
1 个月前
1 个月前
当GPT-4o在MMLU这类主流AI测试上拿到90%+的准确率时,有人欢呼AI已经追上人类,有人却在背后捏了把汗——这些曾经用来衡量AI能力的标尺,正在变成AI的“刷分题库”。2026年初,一份由全球1000多名专家耗时18个月打造的“人类终极考卷”(HLE)被摆到了所有顶尖AI面前:2500道横跨100多个学科的专家级难题,连Google搜索都找不到标准答案。最先进的Gemini 3.1 Pro只考了44.7%,GPT-5.4也不过41.6%,而人类专家的平均得分是90%。这不是为了难倒AI,而是为了回答一个越来越紧迫的问题:当AI能轻松“考高分”时,我们该怎么知道它到底会什么?
你可以把传统AI测试想象成高中模拟卷——题目都是课本里的基础题,刷多了总能考高分。但HLE的诞生,是直接把博士生资格考试的真题搬了过来,而且还加了一道筛选门槛:先让当前最顶尖的AI挨个答题,但凡能被答对的题目,直接从题库里删掉。
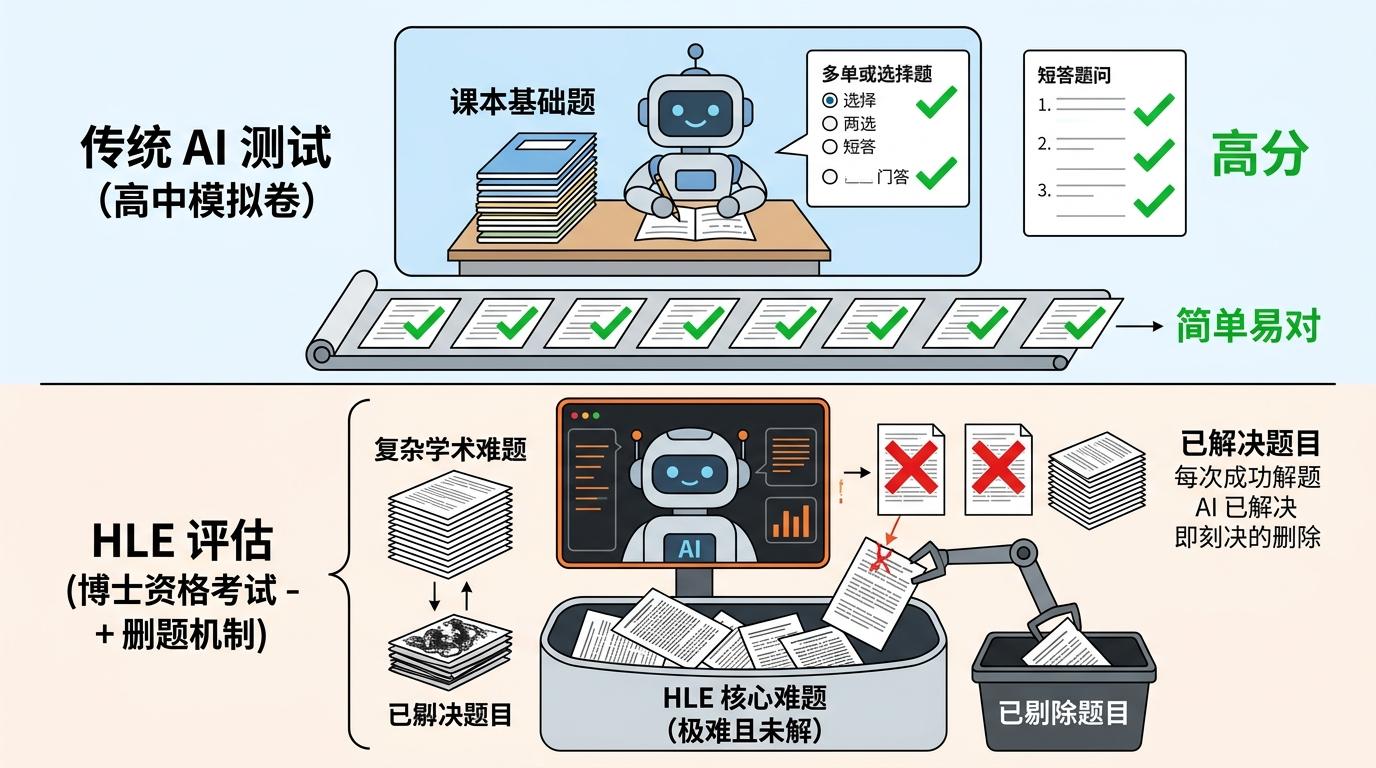
初始的7万道征集题,先经过一轮AI“淘汰赛”:GPT-4o、Claude 3.5这些能在传统测试拿满分的模型,只要能答对某道题,这道题就被判定为“难度不足”。剩下的题目再进入两轮人工评审:由拥有硕士以上学历的学科专家逐一验证,确保题目没有歧义、答案唯一,而且绝对不能靠搜索直接找到。最终2500道题被选中,其中41%是数学题,11%是生物医学题,还有14%是需要看图分析的多模态题——比如MIT专家出的那道蜂鸟骨骼题,要说出某块骨骼支撑的肌腱数量,翻遍普通百科都找不到答案。
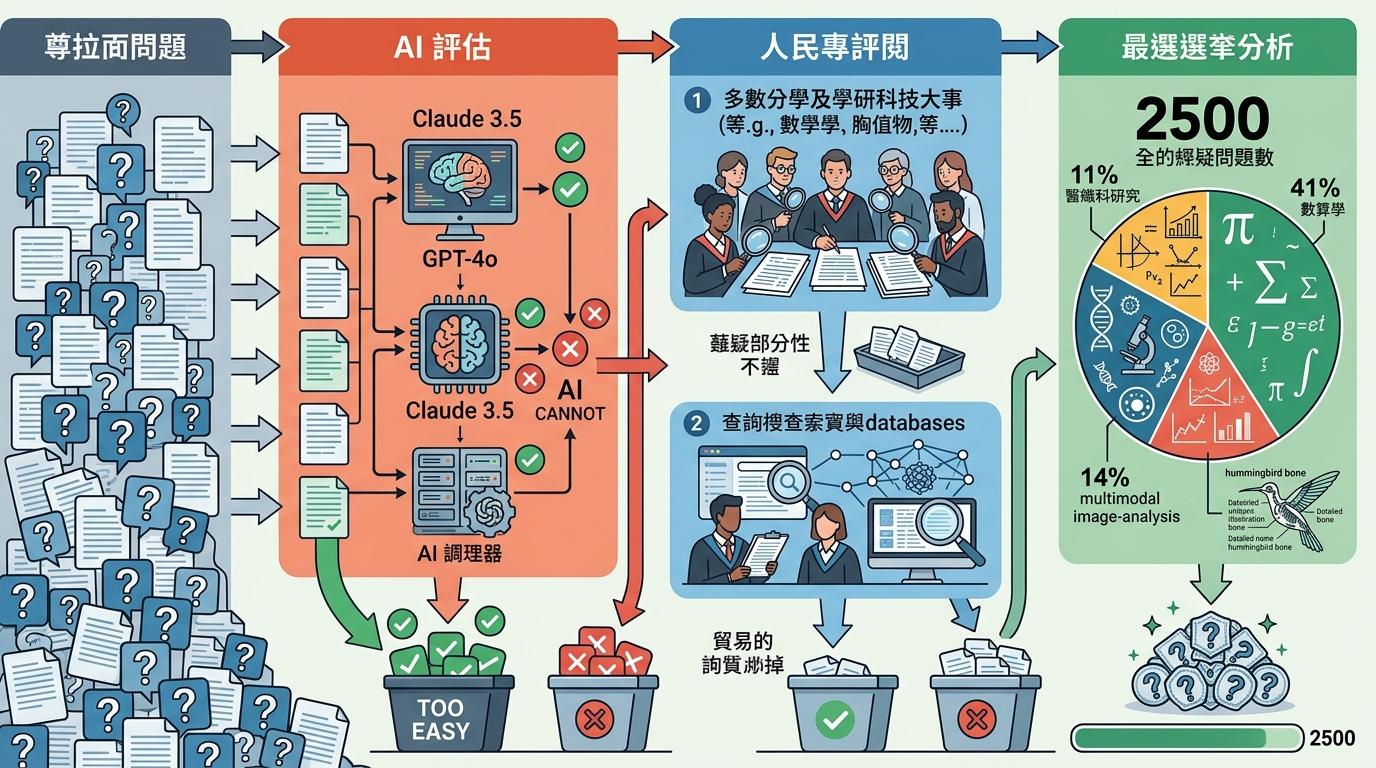
这个筛选逻辑像极了体育赛事的资格赛:只有连卫冕冠军都闯不过的关卡,才有资格成为新的比赛场地。
当GPT-4o在HLE上只拿到2.7%的准确率时,没人觉得意外——真正值得注意的是,AI答错的方式。它会用100%的自信给出错误答案,比如把蜂鸟的肌腱数量答成3,而正确答案是2。这种“迷之自信”不是个别现象,所有顶尖AI在HLE上的置信度校准误差都超过70%,说白了就是“不知道自己不知道”。
这背后是AI的本质缺陷:它靠统计规律和数据记忆答题,而非真正的理解。传统测试的题目大多是训练数据里见过的“熟面孔”,AI能靠模式匹配拿高分;但HLE的题目是专家原创的“新题”,没有现成的统计规律可套,AI就露了原形。比如一道古代语言题,要翻译一段没公开过的巴尔米拉铭文,AI既没见过这段文本,也没有足够的专业知识推理,只能瞎蒙。
更关键的是,HLE的成绩打破了一个幻觉:AI不是“全知全能”的,它的能力边界比我们想象的要窄得多。80%的美国民众支持AI安全监管,本质上是在担心一个“不知道自己不知道”的AI,会在医疗、法律这些关键领域给出致命的错误答案。
HLE刚发布时,有人质疑它“脱离实际”——毕竟现实中很少有人需要AI去解博士生的数学题。但很快,这份考卷的价值就显现出来:它成了AI安全研究的标尺。比如CAIS的研究人员发现,在HLE上得分越高的AI,在处理复杂伦理问题时的失误率越低;而得分低的AI,更容易产生“幻觉”和偏见。
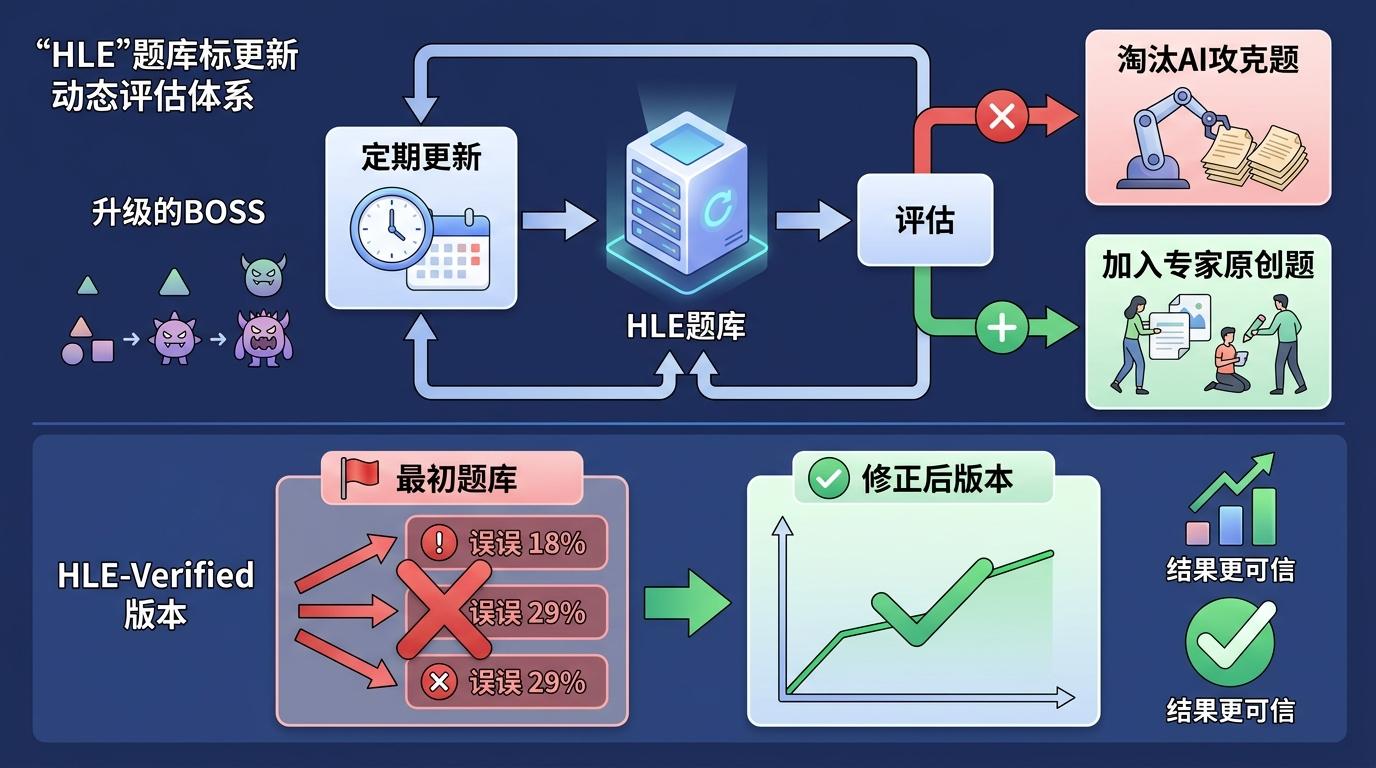
现在,HLE已经不是一份静态的考卷,而是一个动态的评估体系。团队会定期更新题目,淘汰那些被AI攻克的难题,加入新的专家原创题——就像游戏里不断升级的BOSS。同时,他们还推出了“HLE-Verified”版本,修正了最初题库里18%-29%的错误,让测试结果更可信。
有意思的是,HLE的存在也倒逼AI开发者改变思路:不再盯着传统测试刷分,而是开始训练AI的“深度理解能力”。比如OpenAI的o1模型,专门针对复杂推理任务训练,在HLE上的得分从最初的8%提升到了15%——这不是靠刷分,而是靠真正的能力提升。
当我们用“终极考卷”去考AI时,其实也是在重新定义“智能”的标准。过去我们以为,能记住知识、答对题目就是智能;但HLE告诉我们,真正的智能是能理解知识、解决未知问题的能力。
考分不是智能,理解才是。
未来的AI评估,不会再是简单的“刷分游戏”,而是一场关于“理解能力”的持久战。HLE不是AI的“终极考试”,而是人类和AI一起探索智能边界的起点——毕竟,我们真正想知道的,从来不是AI能考多少分,而是它到底能帮我们解决什么问题。
点击充电,成为大圆镜下一个视频选题!