对抗知识焦虑,从看懂这条开始
App 下载
AI能认出摔倒,但不知道人为什么摔倒
AI识别能力|老年人摔倒|CUHK-X数据集|动作理解|香港中文大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI识别能力|老年人摔倒|CUHK-X数据集|动作理解|香港中文大学|多模态视觉|人工智能
当一个老人在客厅摔倒,现在的AI能立刻喊出“这是摔倒”——但它不知道老人是被地毯绊了脚,还是起身时头晕失衡;更不会预判老人接下来可能无法起身,需要紧急呼叫护理员。香港中文大学的团队最近用一个全新的多模态数据集测试了主流大模型,得到了一个扎心的结果:即便最顶尖的AI,在理解人类真实动作这件事上,平均正确率只有四成。这背后藏着一个被忽略的真相:我们训练AI认出动作,却没教它读懂动作里的逻辑。
你可以把AI的动作理解能力比作学做菜:传统数据集只教它认“这是炒青菜”,而CUHK-X数据集要教它懂“为什么用大火、青菜为什么要先焯水、下一步该放什么调料”。这个数据集的诞生,源于团队做边缘AI时的挫败——他们发现现有数据都停留在“识别”层面,根本满足不了真实场景的需求:养老院需要知道老人摔倒的原因,康复系统要判断动作是否标准,服务机器人得读懂用户抬手是要喝水还是要关灯。
为了打造这套数据,团队走了一条反常规的路:先用大模型把40种高频日常动作串成有逻辑的剧情,比如“起床-摸水杯-走向厨房-接水”,再让志愿者照着演。数据收集前,动作的因果逻辑、前后关联就已经被精准定义,彻底解决了传统“先拍视频再打标签”的混乱和低效。
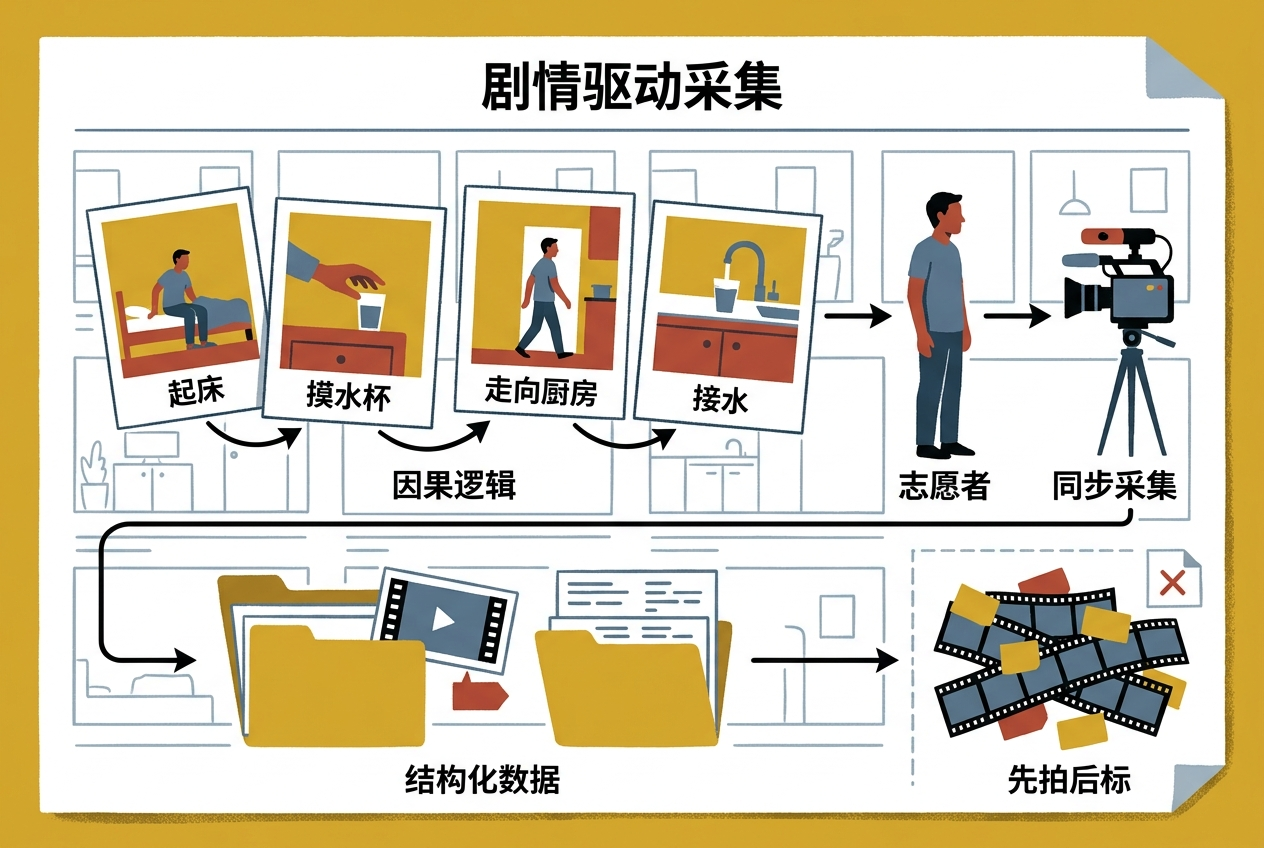
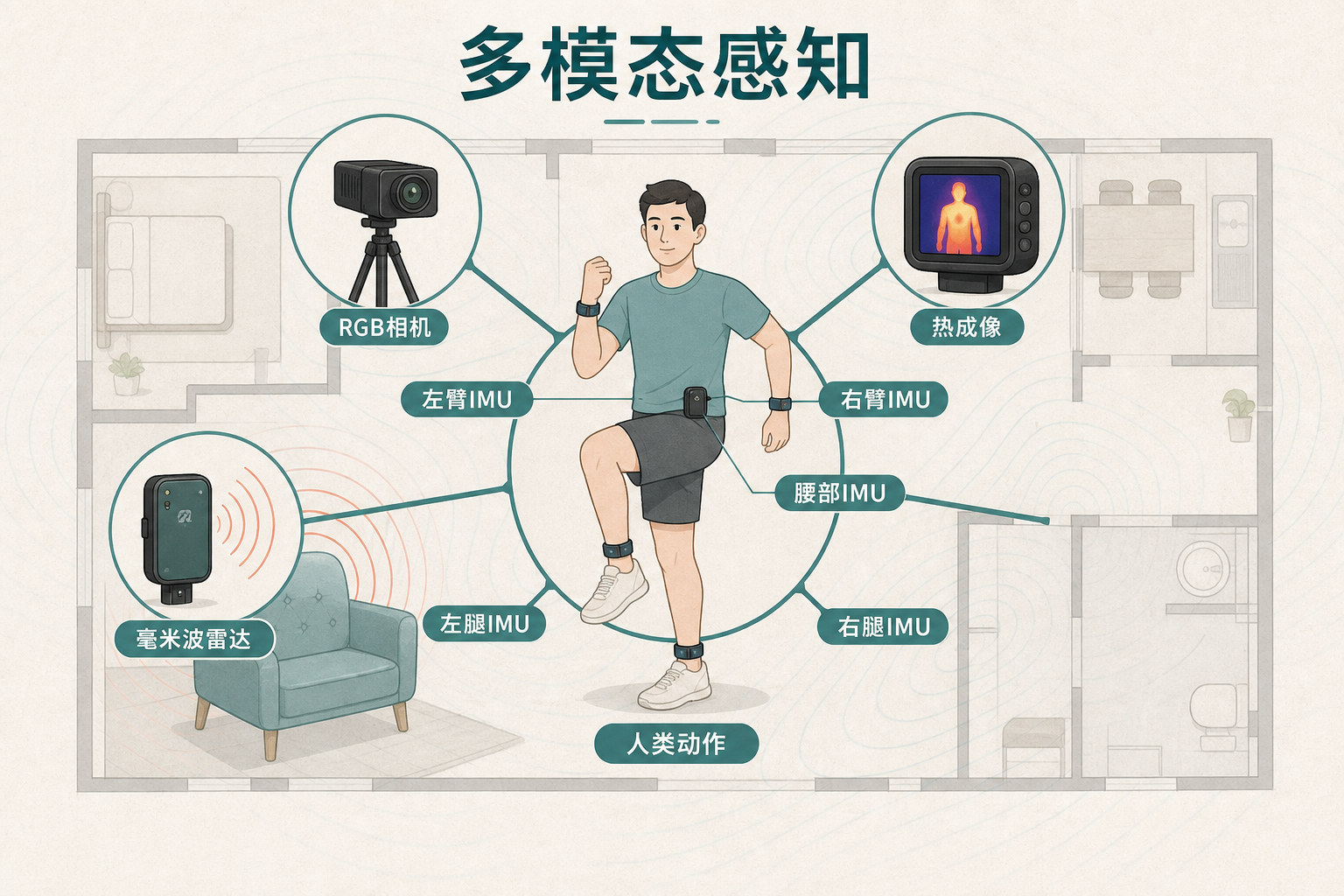
他们用7种传感器同步记录数据:彩色摄像头抓动作细节,热成像测体温变化,毫米波雷达穿透遮挡,还有绑在四肢和腰部的惯性传感器捕捉肌肉发力——就像给AI同时装上眼睛、皮肤和触觉神经,让它能从多个维度“感知”人类动作。
用CUHK-X测试主流大模型的结果,像一盆冷水浇在了AI“无所不能”的神话上:
问题出在两个地方:一是现有大模型大多针对彩色照片优化,面对深度图、毫米波雷达这些“非主流”传感器数据,就像色盲看彩虹;二是AI习惯了“模式匹配”,却没学会“逻辑推理”——它能记住“摔倒”的画面,却不知道摔倒的前提是“脚绊到了椅子”,后果是“可能骨折需要扶”。
有意思的是,少数具备推理能力的模型表现出了潜力:它会观察环境里的细节——桌子上的药瓶、老人扶着额头的动作,推断出“老人可能头晕,接下来有摔倒风险”,还能说出推理过程。这才是AI走进家庭、养老院需要的能力:不是做一个只会喊“摔倒了”的报警器,而是做一个能预判风险、理解需求的助手。
这套数据集的搭建,远不止“拍视频打标签”那么简单。团队最刻骨铭心的教训,来自毫米波雷达:在实验室里调试完美的设备,搬到居家场景后信号全乱了——墙壁的反射、家具的遮挡,让雷达数据完全失效,十几个小时的采集成果全部作废,二十多个志愿者得重新回来补拍。
这个教训让他们明白:AI要适应真实世界,数据集就得先走进真实世界。现在的CUHK-X只覆盖了30个参与者,团队计划把人数扩展到100人,还要加入WiFi信号、音频等新模态,甚至去真实的养老机构采集数据。毕竟,实验室里的“完美摔倒”和养老院里老人因为头晕的“真实摔倒”,对AI来说是完全不同的问题。
更值得关注的是,团队在数据里埋下了“隐私保护”的伏笔:毫米波雷达、热成像这些传感器不需要拍摄人脸,就能捕捉动作,这让AI在居家场景的应用有了隐私安全的可能——毕竟没人愿意家里的AI时刻盯着自己的脸。
我们总说AI要“像人一样思考”,但人类的思考从来不是“认出事物”,而是“理解事物的逻辑”。CUHK-X数据集的意义,不是造出了一个更精准的动作识别模型,而是推开了一扇门——让AI从“看动作”走向“读动作”,从“识别世界”走向“理解世界”。
动作里藏着人类的需求、状态和意图:老人缓慢起身的动作里藏着乏力,病人弯曲手臂的角度里藏着康复进度,孩子抬手的动作里藏着对拥抱的渴望。AI要读懂这些,需要的不更多的算力,而是更懂真实世界的数据集,和更贴近人类认知的训练逻辑。
看见动作,只是理解人类的开始。