对抗知识焦虑,从看懂这条开始
App 下载
自动驾驶终于解决了练得好却考砸的难题
训练考核脱节|端到端规划模型|清华大学团队|CLOVER框架|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载训练考核脱节|端到端规划模型|清华大学团队|CLOVER框架|自动驾驶|人工智能
想象你花了几个月练车,每一次都精准复刻教练的路线,倒库、侧方分毫不差,结果上了考场,考官却突然拿出一套全新的评分标准——不看你跟教练像不像,只看你会不会躲行人、能不能平稳过减速带。你大概率会挂科,而这正是过去十年端到端自动驾驶规划模型天天面对的困境:训练时模仿人类轨迹拿满分,上路时却因不符合安全规则被判不合格。直到清华大学团队拿出的CLOVER框架,给这个「练考脱节」的死局撬开了一道口子。
你可以把传统自动驾驶规划模型理解成一个只会死记硬背的考生:训练时,它的唯一目标是「和人类司机的轨迹一模一样」,就像照着教练的路线反复练习,把每一个转向、加速的时机都刻进参数里。但真正上路时,评判它的是一套叫PDMS的「考官规则」——要算有没有碰撞风险、会不会压车道线、加速够不够平稳,甚至还要看能不能高效抵达目的地。
这就形成了一个无解的悖论:跟着人类轨迹走,可能因为稍微偏离车道就丢分;而一条更安全的路线,却因为和人类轨迹差距大,在训练时会被当成错误答案修正。更糟的是,这类模型往往只会生成和人类轨迹类似的路线,遇到突发情况时,连备选方案都没有。比如在狭窄路段遇到违停车辆,人类司机会选择减速绕行或者停车等待,但模型可能只会死死盯着人类的「示范路线」,一头撞上去。
CLOVER的核心思路说起来很简单:既然练和考的标准不一样,那就让「考生」(生成器)和「考官」(评分器)通过真实路况的反馈形成闭环,一起进步。
它的训练分两步走:第一步先给考生「扩题库」——不再只模仿单条人类轨迹,而是生成一批「伪专家轨迹」,涵盖减速、绕行、停车等各种可能的合理操作,再用PDMS规则筛选出高分路线,让模型知道「原来这些做法也是对的」。这就像让考生提前熟悉所有可能的考场场景,而不是只练教练给的那一条路线。
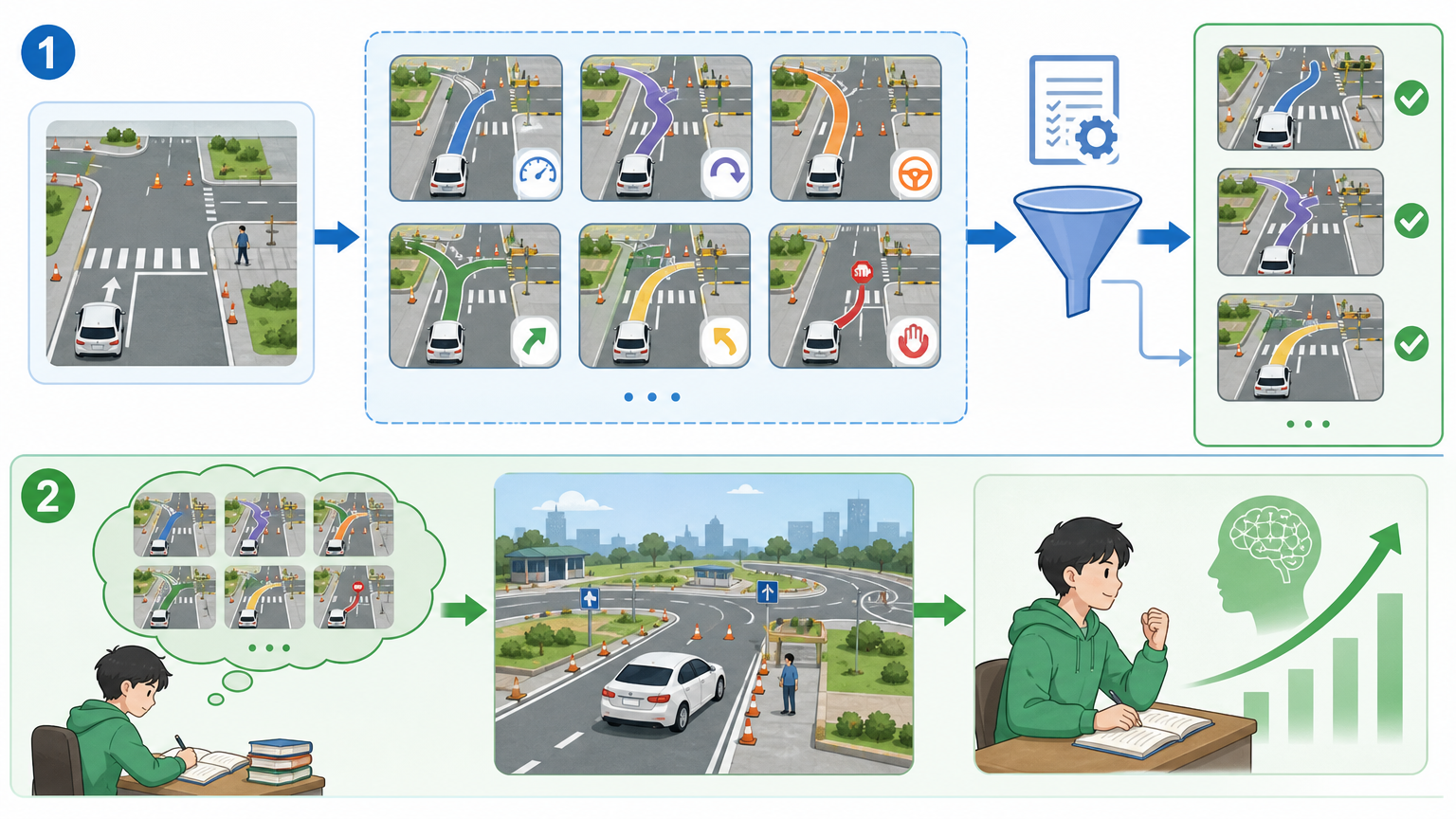
第二步是「保守自蒸馏」:先让评分器吃透PDMS的评分规则,学会给每一条路线打分;再让生成器跟着评分器的反馈慢慢调整,向高分路线靠拢,但又加上了「稳定性约束」——不能一下子改得太猛,避免偏离安全范围。就像考生根据考官的点评一点点调整答题思路,但不会彻底推翻之前的知识体系。
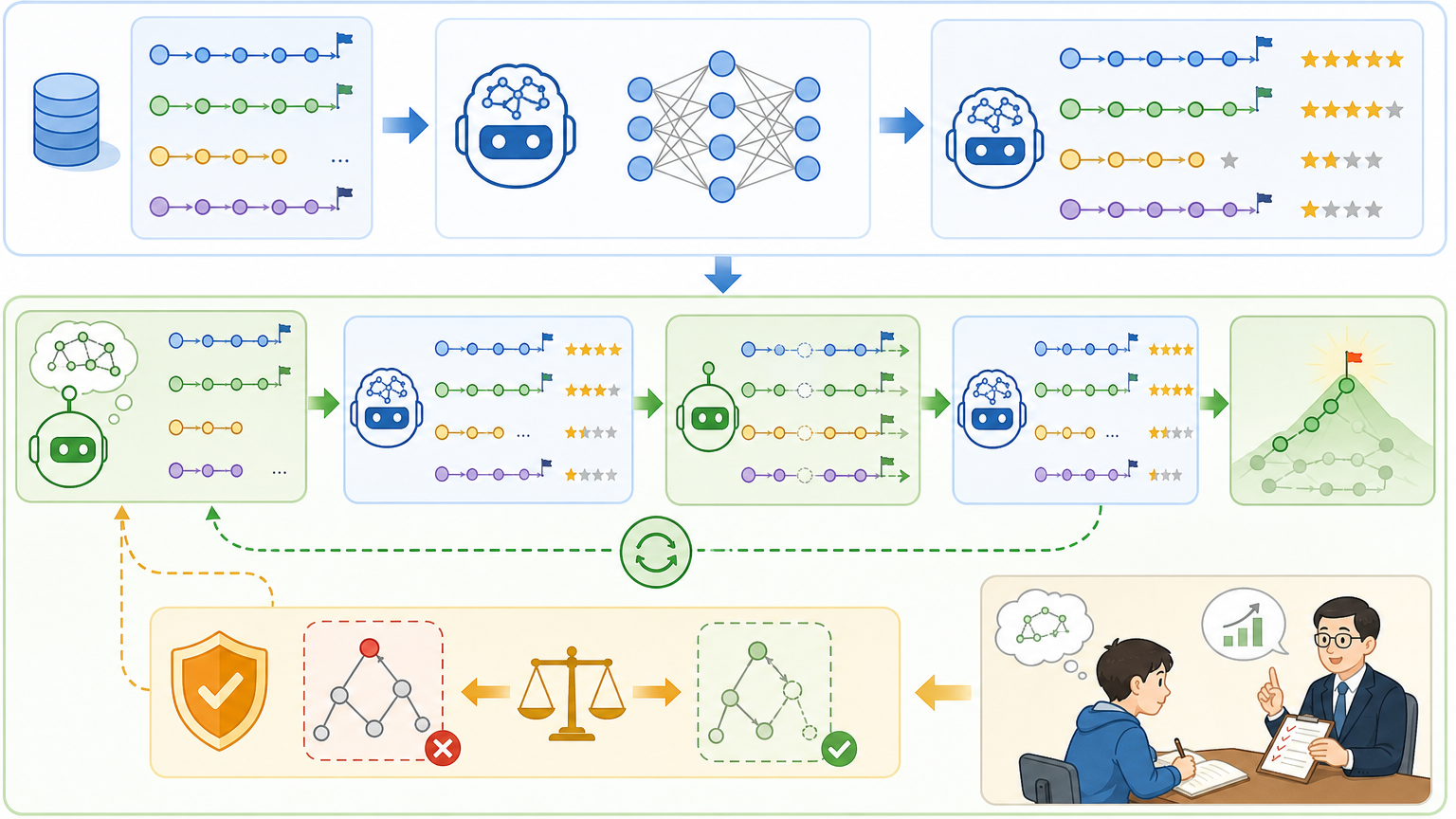
更聪明的是,CLOVER不需要评分器做到「绝对正确」。只要评分器选出的路线里,高分路线的比例比模型当前生成的高,模型就能稳步提升。这就像即使考官偶尔打错分,只要大部分时候能分清好坏,考生就能慢慢进步。
这套思路在实测中拿到了惊人的成绩:在NAVSIM这个主流自动驾驶测试基准上,CLOVER的PDMS评分达到了94.5,几乎追平人类司机的水平,比之前的最好成绩高出了近3分。在更复杂的「NavHard」困难场景测试中,它也拿到了和最强模型相当的分数。
消融实验的结果更能说明问题:只做第一步「扩题库」,模型的候选路线多样性提升了3倍多,但最终选出的路线质量并没有明显提升;加上第二步「保守自蒸馏」后,最终路线的PDMS评分一下子从82分涨到了94.5分,同时还保留了足够的多样性。也就是说,它既能想出多种应对方案,又能选出最好的那一个。

当然,CLOVER也不是完美的。它目前还依赖高精度的地图信息,如果在没有地图的陌生环境里,「伪专家轨迹」的生成就会遇到困难。而且训练时需要反复调用PDMS评分器,计算成本很高,一张A100显卡要跑4.5天才能完成训练。
CLOVER的意义,不止是刷新了几个测试基准的记录,更在于它给自动驾驶的「练考脱节」问题提供了一套可落地的解决方案。过去,我们总在纠结是让模型更像人类,还是更遵守规则,而CLOVER告诉我们:不用二选一,让模型在规则的反馈里慢慢靠近人类的驾驶智慧就好。
从只会死记硬背的考生,到能灵活应对各种场景的司机,自动驾驶终于迈出了从「模仿」到「理解」的关键一步。毕竟,驾驶的本质从来不是复刻某条路线,而是在复杂路况中做出最合理的选择——练得像人不重要,做得对才重要。