对抗知识焦虑,从看懂这条开始
App 下载
大模型不再只看下一步,推理能力跃升35组实验
实验结果|推理能力提升|Next-Token Prediction|复旦大学|华东师大|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载实验结果|推理能力提升|Next-Token Prediction|复旦大学|华东师大|大语言模型|人工智能
你有没有见过这样的AI:写代码时前几行流畅得像资深工程师,写到第十行突然冒出完全不通的逻辑;解数学题时第一步计算精准,第三步就开始答非所问。它每一步都显得无比自信,连起来却像一场逻辑灾难。这不是某个模型的bug,而是当前所有大模型的通病——被训练成了只看脚下的“短视者”。直到华东师大与复旦的团队,用一个看似微小的改动,让36组实验里的35组都拿到了最优结果。他们没有给模型加新的“脑子”,只是告诉它:下一步很重要,但你得留点余光看未来。
现在的大模型,几乎都靠「Next-Token Prediction(NTP,下一个词预测)」训练:给模型一段文字,让它只盯着“下一个该写什么词”,目标是每次都命中那个唯一“正确”的词。就像下棋时只看“这一步放哪最顺手”,完全不管对手的陷阱和三局后的输赢。

你可以把这种训练比作老师盯着学生写作业:每写一个字就纠正一次,学生只想着把当下的字写对,根本不会去想整段话的逻辑。时间久了,模型成了“局部最优大师”——单看每个词都挑不出错,但连起来的句子、推理的链条,却常常跑偏到离谱。
更关键的是,研究团队发现,模型其实根本不是不会“看远”。他们用一个叫「Future-tokens Hit Rate(FtHR,未来词命中率)」的指标测试:在模型当前预测的概率最高的几个词里,居然已经包含了未来几步会出现的真实词。而且一个未来词在当前排名越靠前,后面被正确生成的概率就越高。原来大模型的“前瞻基因”一直都在,只是被“必须只看当下”的训练目标给锁死了。
团队提出的Next-ToBE,核心改动只有一个:把“只盯着下一个词”的硬目标,改成了“兼顾未来几个词”的软目标。
具体来说,就是不再要求模型把100%的注意力都压在“下一个正确词”上,而是让它分出一部分精力,去关注未来k个词的概率分布。这些未来词的权重也不是随便给的——越靠近当前、和当前语义关联越强的词,权重越高;同时也保留模型原本对这些词的预测倾向,相当于让模型在“自己的判断”和“未来的关联”之间找平衡。
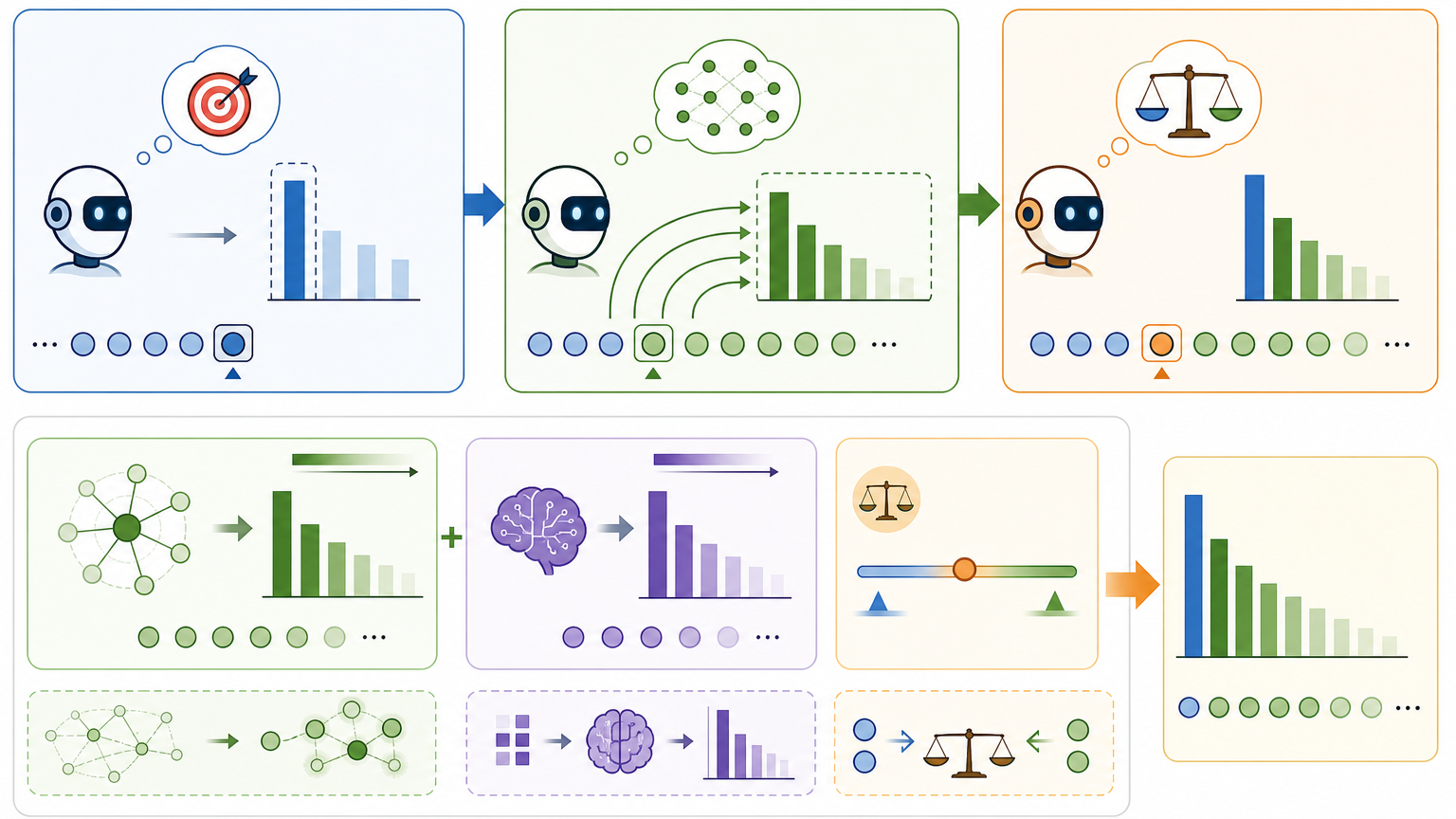
这和之前的多词预测方法完全不同:那些方法是给模型多加几个“预测头”,让它同时算好几个词,不仅复杂还费资源。Next-ToBE则完全不用改模型结构,只是调整了训练时的“评分标准”——就像老师不再只看单个字,而是会看学生写的内容有没有为后面的句子铺垫。
实验结果直接印证了这个思路的高效:在数学推理、代码生成、常识推理三类任务的36组对比中,Next-ToBE拿下了35组第一。而且它的训练开销比传统多词预测方法低得多,显存和时间都明显更少。
最有意思的是一个反直觉的发现:当Next-ToBE让模型不再执着于“当下100%正确”时,模型的推理能力反而达到了峰值。
随着模型分给未来词的注意力越多,它对“下一个词”的预测置信度会逐渐下降——从0.87降到0.81,不再那么“一锤定音”。但对应的推理准确率,却先上升后下降,形成一个完美的A形曲线:在“适度不确定”的状态下,模型的推理能力最强。
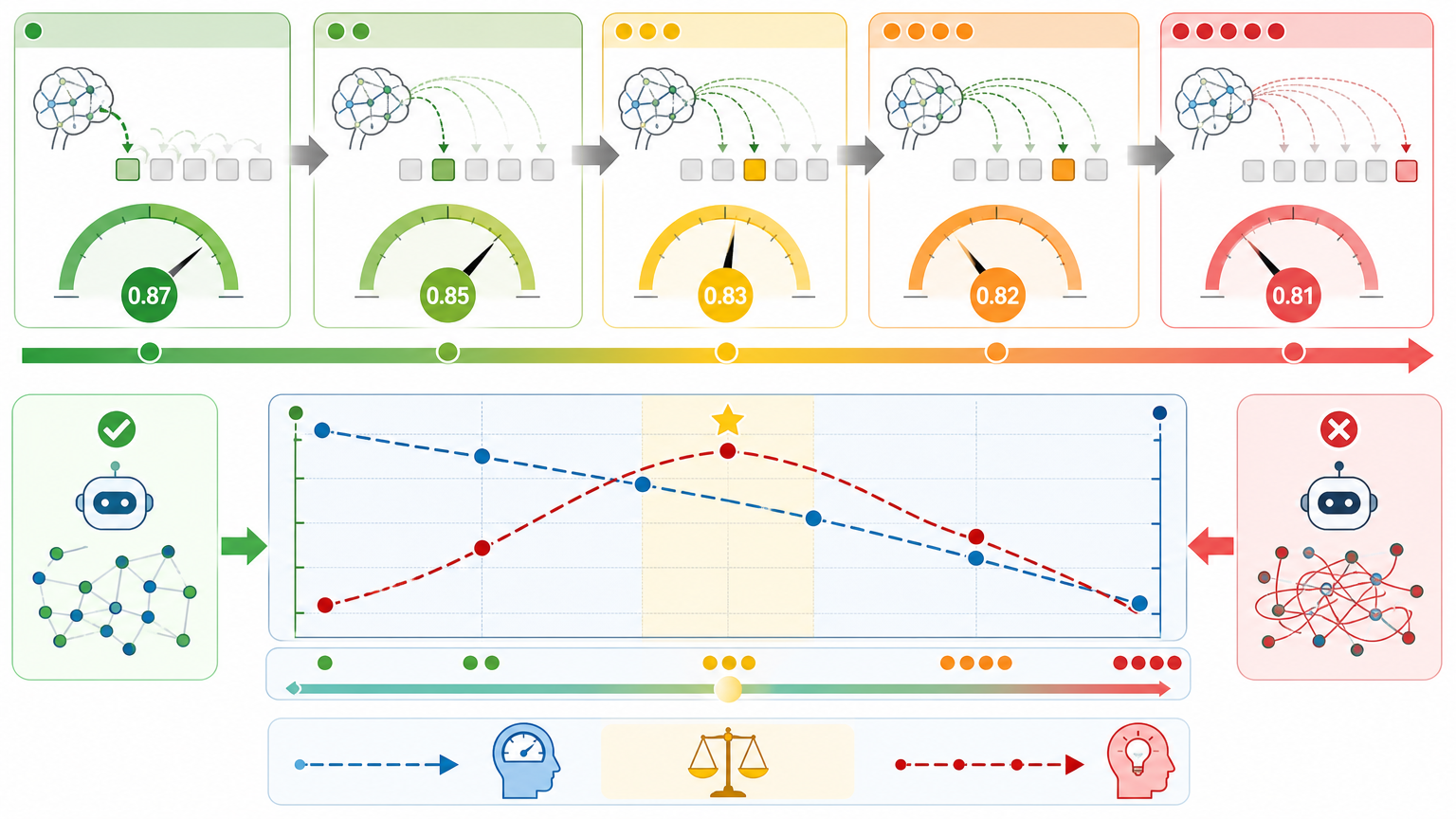
这就像人类做决策:如果一个人每一步都追求绝对正确,反而容易陷入局部最优,错过全局的好方案;而那些愿意在当下保留一点弹性,给未来留有余地的人,往往能做出更长远的正确选择。传统NTP训练的模型,就像那个每一步都要走“最正确”的人,看似自信,实则短视。
当然,Next-ToBE也有它的边界:当分给未来词的注意力过多时,模型会因为过于“瞻前顾后”而降低效率,推理准确率也会随之下降。找到“当下确定”和“未来前瞻”的平衡点,正是它的精妙之处。
我们总以为,AI的智慧应该是每一步都绝对正确,就像精密的机器。但Next-ToBE的研究告诉我们,真正的智能从来不是僵化的确定,而是在流动中与不确定性共舞的能力。
这个研究最动人的地方,不是它让模型的推理能力提升了多少,而是它发现了大模型被隐藏的“潜能”——原来我们一直用错误的方式,束缚着本就存在的智慧。就像给一个擅长长跑的人套上短跑的枷锁,现在只是把枷锁解开而已。
真正的智慧,是不执着于每一步都正确。这句话不仅适用于AI,或许也适用于每一个在人生里做决策的我们。