对抗知识焦虑,从看懂这条开始
App 下载
AI绘图不再靠碰运气,清华团队用控制论解决翻车难题
控制论方法|无分类器引导|AI绘图工具|清华大学段岳圻团队|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载控制论方法|无分类器引导|AI绘图工具|清华大学段岳圻团队|多模态视觉|人工智能
你有没有过这样的经历:给AI绘图工具输入“穿红裙子的女孩站在左侧,金毛犬趴在右侧草坪”,生成的图要么女孩和狗挤在一团,要么红裙子变成了粉衬衫,要么草坪直接消失在画面外。调参数、改提示词,折腾半小时生成几十张,才能勉强挑出一张能用的——这种“靠碰运气出图”的尴尬,几乎是每个AI绘图用户的共同记忆。而现在,清华大学段岳圻团队的一项研究,把这个“碰运气”的过程,变成了像开自动挡汽车一样的可控操作。
要理解这个突破,得先搞懂AI绘图的核心矛盾。现在主流的文生图工具,靠的是一种叫“无分类器引导(CFG)”的技术——你可以把它想象成一个音量旋钮,调大“音量”,AI会更努力贴合你的文字描述,但同时也更容易“炸麦”:画面过曝、细节扭曲、逻辑混乱;调小“音量”,画面质量上去了,却又完全不听指令。
这不是AI的“脾气差”,而是CFG本质上是一种简单的线性控制,就像用一根直棍去掰弯一根弹簧——用的力越小,弹簧回弹越多;用的力太大,弹簧直接崩断。而AI绘图的扩散模型本身是个复杂的非线性系统,就像在湍急的河流里划船,用固定力道的船桨根本没法稳定控制方向。
过去的研究者要么在“旋钮刻度”上反复微调,要么给AI加更多的“规则约束”,但都没跳出“线性控制”的框架,始终卡在“要对齐语义就得牺牲画质”的死结里。
清华团队的思路,是直接换了一套操作逻辑——不再把CFG当成“音量旋钮”,而是把整个AI绘图的扩散过程,看成一个需要精准控制的动态系统。他们引入了控制论里的“滑模控制”技术,给AI绘图加了一套“自动导航系统”。
你可以把这个过程想象成开车:以前你只能踩油门或刹车,要么冲太快偏离路线,要么太慢到不了目的地;现在有了自适应巡航,系统会根据路况自动调整车速,始终把车保持在车道中央。滑模控制就是给AI绘图加的这个“巡航系统”——它设定了一条“滑动模态面”,就像车道线,不管生成过程中出现什么偏差,系统都会自动调整方向,把图像拉回符合语义的轨道上。
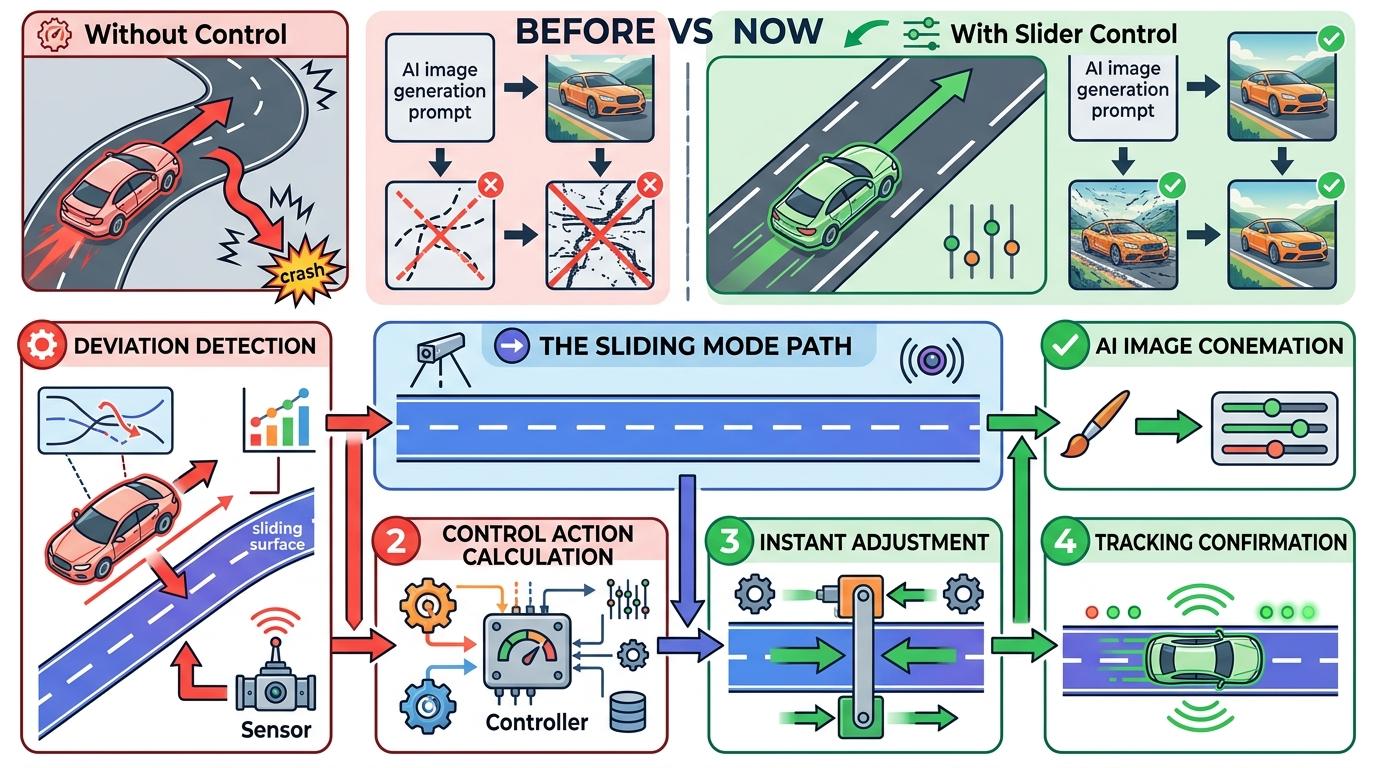
实验数据给出了最直接的证明:在Stable Diffusion 3.5、Flux、Qwen-Image三款主流模型上,这种叫SMC-CFG的新方法,在语义对齐指标CLIP上的表现稳定领先传统CFG,同时图像质量指标FID还能进一步降低——这意味着它第一次真正打破了“语义对齐”和“画质”的死结。更关键的是,模型规模越大,优势越明显,在超大规模的Qwen-Image上,它能在高引导尺度下完全避免画面崩坏,而传统CFG早就把图生成了“抽象画”。
当然,这套系统也不是完美的。研究团队发现,控制收敛速度的λ和控制纠正力度的k,必须找到一个精准的平衡:λ太小,AI会“反应迟钝”,半天对齐不了语义;λ太大,又会“矫枉过正”,画面出现不必要的波动;k太小,纠正力度不够,k太大,画面又会变得僵硬。只有中等λ搭配适中k,才能让系统既稳定又高效。
对普通用户来说,这个研究最直接的好处是“少翻车”——以后不用生成几十张图才能挑出一张能用的,输入一次提示词,就能得到符合要求的稳定结果。但对AI生成领域来说,这个突破的意义远不止于此。
过去,AI绘图的控制靠的是“经验调参”,就像老中医开药方,全凭感觉;现在,清华团队把它变成了一套有理论支撑的“系统控制”,就像现代医学的精准治疗。这意味着未来的AI生成模型,不再是一个“黑箱”,而是可以用控制论、动力学等成熟理论去设计、优化的工程系统。
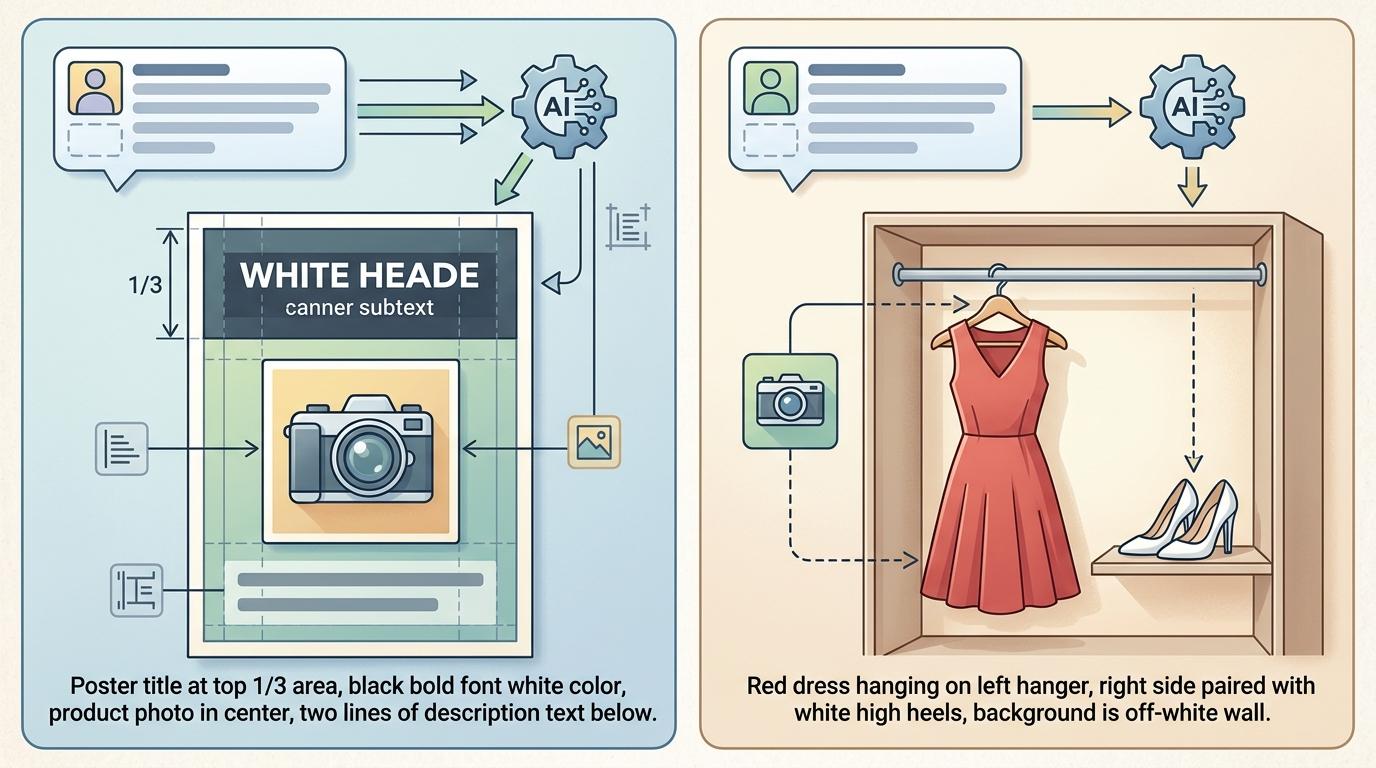
比如,以后设计师可以直接给AI输入“海报标题在顶部1/3区域,字体为黑体白色,产品图在中央,下方加两行说明文字”,AI就能精准生成符合要求的设计图,而不是现在这样反复调整位置、字体、大小;电商运营可以输入“红色连衣裙挂在左侧衣架,右侧搭配白色高跟鞋,背景为米白色墙面”,AI就能稳定生成用于商品详情页的标准化图片,不用再靠摄影师反复拍摄、修图。
不过,这个技术也不是万能的。目前它在处理极端复杂的逻辑关系时,比如“桌子上的杯子里装着半杯水,杯子左侧有一本打开的书,书的页码是第123页”,还是可能出现细节偏差。而且,它的计算成本比传统CFG略高,要大规模应用还需要进一步优化效率。
当我们还在为AI的“创造力”惊叹时,清华团队的研究给我们提了一个醒:AI的“可靠”,比“惊艳”更重要。就像我们不需要一辆能飞但经常失控的汽车,我们需要的是一辆能稳定把我们送到目的地的汽车。
从“碰运气出图”到“可控生成”,这个突破不是让AI变得更“聪明”,而是让AI变得更“靠谱”。靠谱的AI,才是真正能走进日常的AI。未来,当我们用AI生成设计图、商品图、内容插图时,不用再靠反复试错去碰运气,而是像使用任何一个成熟工具一样,精准、稳定、高效——这才是AI生成技术真正的价值所在。