对抗知识焦虑,从看懂这条开始
App 下载
给AI装个“指挥大脑”,破局图像修复瓶颈
画质评分提升|图像修复技术|华为团队|哈尔滨工业大学|OPERA系统|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载画质评分提升|图像修复技术|华为团队|哈尔滨工业大学|OPERA系统|多模态视觉|人工智能
你有没有过这种经历:翻出一张十年前的雨夜街景照,想修复清楚却屡屡失败——模糊的雨丝、低光的噪点、远处的雾霾像一群“捣蛋鬼”抱团搞破坏,用去噪工具会磨掉细节,用去雾工具又会加重模糊。过去的AI修复要么是“万金油”啥都修不好,要么是“工具堆叠”各干各的,最后效果总差一口气。直到哈尔滨工业大学和华为的团队拿出了OPERA:它给AI装了个会全局规划的“指挥大脑”,还让所有修复工具学会了“团队协作”,在复杂混合退化图像上,直接把画质评分拉高了4个dB——这相当于把一张勉强能看的照片,变成了能放大当壁纸的高清图。
过去的AI图像修复智能体,更像个只会按清单做事的实习生:检测到噪声就调用去噪工具,看到模糊就调用去模糊工具,一步一步走,永远看不到全局最优解。甚至有些工具之间还会“拖后腿”——前一个工具输出的图像,数据格式和后一个工具的“预期输入”完全不匹配,导致修复效果打折。
OPERA的第一个突破,就是把“分步走”的贪心决策,改成了“一次生成完整方案”的全局规划。它用了一种叫GRPO的强化学习算法,让AI在340种可能的工具组合里自己试错、找最优解。你可以把这个过程想象成:让一个厨师直接规划出一整桌宴席的菜单,而不是一道菜一道菜临时想。
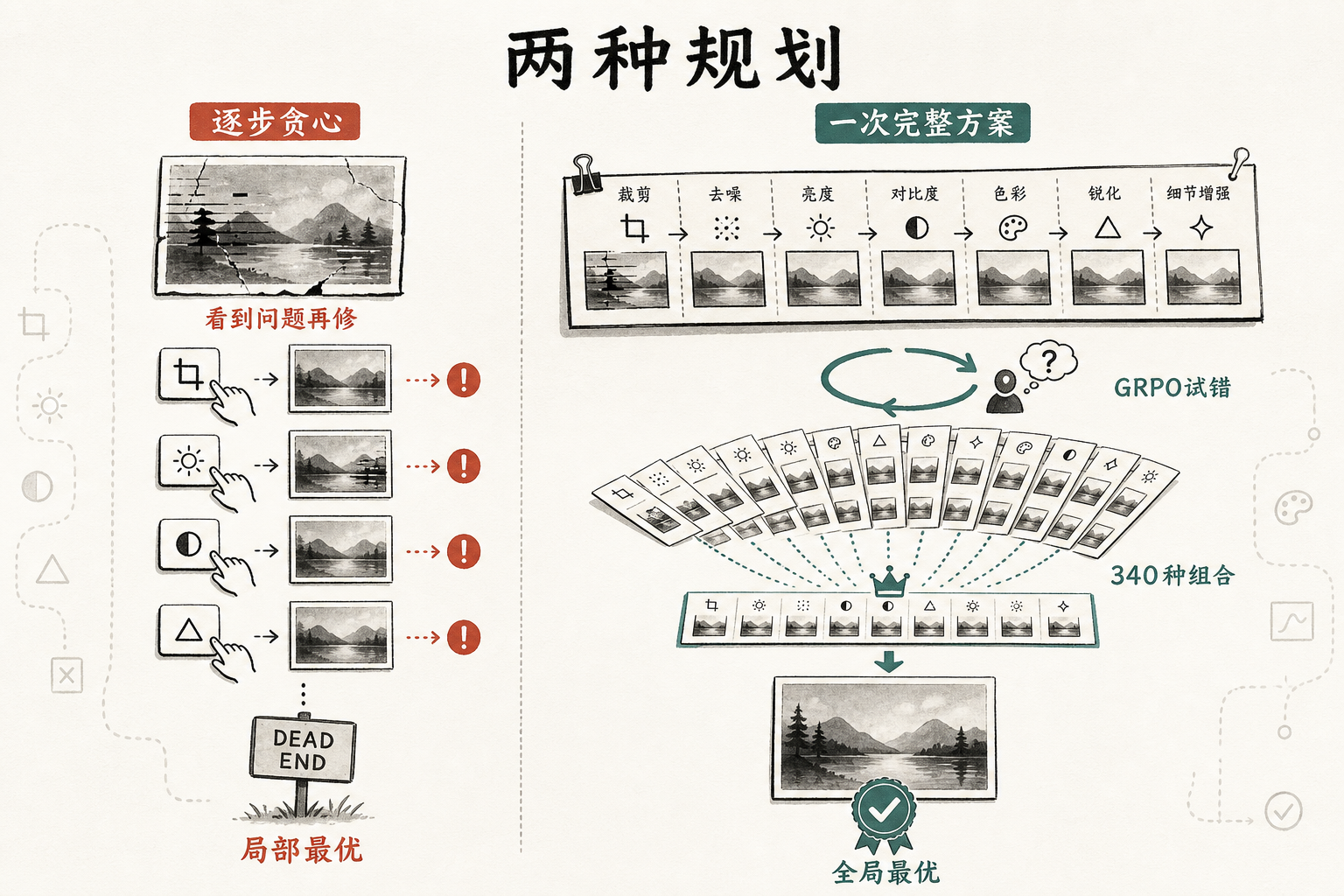
GRPO的聪明之处在于,它不用单独训练一个“评委模型”来打分,而是让AI针对同一张图生成多个修复方案,再对比这些方案的相对好坏来调整策略。比如AI生成了三个方案:方案A只调用去噪和去雾,方案B加了一次去模糊,方案C重复用了两次去噪,对比后发现方案C效果最好,AI就会记住“重复去噪”这个策略。这种“组内对比”的方式,不仅省了一半的计算资源,还能更快找到人类想不到的“野路子”——比如给没有噪声的图用去噪工具,反而能让后续的去模糊效果更好。
光有好规划还不够,要是每个工具还是“各玩各的”,照样出不了好活。OPERA的第二个大招,就是让所有修复工具在“指挥大脑”的监督下联合训练,学会适应彼此的输出。
传统的修复工具都是单独训练的:去噪工具只见过带噪声的图,去雾工具只见过带雾霾的图,一旦把它们串起来用,前一个工具输出的图,对后一个工具来说就像“外星图像”。OPERA的做法是,用AI规划出的工具序列当“剧本”,让所有工具跟着剧本一起练:去噪工具知道后面要接去模糊,就会刻意保留一些边缘细节;去模糊工具知道前面是去噪后的图,就会调整参数适应稍微平滑的输入。
训练的时候,整个工具链的参数会一起更新——就像一支乐队跟着指挥一起排练,不是每个乐手自己练自己的,而是听着整体的声音调整自己的节奏。最终的损失函数也像一杯“鸡尾酒”:既有保证像素准确的L1损失,又有保证视觉效果的感知损失,还有基于AI审美判断的无参考质量损失。而且训练初期先让工具专注于“把图修清楚”,再慢慢过渡到“把图修好看”,整个过程稳扎稳打。
结果就是,OPERA只用了16个工具,就打败了用39个工具的4KAgent。在最复杂的三退化场景下,它的PSNR(画质评分)比第二名高了3.27个dB——这意味着图像的细节还原度提升了近40%。

当然,OPERA也不是没有局限。它的“指挥大脑”基于7B参数的视觉语言模型,推理一次需要的计算资源不小,暂时还做不到手机端的实时修复;而且它的训练数据还是以合成退化为主,面对真实世界里那些“千奇百怪”的图像损伤,比如老照片的折痕、水渍,还有待进一步优化。
更值得关注的是,OPERA的思路其实可以用到更多领域:比如视频修复,让AI规划出“先去抖、再去噪、最后补帧”的最优序列;比如医学影像修复,让不同的病灶检测工具学会协同工作。它真正的价值,不是修好了几张图,而是证明了“智能体+联合优化”的思路,能打破过去“工具堆叠”的天花板。
我们总说AI要“像人一样思考”,但很多时候,我们只让AI学会了“像人一样做事”——一个步骤接一个步骤,却忘了人做事之前会先“全局规划”,会“团队协作”。OPERA让我们看到,给AI一个“指挥大脑”,让工具之间学会配合,能爆发出多大的能量。
未来的图像修复,可能不再是“用什么工具修什么问题”,而是“AI直接给你一个最优的修复方案”。就像你去餐厅不用自己点菜,厨师会根据你的口味和食材情况,直接给你上一桌最适合的菜。
好的AI,不是工具的堆叠,而是协作的指挥。