对抗知识焦虑,从看懂这条开始
App 下载
只追踪头和手,AI就能补出全身完整动作
人体姿态重建|虚拟现实动捕|上海科技大学|厦门大学|MotionMAR|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载人体姿态重建|虚拟现实动捕|上海科技大学|厦门大学|MotionMAR|多模态视觉|人工智能
当你戴着VR头显、攥着两个手柄在虚拟世界里挥手转身时,设备其实只盯着你3个点:头、左手、右手。你的腰怎么扭的,腿怎么迈的,脚跟什么时候落地——这些全靠后台模型“脑补”。从3个点还原22个关节的完整姿态,相当于给AI看三笔简笔画,要它还原一整幅人体动态速写。这曾是轻量级动捕的死局:传感器越少,用户门槛越低,但AI要填的窟窿就越大。直到厦门大学与上海科技大学的团队拿出了MotionMAR——它没想着硬补窟窿,而是换了个思路理解人体动作。
传统模型把人体动作当成一长串平铺的帧,逐帧预测缺失的关节——就像盯着简笔画的每一笔,硬猜后面的线条,结果要么顾不上整体姿态的合理性,要么丢了局部动作的细节。比如双手举着不动时,模型可能一会让你站着,一会让你蹲着,完全没考虑下半身的物理逻辑。
MotionMAR的核心突破,是把人体动作看成了有层次的时间信号:先有整体的大趋势,比如“向前走”“转身”,再添局部的小细节,比如“脚抬多高”“腰扭多少度”。你可以把它想象成画人物速写:先勾出全身的动态线条,再补上手的姿势、脚的落点,最后细化肌肉的起伏。
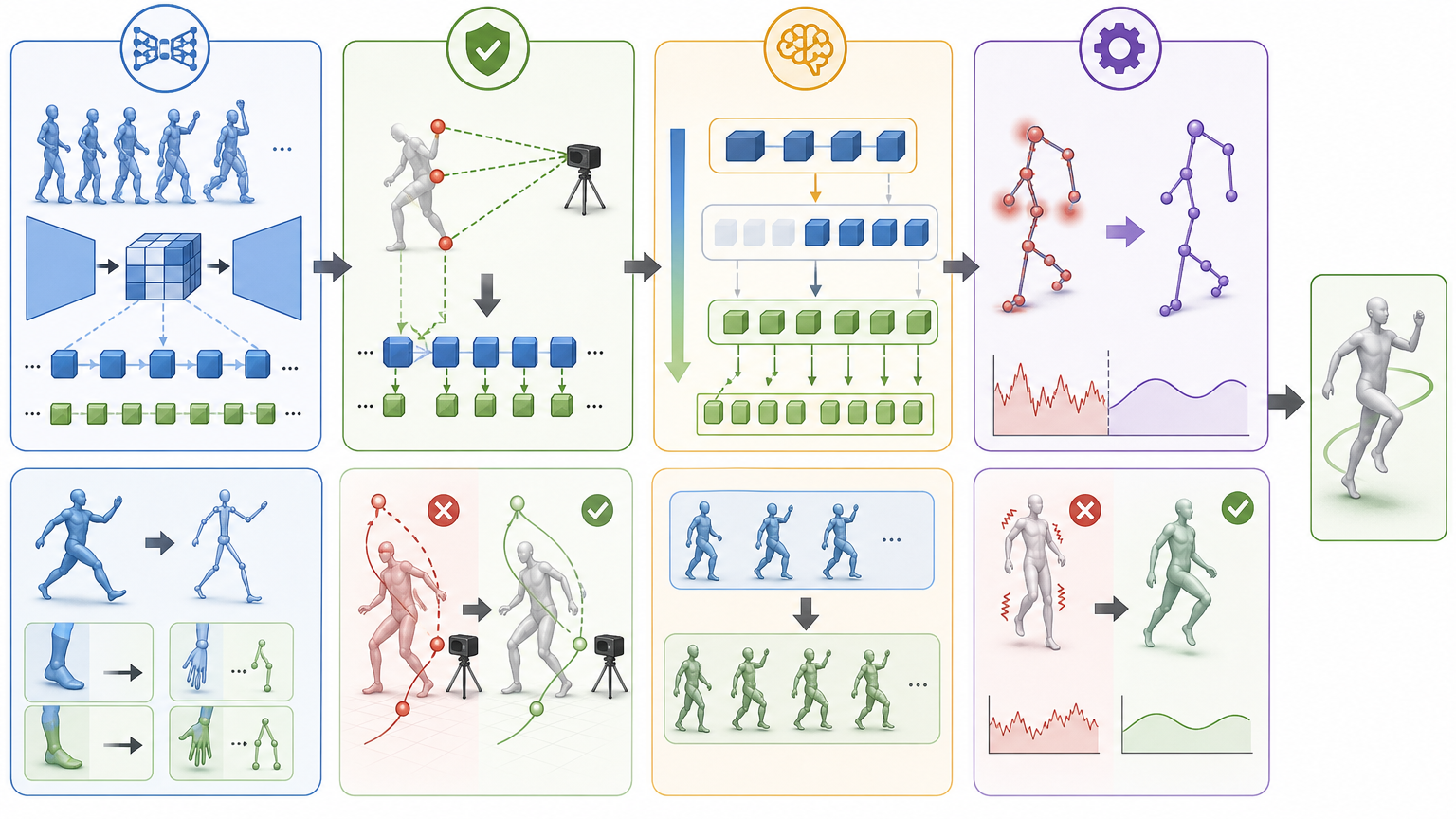
这套逻辑靠四个模块落地:TMT VQ-VAE负责把连续的动作序列拆成不同尺度的离散“动作词块”,相当于先把动作拆解成“走”“抬手”这些大模块和“踮脚”“转腕”这些小细节;SAC模块把仅有的3个追踪点数据,对应到不同尺度的动作词块上,确保AI“脑补”的动作不偏离真实追踪的轨迹;MAN网络负责从粗到细生成动作词块,先定整体趋势,再补局部细节;最后MRN网络把生成的动作打磨平滑,去掉AI容易犯的“关节抽搐”毛病。
在AMASS数据集的测试里,MotionMAR交出了扎实的成绩单:在仅用头和手三点追踪的标准VR场景下,它的关节重建误差、动作连贯性等核心指标,全面优于传统方法。就算把追踪点增加到四个,或者换成更复杂的动作数据集,它的表现依然稳定——这说明它不是靠“死记硬背”数据集,而是真的理解了人体运动的规律。
更关键的是速度。VR/AR应用要求至少30帧每秒的实时推理,MotionMAR的推理速度达到了61.76帧,完全满足甚至超过了实时需求。它的参数量只有42.36M,计算量1.47G,普通的消费级GPU就能轻松运行——这意味着它不用依赖昂贵的专业硬件,真的能落地到普通用户的VR设备里。
当然,它也不是完美的。在处理极端复杂的动作时,比如快速的街舞动作、剧烈的跑跳,下半身的还原精度还是会打折扣;而且它目前只依赖IMU追踪数据,如果能结合视觉信息,比如头显的摄像头画面,精度还能再上一个台阶。
过去几十年,动作捕捉技术的进化路径一直是“堆硬件”:光学动捕要在房间里装十几台摄像机,演员身上贴满反光点;惯性动捕要在全身上下戴十几个传感器。这些设备精度高,但成本动辄几十万,普通人根本碰不到。

MotionMAR代表的是另一条路径:用算法理解人体运动的规律,减少对硬件的依赖。就像人类看别人的动作,不用盯着每一个关节,只要看头和手的运动,就能猜出全身的姿态——因为我们懂人体的物理规律,知道手举起来时,肩膀会怎么动,腰会怎么配合。
这条路径已经有了不少同行者:比如用智能手机摄像头实现无标记动捕,用智能手表的IMU数据还原跑步姿态。MotionMAR的独特之处,是把分层多尺度的思路用到了极致,让AI真的像人一样“理解”动作,而不是靠数据堆砌去“拟合”动作。
当我们谈论动捕技术的未来时,其实是在谈论“让每个人都能拥有自己的数字分身”。你不用再去专业的动捕棚,不用穿满传感器,只要一个VR头显,甚至一部手机,就能让虚拟世界里的自己做出和你一模一样的动作。
MotionMAR的意义,不止是补全了几个关节的动作,更是证明了:比起堆硬件,让AI懂点人体运动的常识,才是降低动捕门槛的关键。懂规律,比堆数据更重要。未来的动捕技术,会越来越像一个会“观察”的伙伴,而不是一个需要你去适应的复杂机器。