控系统、处理突发情况,工作强度降低了,收入反而提高了。数据显示,采用人机协作模式的企业,员工满意度提升了10%,离职率下降了5%-8%。
但这种协作也有边界。麻省理工的研究发现,如果AI和人类的切换不顺畅,反而会增加事故风险——比如AI突然把控制权交还给人类,而人类还没反应过来。所以现在的技术会提前设置「接管预警」,给人类留出足够的反应时间,甚至在设计系统时,就明确哪些场景交给AI,哪些必须人类介入。
更重要的是,数字劳动力的出现催生了新岗位:自动驾驶系统维护工程师、数据标注师、远程监控操作员……这些岗位的数量,可能会超过被替代的传统司机岗位。
当我们谈论自动驾驶时,我们其实在谈论的是「如何用技术解放劳动力」——不是把人从岗位上赶走,而是把人从重复、危险、高强度的工作中解放出来,去做更有创造性的事。
全场景L4的真正意义,从来不是「车里没有司机」,而是「让司机不用再做司机的活」。未来的交通场景里,AI会成为最靠谱的「老司机」,而人类则会变成AI的「合作伙伴」。这不是技术对人的替代,而是技术与人的共生。