
19 小时前
19 小时前
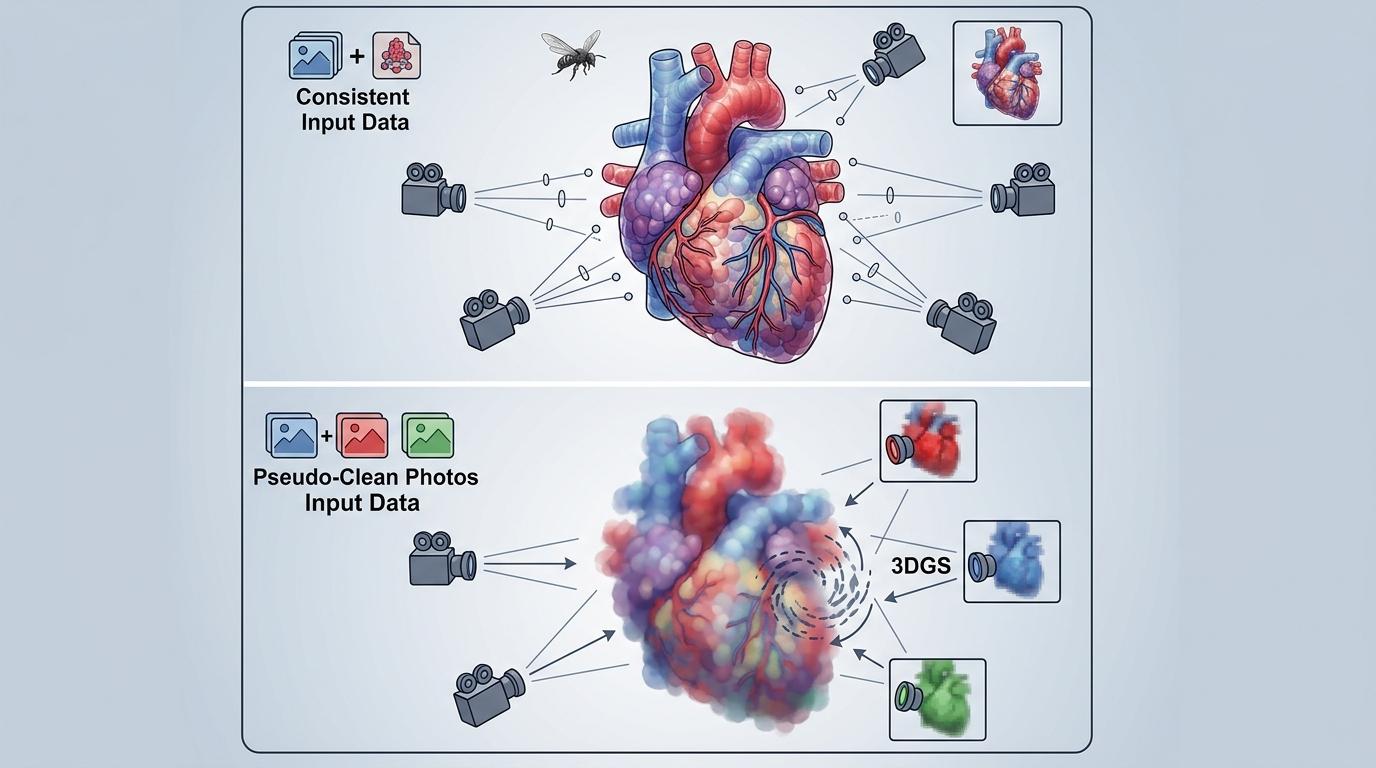
想象你在浓雾里绕着一尊雕塑拍了十张照片——每张单独去雾后都清晰锐利,可当你想用它们重建3D模型时,雕塑的鼻子在左视图里偏红,右视图里却偏黄,树叶的纹理更是每张都不一样。这不是你的拍摄失误,而是3D重建领域悬了多年的死结:单张图片的修复质量,和多视角之间的结构一致性,天生就是一对冤家。华中科技大学与香港科技大学(广州)的团队,用一套看似简单的两阶段方案,把这个死结给解开了。
你可以把3D重建理解成用多视角照片拼3D积木——每张照片都是积木的一个侧面。过去的做法要么是先把每张照片都修到最清晰,结果各侧面颜色纹理对不上,拼出来的积木歪歪扭扭;要么是强行让所有照片保持一致,结果每张都修得模糊不清。
这个团队反其道而行之:第一阶段就把单图去雾做到极致。他们调用了谷歌Gemini系列的生成模型,给每张烟雾照片独立“美颜”,单帧去雾的峰值信噪比(PSNR)达到20.07dB——这意味着单看每张图,几乎和无雾的真实场景没差。但代价也很明显:不同视角的照片亮度能差出0.12,就像有的在正午拍,有的在傍晚拍。
于是他们加了关键一步:亮度标准化。把所有照片的亮度、颜色分布对齐到同一个基准——有真实无雾图就对齐真实图,没有就取所有照片的中间值。这就像给所有积木刷上了统一底色,虽然局部纹理还略有差异,但至少不会出现“一半黄一半红”的尴尬。
接下来是第二阶段:用3D高斯泼溅渲染(3DGS)拼积木。这是近年大火的3D重建技术——简单说就是用成千上万个带颜色和透明度的3D“高斯球”当积木,快速拼出高质量的3D场景。但如果直接把第一阶段的“伪干净”照片喂进去,3DGS会彻底懵圈:同一个3D点,不同视角给的颜色不一样,它只能取平均值,结果拼出来的场景模糊得像打了马赛克。
团队的妙招是给3DGS套上三个“物理紧箍咒”:
第一个是深度监督损失。他们用对烟雾鲁棒的深度估计模型,从原始烟雾图(不是去雾后的图)里算出场景的“骨架”——伪深度图,要求3DGS拼出的场景骨架必须和这个伪深度图高度匹配。这就像先搭好积木的钢筋骨架,再往上贴颜色,不管颜色怎么变,骨架不会歪。
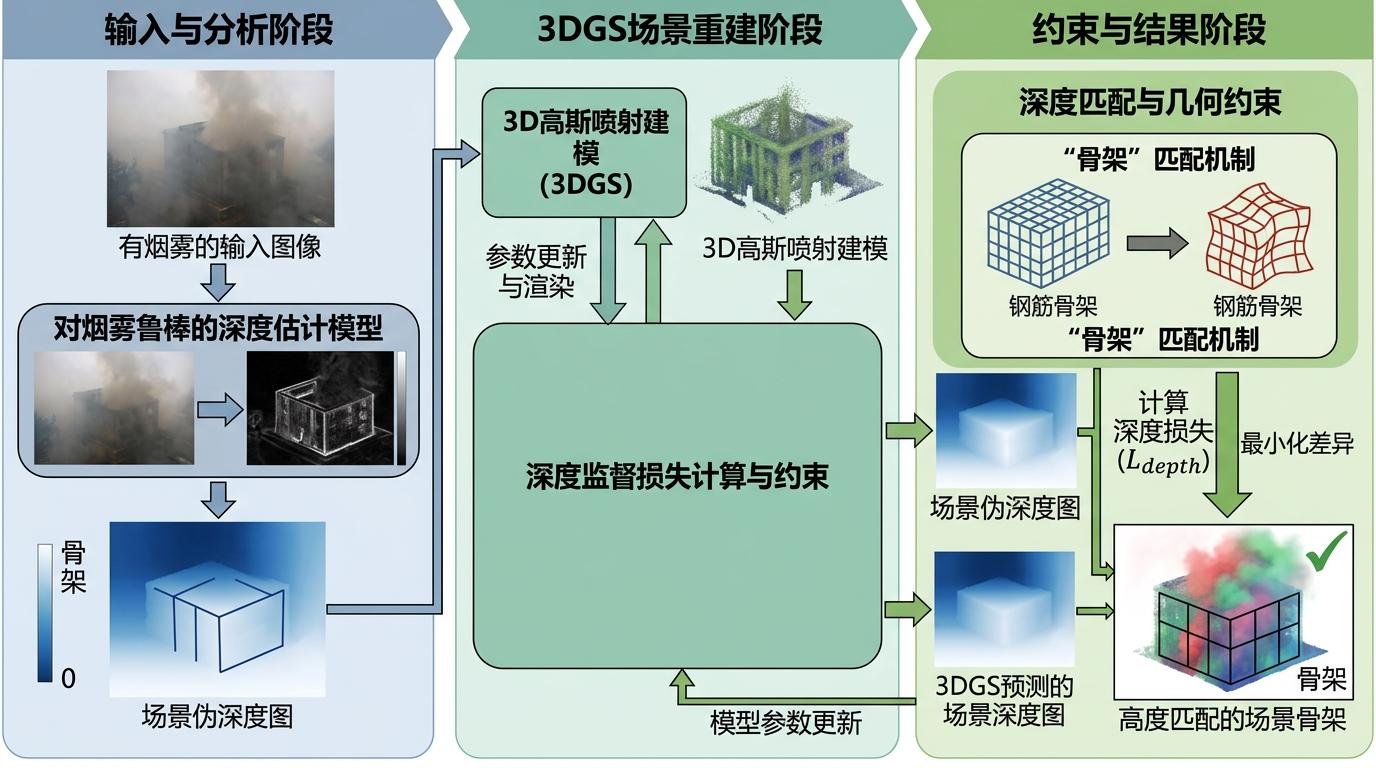
第二个是暗通道先验正则化。这是去雾领域的经典物理规则:无雾的清晰图像里,每个局部小块总有一个颜色通道接近黑色。他们用这个规则约束3DGS,一旦渲染出的图像局部不够暗,就惩罚模型,逼它把残留的雾效彻底去掉。
第三个是双源梯度匹配损失。虽然不同视角的颜色可能不一样,但物体的边缘轮廓是一致的。他们用另一款去雾模型的输出当“素描稿”,要求3DGS渲染出的边缘必须和素描稿对齐,保住场景的细节骨架。
更绝的是训练策略:他们发现如果让3DGS的高斯球数量无限制增长,模型会“死记硬背”每张图的局部差异,反而拼不出统一的场景。于是他们提前停止增加高斯球,用MCMC(马尔可夫链蒙特卡洛)策略动态调整高斯球的密度——就像只给模型刚好够拼场景的积木,逼它去学通用的3D结构,而不是纠结局部的颜色差异。
在Akikaze验证集的测试里,这套“先除雾后泼溅”方案的PSNR达到20.98dB,比没有物理约束的基线方法整整高了1.5dB——在图像质量评价里,超过1dB的提升就是质的飞跃。
你能直观看到差异:基线方法渲染出的场景模糊偏色,玩偶的面部细节几乎看不见;而这套方案渲染出的场景,颜色和真实场景几乎一致,棋盘格的纹理、玩偶的睫毛都清晰可见。更有意思的是,团队尝试过去做端到端的模型——把去雾和3D重建合在一起训练,结果PSNR只有10.28dB,几乎是“五彩斑斓的垃圾”。这恰恰证明了他们的判断:单图去雾和多视角一致性,根本没法在同一个模型里兼顾,分阶段处理才是最优解。
当然,这套方案也有局限:它依赖外部生成模型的API,成本和稳定性都是问题;针对不同烟雾密度、不同场景,超参数还得手动微调。但不可否认的是,它精准命中了3D重建领域的核心矛盾,给出了一套务实、可复现的解决方案。
当我们为AI的“端到端魔法”欢呼时,这套“先除雾后泼溅”方案像一个冷静的提醒:有时候,把复杂问题拆成两步,用最成熟的工具解决每一步,再用物理规则把它们粘起来,反而比追求“大一统”的模型更有效。
分而治之,用规则弥合矛盾。这句话不仅适用于3D重建,也适用于很多看似无解的技术难题。未来,我们或许能看到更聪明的模型——既能把单图修得清晰,又能自动保持多视角一致,但在那之前,这套方案已经给了我们一个足够好用的梯子,让我们能先爬上浓雾中的3D重建高地。
点击充电,成为大圆镜下一个视频选题!