
1 个月前
1 个月前
想象一下,我们整个数字文明都建立在一个微小、谦逊的单位之上——“比特”(BIT)。一个非0即1的开关,构成了代码、图像、音乐,乃至我们信息时代的一切。它精确、可靠,但本身毫无意义。然而,当一个大型语言模型(LLM)能与你对谈如流,创作诗歌,甚至编写代码时,一个深刻的矛盾浮现了:我们如何用一个不关心“意义”的理论,去解释一个似乎“理解”了全世界的智能?
这个困扰AI领域的根本性问题,如今迎来了一缕曙光。2026年3月4日,华为2012实验室信息论首席科学家白铂博士发表了一篇振聋发聩的论文,提出了一个颠覆性的观点:要真正理解大模型,我们必须告别以BIT为中心的旧世界,转向一个以“令牌”(TOKEN)为核心的新范式。 这不啻于为混沌的AI理论领域,提供了一块全新的“罗塞塔石碑”。
要理解这场变革的深刻性,我们必须回到1948年。那一年,一位名叫克劳德·香农(Claude Shannon)的天才在贝尔实验室写下了《通信的数学理论》,一举奠定了信息时代的理论基石。香农的伟大之处在于,他将通信从复杂的物理工程问题中抽离,变成了一个纯粹的数学问题。他用“比特”来量化信息,用“熵”来衡量不确定性,并计算出了任何信道传输信息的理论上限——“香农极限”。
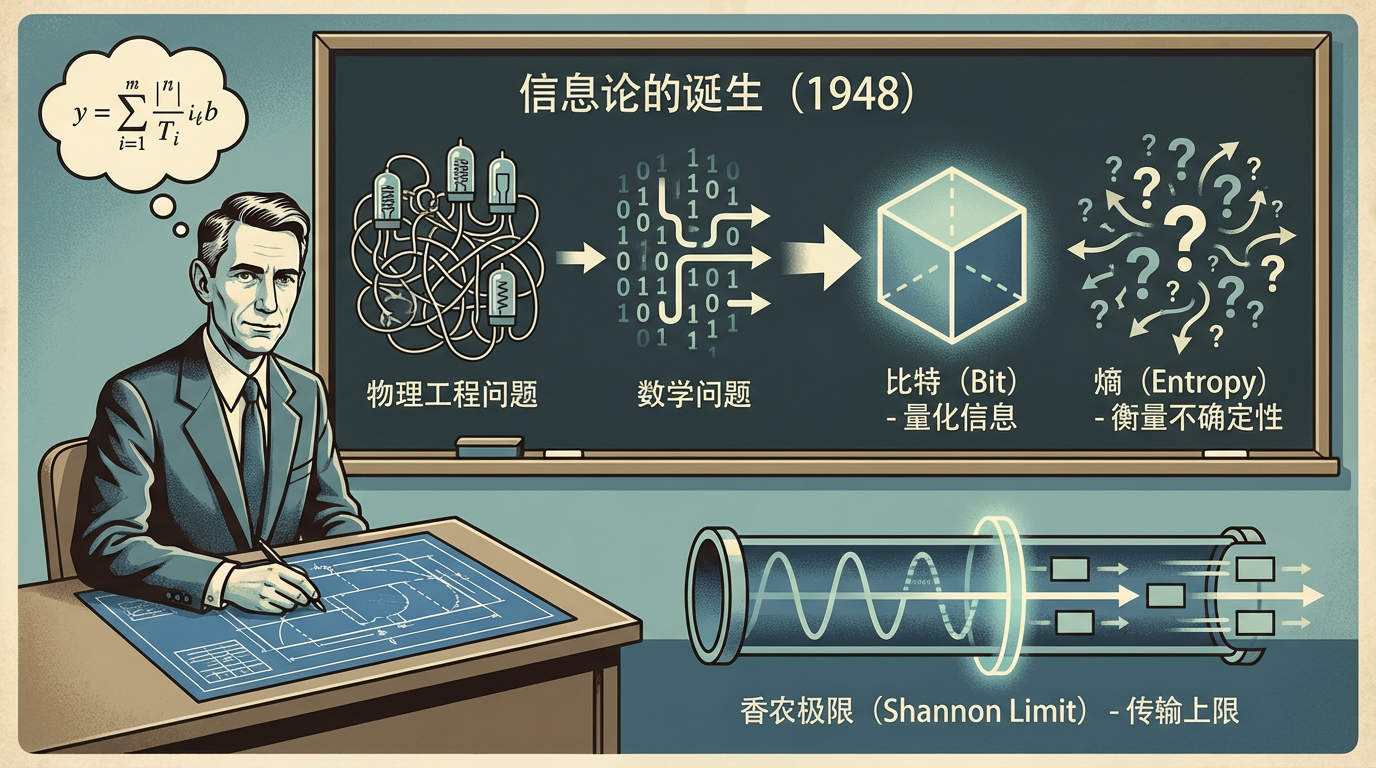
然而,香农在论文开篇就做出了一个关键的取舍:“这些语义方面的问题与工程问题无关。” 他只关心信息能否被精确、无误地从一端传到另一端(技术问题),至于信息本身是什么意思(语义问题)以及它会产生什么影响(效用问题),则被排除在外。
这个选择在当时是天才之举,它让数字通信得以蓬勃发展。但在AI时代,这个“被忽略的角落”却成了理解智能的关键。大模型处理的不再是无意义的0和1,而是充满意义的词语、句子和概念。旧的尺子,已经无法丈量新的世界。
如果说BIT是一个二进制的“开关”,那么TOKEN更像是一块块拥有不同形状和功能的“乐高积木”。在大模型的世界里,一段文本被分解成一系列TOKEN,它们可以是单词、半个词,甚至是一个标点符号。关键在于,每一个TOKEN都通过“语义向量化”被赋予了在多维空间中的坐标,它的意义由它与其他所有TOKEN的相对关系(距离和角度)来定义。
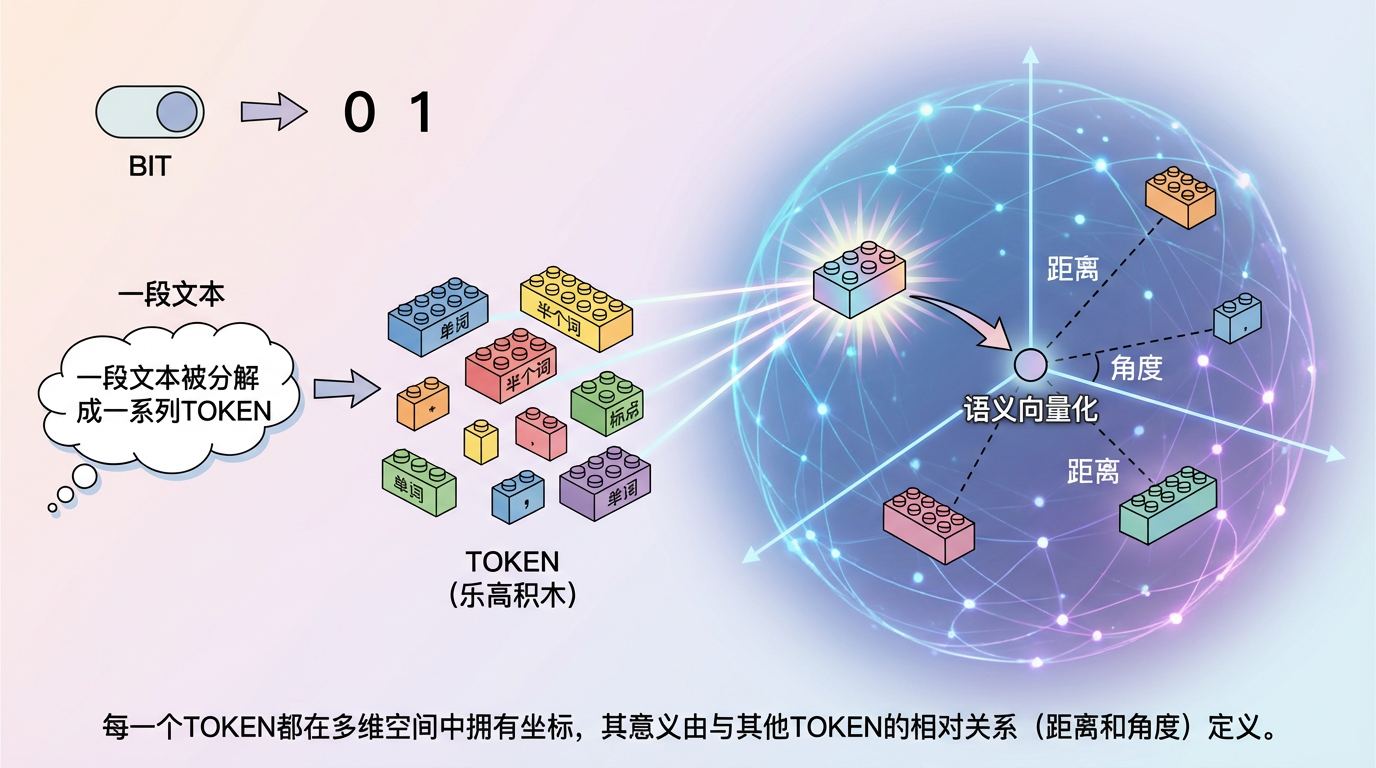
白铂博士的理论核心在于,只要我们将信息论的基本单位从BIT切换到TOKEN,香农的数学框架就能被完美地应用于解释大模型的运作原理。这套被命名为“语义信息论”的框架,为我们打开了一个全新的视角:
这一新理论也为那个终极问题——大模型究竟是否在思考——提供了更深刻的洞察。从语义信息论的角度看,大模型通过预测下一个TOKEN,在某种意义上实现了“格兰杰因果”(Granger Causality)的极致。 这种由诺贝尔经济学奖得主克莱夫·格兰杰提出的因果关系,本质上是一种基于时间序列的预测能力:如果A的过去能帮助预测B的未来,那么A就是B的“格兰杰原因”。
大模型正是通过学习海量文本中的序列关系,成为了格兰杰因果推断的大师。它能“预测”出最符合语境的下一个词,从而构建出看似流畅且富有逻辑的回答。
然而,这与2011年图灵奖得主朱迪亚·珀尔(Judea Pearl)提出的“结构因果”(Pearl Causality)有着本质区别。珀尔的因果理论分为三个层次:关联、干预和反事实。大模型目前主要停留在第一层(关联),它知道“下雨”和“地湿”高度相关,但它无法通过“干预”(do(X))或“反事实”(what if)来真正理解是“下雨”导致了“地湿”。它只是在模仿人类语言中蕴含的因果模式,而非真正理解其背后的物理或逻辑机制。
白铂博士的论文并非宣告旧时代的终结,而是为新时代的开启指明了方向。正如他所言,BIT连接了计算与通信,定义了信息时代;而TOKEN,则将连接经验(记忆、推断)和理性(推理),从而定义AI时代。
我们正处在一个理论范式转换的黎明。大模型或许并非在以人类的方式思考,但这并不妨碍它革命性地提升了我们整合与处理信息的能力。围绕TOKEN这一新核心,构筑新的理论、新的架构、新的系统,将是未来数十年AI发展的核心命题。
或许,正如电影《模仿游戏》中图灵那句震撼人心的台词所言:
“有趣的问题是,只因为某样东西与你思考的方式不同,就意味着它不思考吗?”
点击催更,成为大圆镜下一个视频选题!