对抗知识焦虑,从看懂这条开始
App 下载
50米洗车题难倒AI,暴露推理底层缺陷
AI常识缺陷|启发式主导比|推理机制|卡内基梅隆大学|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI常识缺陷|启发式主导比|推理机制|卡内基梅隆大学|大语言模型|人工智能
当你问AI“家离洗车店50米,走路还是开车去”,80%的主流模型会一本正经建议你步行——理由从环保健康列到时间成本,甚至贴心提醒“开去再开回,车又脏了”。直到你补一句“车还在家呢”,它们才会秒懂自己犯了低级错误:要洗的是车,不是人。这道看似无聊的生活题,像一把精准的手术刀,划开了大语言模型“智能”的表皮,露出了其推理机制里藏了很久的bug。
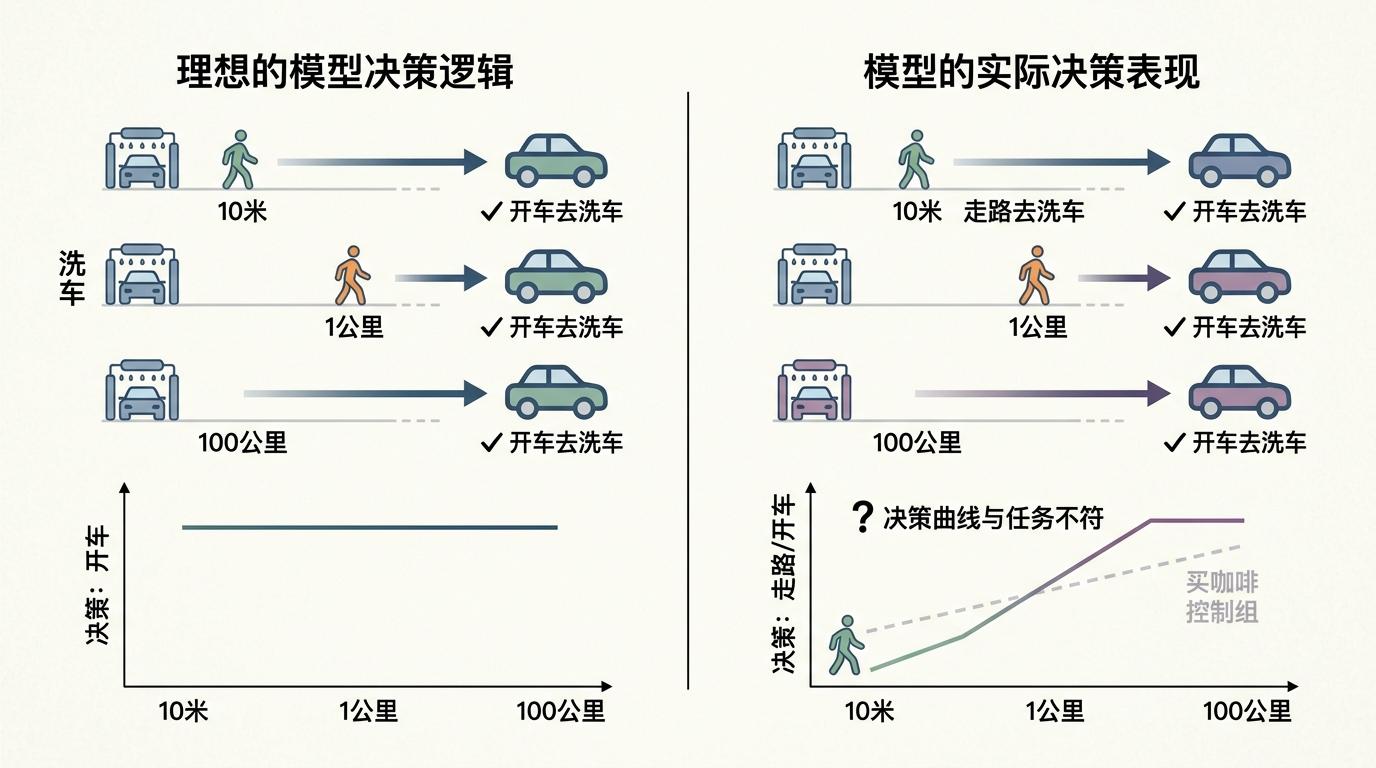
卡内基梅隆大学的研究者把这道题变成了严肃的科学实验。他们测试了53个主流模型,只有11个答对,翻车率超过80%;同一个问题问10遍,能稳定答对的只剩5个。更关键的是,他们算出了一个核心数据:启发式主导比——距离线索对模型决策的影响力,是“洗车”这个目标线索的8.7到38倍。
这个指标像个精准的诊断报告:模型的底层决策完全被“短距离该走路”的强关联模式绑架了。它把问题简化成“去50米外的地方选什么交通方式”,却自动过滤了“车是服务对象”这个隐含前提。就像人类被卡尼曼说的“快思考”支配时,会跳过复杂判断直接用直觉下结论——但人类能靠“慢思考”纠错,模型却困在了永恒的快思考里。
研究者做了个更狠的测试:把距离从10米调到100公里。如果模型真的理解洗车的逻辑,不管多远都该选开车,但所有模型画出的决策曲线都和“去买咖啡”的对照组几乎平行——近了走路,远了开车,完全无视任务目标的约束。
这道题戳中的其实是人工智能的经典死穴——框架问题。1969年麦卡锡和海耶斯就提出过:当智能体行动时,怎么判断哪些事实相关,哪些可以忽略?
人类靠的是嵌在身体经验里的直觉:洗车要车在场,就像喝水要拿杯子,不需要刻意思考。但大语言模型没有身体,没摸过车,没洗过车,它从海量文本里学到的只是“洗车”“距离”“走路”这些词的统计关联,学不到“车必须被送到目的地”这个物理世界的硬约束。
研究者试过给模型“搭梯子”:在题目里加粗“我的车”,准确率平均提升15个百分点;让模型先列“洗车的必要前提”,弱模型的正确率能涨9%。这说明模型不是不知道这个常识,而是不会自动激活它——就像你考试时明明背过公式,却忘了要用到这道题上。
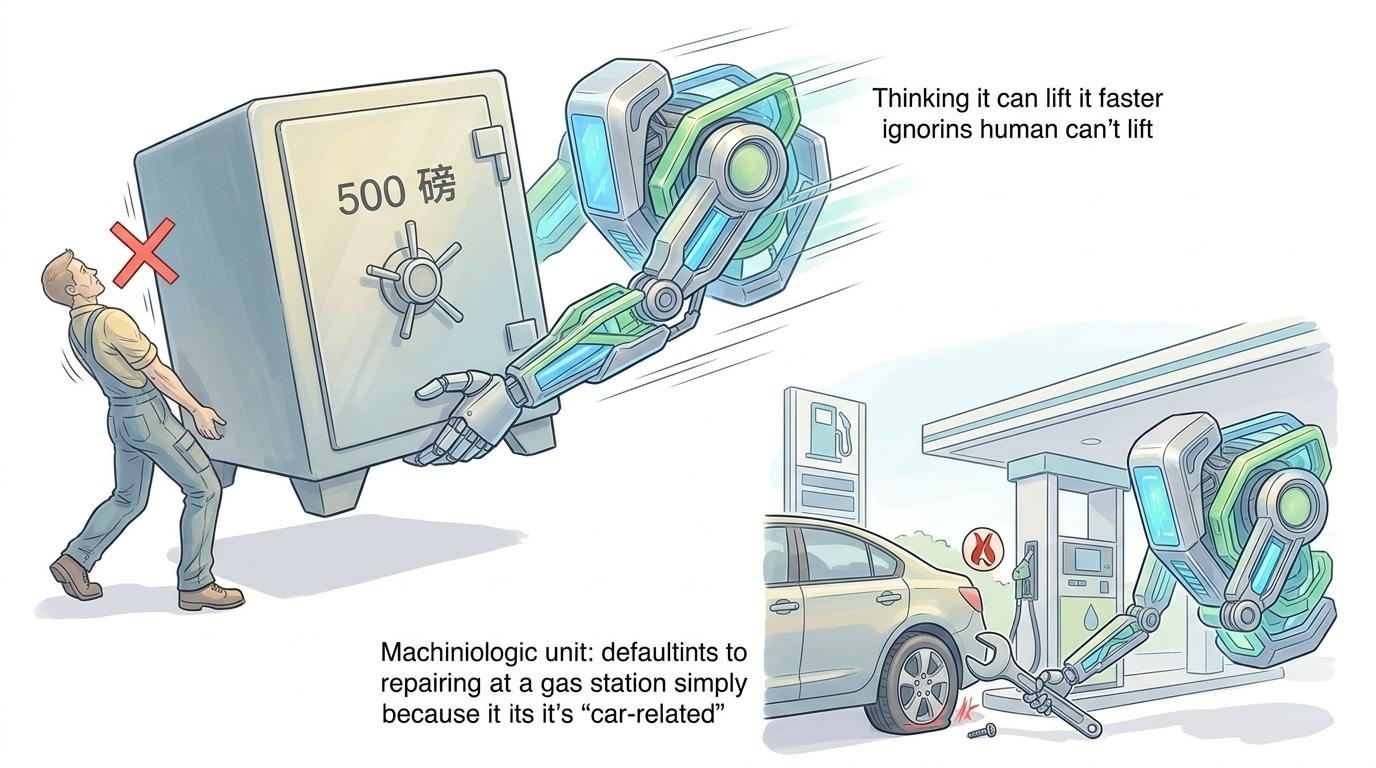
这种缺陷不止出现在洗车题里。在搬500磅保险箱的测试中,模型会坚持“自己搬更快”,完全无视人类搬不动的物理限制;在加油站修轮胎的问题里,它会因为“加油站和汽车相关”,默认对方提供维修服务。
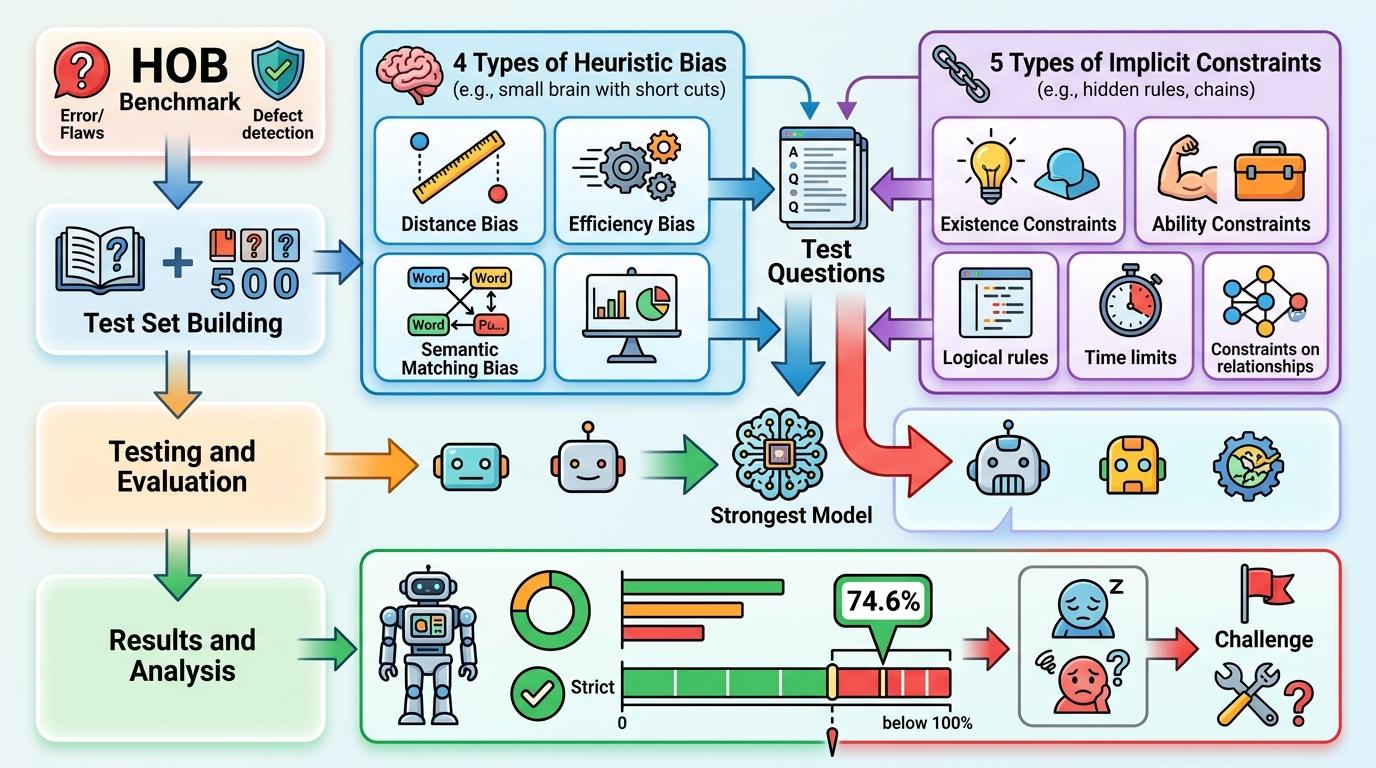
为了系统检测这种缺陷,研究者搭建了包含500道题的HOB基准测试,覆盖距离、效率、语义匹配等4类启发式偏见,以及存在性、能力等5类隐含约束。测试结果显示,哪怕是最强的模型,严格标准下的正确率也只有74.6%。
有意思的是,当研究者把题目里的隐含约束去掉——比如把“洗车”改成“去洗车店买礼品卡”——14个模型里有12个成绩反而下降了。这说明很多看似正确的回答,其实是模型选了“更稳妥”的选项,不是真的推理出来的。
目前最有效的改进不是扩大模型规模,而是用提示“叫醒”模型的常识。比如“目标分解提示”,让模型先把“洗车”拆解成“把车开到店→接受服务→开回家”,再做决策。这种方法对弱模型效果显著,但对已经能自主激活常识的强模型没用——这也暗示,未来的AI改进,可能不是堆参数,而是给模型装上“自动找前提”的开关。
我们总喜欢用“答对多少难题”来衡量AI的智能,却忘了真正的智能,是能瞬间抓住那些不需要说出来的前提。就像这道洗车题,一个五岁小孩能秒懂的逻辑,却难住了80%的大模型。
这不是AI不够聪明,而是它的“聪明”和人类的“智能”根本不是一回事。人类的智能长在身体里,嵌在和世界的交互里;而AI的智能,还停留在对文字符号的统计关联上。
能力不等于理解,就像会背公式不等于会解题。这道50米的洗车题,测出的不是AI的智商,而是我们离真正通用人工智能的距离——那距离,比50米远多了。