对抗知识焦虑,从看懂这条开始
App 下载
AI照亮黑夜的秘密:从实验室到手机的技术突围
自动驾驶感知|低光图像还原|扩散模型|Retinex理论|NTIRE低光图像增强挑战赛|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动驾驶感知|低光图像还原|扩散模型|Retinex理论|NTIRE低光图像增强挑战赛|多模态视觉|人工智能
你有没有过这种经历?深夜用手机拍街景,屏幕上只剩一团模糊的黑影,连路灯的轮廓都像被揉碎的墨渍。这不是手机的错——低光环境下,传感器会被噪声淹没,细节和色彩会跟着光线一起消失。但在2026年的NTIRE低光图像增强挑战赛上,22支全球顶尖团队交出的答案,让黑夜第一次像白昼一样清晰:有的模型能把噪点密布的原始低光图,还原出堪比专业相机的色彩;有的只用短短几秒,就能让自动驾驶的“眼睛”在0.1勒克斯的黑暗里看清路牌。这背后,是一场持续了半个世纪的“照明革命”。
1963年,科学家埃德温·兰德提出了Retinex理论——这是低光增强领域的“牛顿力学”。简单说,人眼看到的图像,其实是“光照”和“物体本身的反射”共同作用的结果。就像你在暗室里看一件白衬衫,它的白色是自身的反射属性,而你能看到它,是因为有手电筒的光照。低光增强的本质,就是把这两部分拆开:把过暗的“光照”调亮,同时保留“反射”里的细节和色彩。
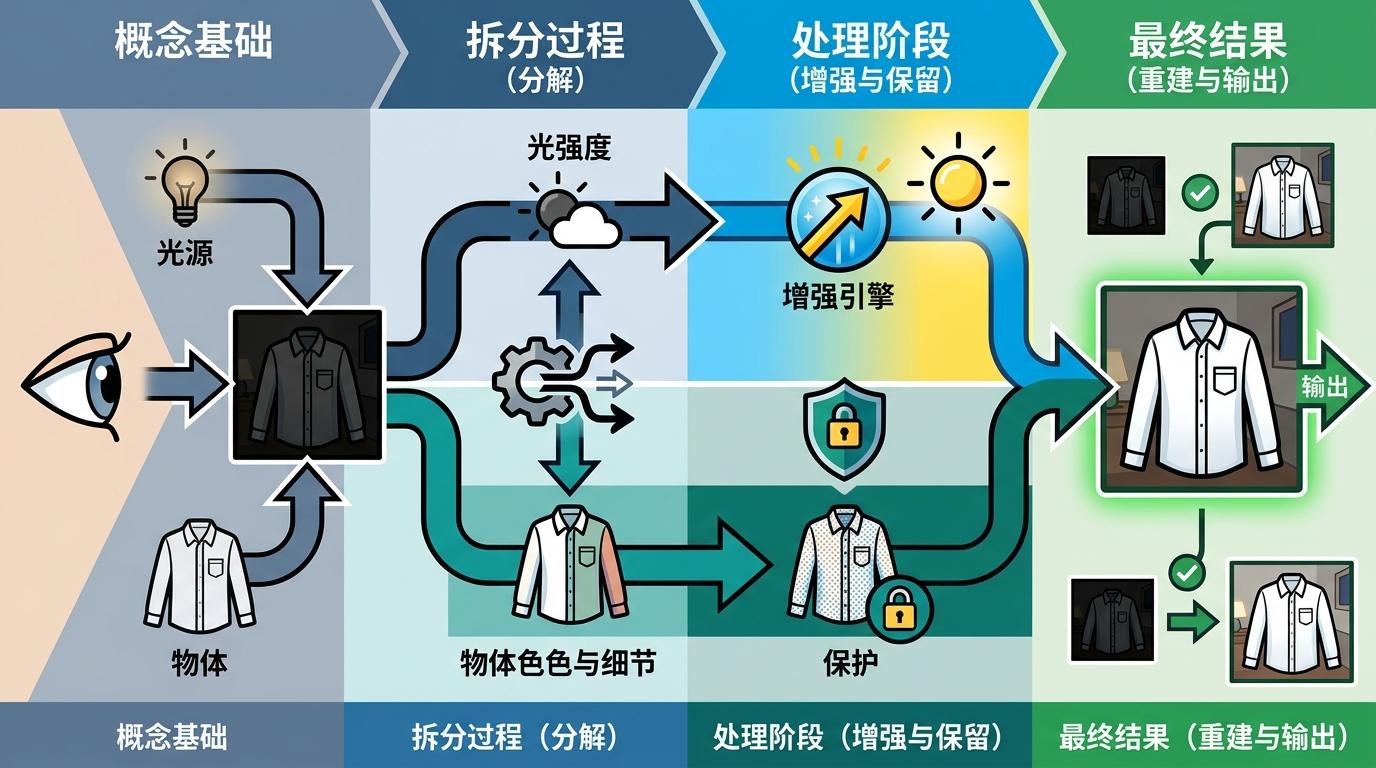
传统的Retinex算法靠手工拆解图像,就像用一把钝刀切开蛋糕,很容易切歪——要么把光照调得太亮导致过曝,要么把反射里的细节切掉留下噪点。直到深度学习出现,情况才变了:U-Net架构像一把精准的手术刀,能分层提取图像特征;Transformer则像一双能看穿全局的眼睛,能捕捉到暗部最细微的纹理。
但真正的突破来自生成式模型。比如AAIR-LAB团队的流匹配模型,它不再直接“修补”低光图,而是在一个叫“潜在空间”的地方,学习从黑暗到明亮的完整分布——就像观察一万次日出后,能精准画出从深夜到黎明的每一缕光线变化。这种方法生成的图像,连专业摄影师都挑不出破绽,在主观评分里拿到了全场最高的MOS分。
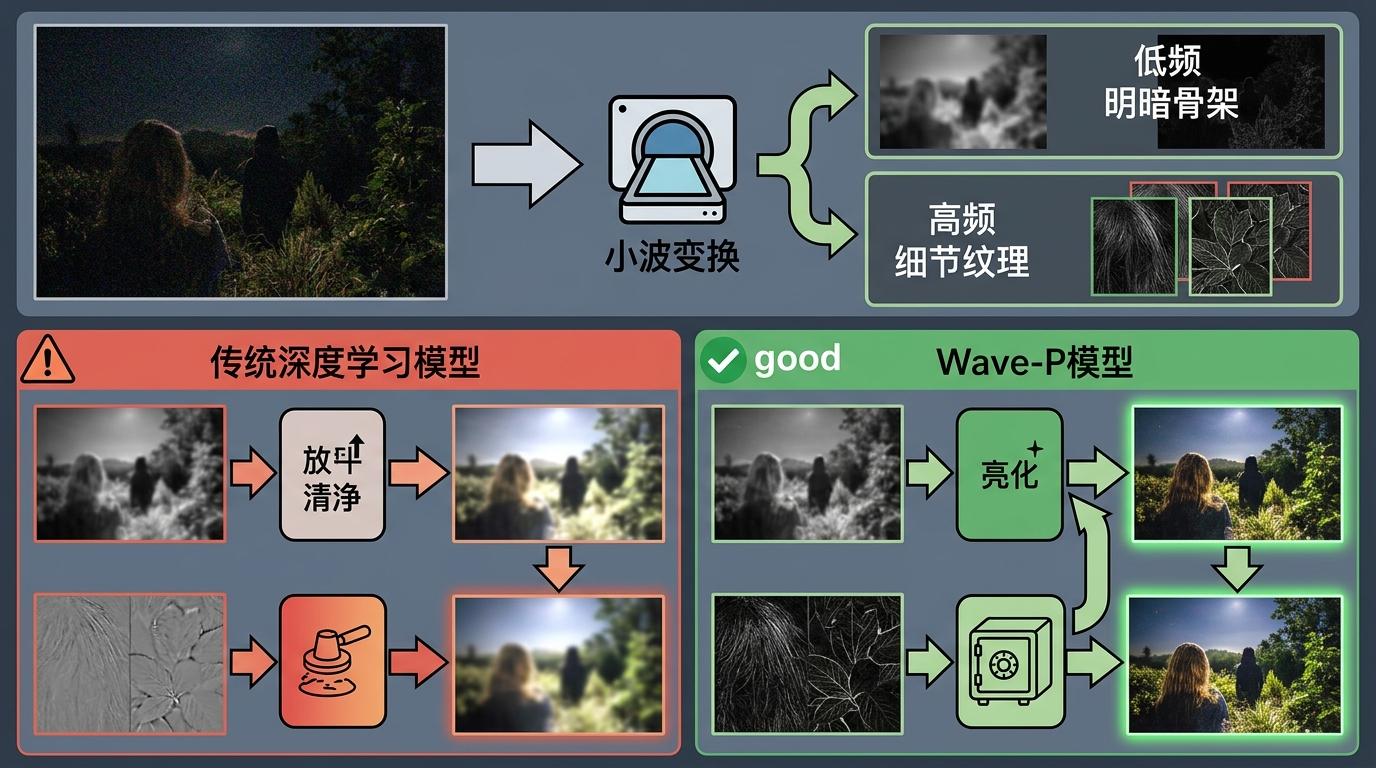
很多人以为,低光增强的冠军一定是最复杂的模型,但NTIRE 2026的结果恰恰相反。在最难的“联合去噪与增强”赛道,拿到参考指标近乎满分的是BAU-Vision团队的Wave-P模型——它的核心,是把半个世纪前的小波变换和深度学习结合起来。
小波变换就像给图像做“CT扫描”,能把图像分解成低频的明暗骨架和高频的细节纹理,然后分别处理。传统的深度学习模型在压缩图像时,会像用粗砂纸打磨一样,把高频细节一起磨掉;而Wave-P模型会把这些细节单独“装在盒子里”,等把明暗骨架调亮后,再原封不动地放回去。这让它在处理带噪点的原始低光图时,既能把噪点彻底清除,又能保留住发丝、树叶这些最细微的纹理。
更值得关注的是YuFans团队的“亮度感知渐进增强”策略。他们发现,比赛用的测试图比训练图平均暗2-3倍,直接用训练好的模型上去,效果还不如手动调伽马值。于是他们在训练时故意把图片调得更暗,让模型提前适应极端黑暗;还分阶段用越来越大的图像块训练,从局部细节到全局光照,逐步让模型“学会”看黑夜。这种看似简单的调整,让模型的泛化能力提升了一大截。
NTIRE 2026的结果里,有一个耐人寻味的细节:没有任何一支队伍能同时在“像素级保真”和“主观视觉质量”上拿到第一。有的模型能把低光图还原得和标准图一模一样,但看起来总觉得“假”;有的模型生成的图像自然得像白天拍的,但像素误差却比前者高。这背后,是低光增强至今没解决的核心矛盾:机器的“准确”和人的“好看”,往往不是一回事。
另一个更现实的问题是计算效率。像扩散模型这样的顶尖方案,生成一张4K图像需要几十秒,还得用高端GPU才能运行——这显然没法装在手机里。而能在手机上实时运行的轻量级模型,效果又远不如前者。硬件和算法的平衡,成了技术落地的最大瓶颈。
还有泛化能力的问题。这次比赛用的LSD数据集,已经是目前最接近真实场景的低光数据集,但它还是没法覆盖所有情况:不同手机的传感器噪声不一样,不同地域的黑夜亮度不一样,甚至同一个场景下,云层飘过的瞬间光照都会变化。现有的模型,一旦遇到训练数据里没有的情况,很容易就“失灵”。
当我们拿着手机在深夜拍出清晰的照片时,很少会想到,这背后是半个世纪的理论积累,是全球顶尖团队的算法竞赛,是硬件和软件的一次次磨合。NTIRE 2026的挑战赛,就像一面镜子,照出了低光增强技术的现在:它已经能在实验室里创造奇迹,但离真正走进每一部手机、每一辆自动驾驶汽车,还有一段路要走。
更重要的是,这场比赛让我们看到,技术的进步从来不是单一的突破,而是无数微小创新的叠加——可能是一个经典算法的重新组合,可能是一次训练策略的微小调整,也可能是一个硬件架构的巧妙优化。未来的“夜视眼”,不会是某一个超级模型,而是这些创新拧成的一股绳。
金句:照亮黑夜的,从来不是单一的光。