对抗知识焦虑,从看懂这条开始
App 下载
大模型退居幕后,AI 协作成本暴跌85%
任务成本|AI公司|计算资源优化|模型分工|AI协作架构|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载任务成本|AI公司|计算资源优化|模型分工|AI协作架构|大语言模型|人工智能
当你用AI处理编程任务时,过去要么花大价钱用顶级模型保质量,要么选便宜模型赌它别“掉链子”——这道选择题曾让开发者头疼了整整三年。2026年4月的一个深夜,这个困局突然有了答案:一家AI公司把他们最聪明的大模型从台前拉到了幕后,只让它在关键时刻出手,结果不仅性能翻了倍,单次任务成本直接砍到了原来的15%。这不是小修小补的优化,而是把AI协作的逻辑彻底倒了过来。
过去的AI协作逻辑像个集权公司:最聪明的大模型当项目经理,把任务拆成小块分给小模型执行——但不管任务简单还是复杂,项目经理都得先过一遍手,每一步都要烧掉最贵的计算资源。就像让CEO去给员工订外卖,本事没用到点子上,钱却花得流水一样。

新的玩法完全反了过来:让最便宜最快的小模型当“执行者”,从头到尾负责跑通整个流程,只有当它遇到真的解决不了的难题,比如编程时卡壳、逻辑绕不明白,才会悄悄喊幕后的大模型“顾问”来支招。顾问只需要看一眼上下文,给出几行关键提示,剩下的苦活累活还是由执行者来干。
你可以把它想象成新手司机开长途:平时自己握方向盘,遇到复杂的高速匝道或者突发状况,才接通坐在副驾的老司机远程指导——既省了请老司机全程代驾的钱,又能在关键时刻不翻车。
实测数据把这种模式的优势拍得明明白白:在编程测试SWE-bench里,“小模型+大模型顾问”的组合,性能比单独用小模型提升了2.7个百分点,成本却降了11.9%;更夸张的是,用最便宜的小模型搭配大模型顾问,性能直接翻了一倍,成本却只有单独用中端模型的1/7。
秘密藏在Token的账单里:大模型顾问每次出手只需要输出400到700个Token的提示,而真正要生成的大段内容,全都是由小模型以1/20的成本完成。就像请大厨只需要出个菜谱,炒菜的活交给学徒——味道差不了多少,钱却省了一大半。
当然也有边界:如果任务全程都需要顶级推理能力,比如复杂的法律条文分析,这种模式的成本优势就不明显了。但对于80%的日常任务,比如批量处理数据、写基础代码、做内容审核,这种“执行者+顾问”的组合,刚好踩中了性能和成本的黄金平衡点。
这套“顾问策略”不是孤立的技巧,而是AI公司搭建完整协作平台的第一步。紧接着他们又推出了一个叫Monitor的工具,解决了AI另一个烧钱的痛点:过去AI要监控任务进度,比如等代码测试跑完,得每隔几分钟就问一次,每问一次就烧一轮Token。现在它可以自己写一段后台脚本,只有当任务出现结果时才会被唤醒——就像把闹钟从“每小时响一次”改成“到点再响”,空转的成本直接省了下来。
再加上之前推出的托管式智能体服务,这家公司已经从卖模型API,变成了卖一整套AI协作的基础设施:从任务调度、成本控制到后台运维,全都打包好给企业用。这意味着企业不用再自己搭架子,只需要说“我要做什么”,剩下的AI自己会组队完成。
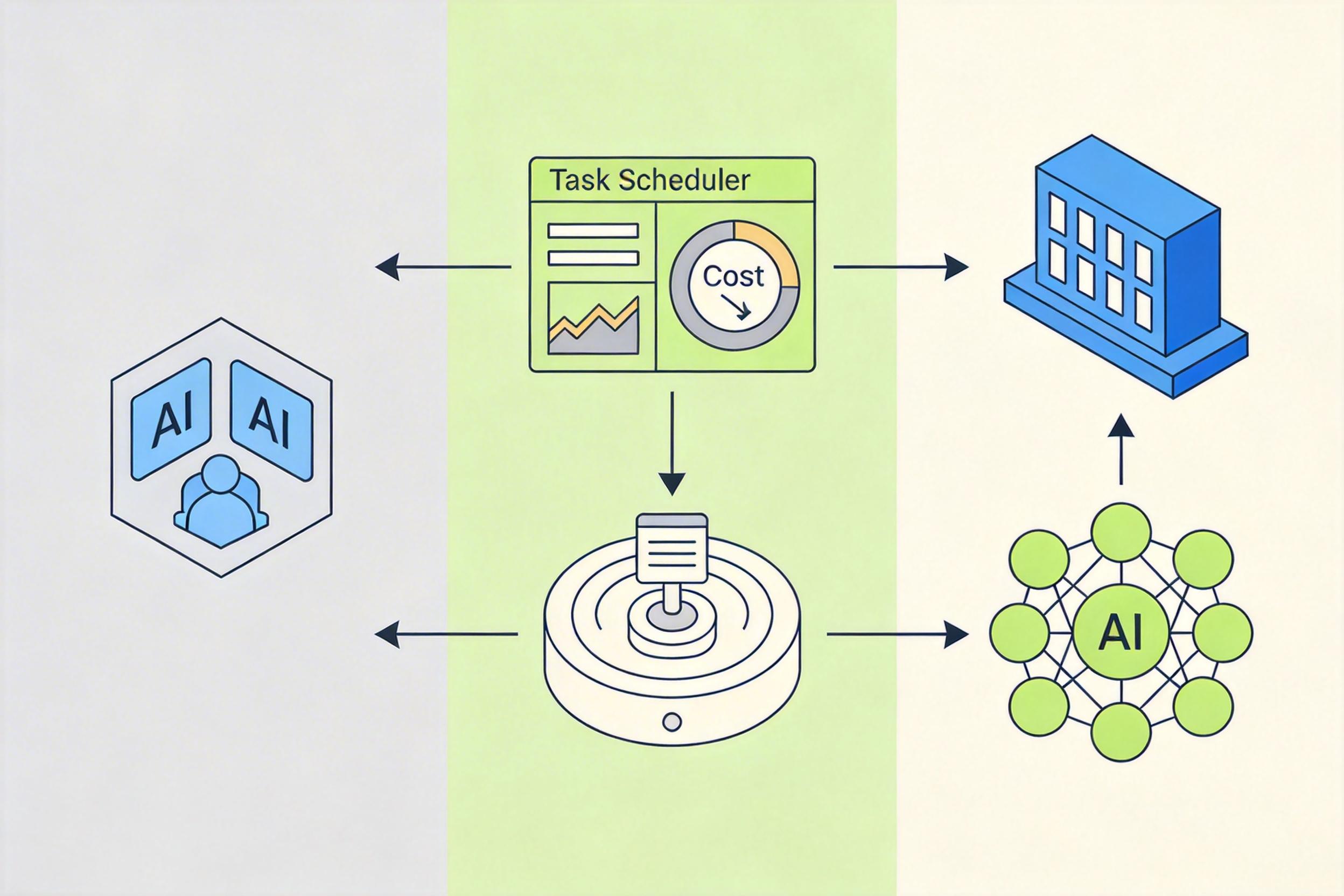
不过这种平台化也藏着隐忧:当越来越多的AI协作都跑在同一个平台上,数据的控制权、模型的依赖度,都会变成新的问题。就像所有公司都用同一家快递,一旦快递出问题,整个行业都会受影响。
AI的进化从来不是只看谁的模型更聪明,而是看谁能把聪明用在刀刃上。从让大模型包办一切,到让它只在关键时刻出手,这背后的逻辑变化,比模型性能的提升更有意义——它终于把AI从“昂贵的奢侈品”,变成了“能用得起的生产力工具”。
未来的AI协作,不会是一个超级模型统治一切,而是一群不同能力的AI各司其职,像一支配合默契的球队:前锋负责冲锋,中场负责调度,后卫负责防守,教练只在暂停时给出指导。聪明的AI,懂得该什么时候出手。