对抗知识焦虑,从看懂这条开始
App 下载
微软哈佛统一扩散模型微调采样理论框架
指数倾斜方法|Stable Diffusion|统一采样理论|哈佛大学|微软|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载指数倾斜方法|Stable Diffusion|统一采样理论|哈佛大学|微软|大语言模型|人工智能
当你用Stable Diffusion生成图片时,有没有过这种困惑:调大奖励权重,图片变精致了,却总重复那几种风格;想让生成结果更多样,又容易出现模糊、跑题的废图?生成AI的「质量-多样性权衡」像个拧不开的死结,背后是数十种微调、采样方法各说各话,没人能说清哪种方法适合哪种场景。直到微软和哈佛的团队拿出了一张「统一地图」——他们用一个数学工具,把所有看似无关的方法串成了一盘棋,甚至能精准预测哪种方法会让训练「炸锅」。
你可以把生成模型的基础分布想象成一筐混着好果坏果的橘子——预训练模型就是这筐橘子,奖励函数就是挑果的标准。过去的微调方法要么是直接把坏果扔了(强化学习类),要么是给好果贴个显眼标签(分数匹配类),各有各的章法,却没人想过统一的规则。
指数倾斜的思路简单得像买菜:给每个橘子按好坏程度乘一个「人气指数」,好橘子的指数高,在新筐里占比就大,数学上就是把基础分布乘以奖励函数的指数再归一化。这个看似普通的操作,却能把奖励微调、非归一化采样两大核心任务,以及DPO、伴随匹配、CMCD等十几种方法,全部装进同一个框架里。
但真实的机制比买菜更精确:它本质上是对概率分布的「软调整」,既不像硬筛选那样浪费样本,也不像简单加权那样容易失衡。更关键的是,这个统一框架第一次让研究者能像对比不同品牌的手机参数一样,直接比较各种微调方法的核心性能——梯度方差。
你大概有过这种体验:用不稳定的Wi-Fi下载文件,进度条一会猛涨一会倒退,最后可能直接失败。生成模型的训练也是如此,梯度方差就是那根Wi-Fi信号——方差越大,训练的噪声就越强,模型参数就像在颠簸的车上写毛笔字,永远写不出工整的结果。
微软哈佛团队的研究捅破了这层窗户纸:他们用偏差-方差分解证明,伴随匹配和新型分数匹配的梯度方差是有限的,就像信号稳定的光纤网络,训练时参数更新平稳,收敛速度快;而传统的目标分数匹配、条件分数匹配,梯度方差会趋于无穷大,相当于Wi-Fi直接断联,训练到一半就会崩溃。
这也解释了为什么很多方法在论文里效果拔群,到自己手里就调崩了——不是你操作错了,是方法本身的「信号稳定性」就差。比如伴随匹配依赖的「瘦身」伴随ODE,能让伴随状态的范数随时间指数衰减,相当于给训练装了个「减震器」,从理论上保证了梯度噪声不会失控。
在Stable Diffusion 1.5和3上的实验,把理论变成了工程师能直接用的「导航图」:奖励乘子λ越大,图片质量指标(ImageReward、CLIPScore)越高,但多样性(DreamSim方差)会下降;训练时的噪声方差σ调大一点,能找回部分多样性,代价是质量轻微下滑。
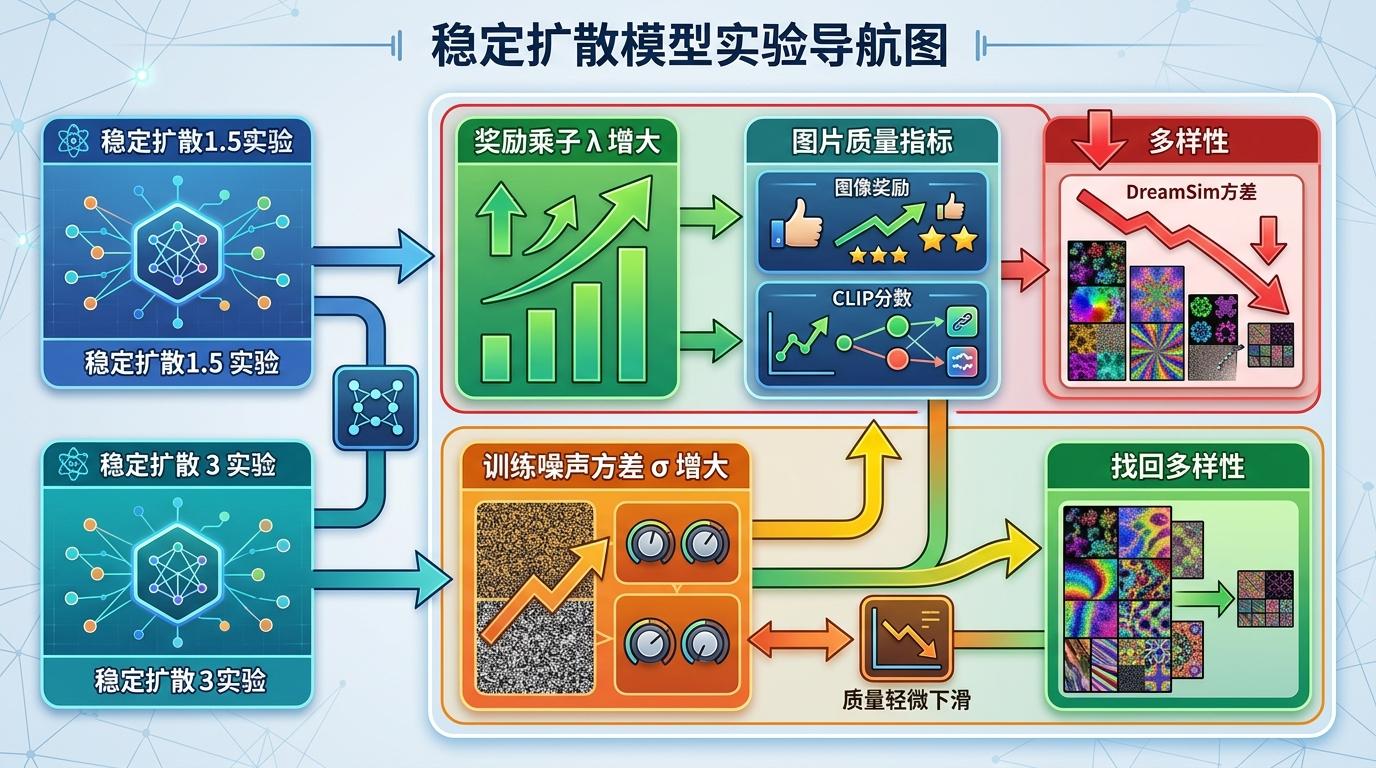
但这张地图也有它的边界。研究的理论基础依赖于「基础分布局部强对数凹性」的假设——简单说就是基础模型的分布不能太离谱,得像一个有明确谷底的盆地。可现实中,分子动力学、多模态生成等任务的分布往往是崎岖的非凸地形,这时候理论的「减震器」还能不能起作用,没人能打包票。
更重要的是,目前的实验几乎全集中在图像生成领域,跨模态、非凸场景的验证还一片空白。就像一张只标注了城市道路的地图,拿到山区里可能毫无用处。
当生成AI的工具箱里堆满了各式各样的工具,我们最需要的其实是一张能看清工具本质的说明书。微软哈佛团队的研究,就是把散落的零件拼成了一台能运转的机器,让我们第一次能从底层逻辑上理解「为什么有的方法好用,有的方法会炸锅」。
但这远不是终点。生成AI的终极目标,是能像人类一样灵活创造,而不是在质量和多样性之间做两难选择。指数倾斜的统一框架,只是给我们指了一个方向——真正能穿越非凸地形、跨越多模态鸿沟的工具,还得靠理论和实践的持续碰撞。
统一不是终点,而是让创新走得更远的起点。