对抗知识焦虑,从看懂这条开始
App 下载
清华团队破局视觉Transformer:线性复杂度也能高精度
线性计算复杂度|注意力机制|TTT范式|ViT³模型|清华大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载线性计算复杂度|注意力机制|TTT范式|ViT³模型|清华大学|多模态视觉|人工智能
当你用手机刷4K短视频、自动驾驶系统识别前方百米的行人和路牌时,背后的AI模型正面临一场算力危机:传统视觉Transformer处理长序列的计算量会随序列长度平方暴涨,就像用算盘算航天轨道——理论可行,但慢到失去意义。
2026年CVPR最佳论文候选名单里,清华大学团队的ViT³模型给了一个新答案:他们把Transformer最核心的注意力机制,改成了一个「测试时还在偷偷学习」的动态过程。这个叫TTT的范式,让模型既能保持线性计算复杂度,性能还追上了传统大模型。更关键的是,他们把这套方法的门道拆解成了6条可复制的设计原则——相当于给后来人递了一张高精度地图,而不是一堆零散的零件。
你可以把传统Transformer的注意力机制想象成一本固定的词典:每个查询词(Query)都要在整本词典的键(Key)里找匹配,然后输出对应的值(Value)。词典越大,翻找的时间就越长,这就是平方复杂度的根源。
线性注意力试图解决这个问题,但它的思路是把词典压缩成一本薄册子——虽然快了,但很多关键信息也被挤没了,性能自然打折扣。
TTT的思路完全不同:它不做固定词典,而是给了模型一个「临时编词典」的能力。在每次推理时,模型会用当前输入的Key-Value对,快速训练出一个轻量化的内部模型——就像拿到一段新文本后,先花10秒编一本专属小词典,再用这本小词典去查词。这个内部模型的计算量是线性的,而且因为是「量身定制」,表达能力比粗暴压缩的线性注意力强得多。

用更技术的话来说,TTT把注意力操作重新定义为一个在线学习过程:通过自监督重建损失,在测试时用梯度下降动态更新内部模型权重,把上下文信息压缩到可训练的权重里,而非固定的向量中。
TTT的灵活度是一把双刃剑——设计空间太大,很容易陷入试错的迷宫。清华团队通过上百组实验,终于提炼出6条让视觉TTT模型既快又准的原则:
1. 选对损失函数,别让梯度「躺平」 那些二阶混合偏导数为零的损失函数(比如MAE)会导致外层梯度消失,模型根本学不进去。点积损失、MSE这类光滑可导的损失才是正确选择,能让梯度稳定流动。
2. 全批量训练,别搞小批次折腾 视觉数据不需要语言那样的因果依赖,用整个序列做一次全批量训练,比拆成小批次反复更新效果更好,还能避免批次间的干扰。
3. 内部学习率别太小,要给模型「冲劲」 实验显示,内部学习率设为1.0时效果最优——太小的话模型更新太慢,太大则容易训练失控。这个数值刚好能让内部模型快速适配当前输入,又不会跑偏。
4. 优先扩宽度,别盲目加深度 增加内部模型的宽度(比如MLP的隐藏层维度)能持续提升性能,但增加深度反而会导致优化困难——深层内部模型会出现欠拟合,训练损失比浅层模型还高,这是因为元学习的特性让深层模型的初始参数和梯度更新都更难优化。
5. 卷积是视觉TTT的天生搭档 把内部模型换成小卷积网络,比如3x3深度可分离卷积,能完美融合局部空间信息和全局上下文,比纯MLP结构的准确率高出1%以上——这刚好贴合视觉数据的空间特性。
6. 别贪多,单轮训练足够 多轮内部训练虽然能提升一点性能,但会让推理速度暴跌。单轮全批量训练在性能和效率间找到了最优平衡。
基于这6条原则,清华团队构建了纯TTT架构的ViT³模型。在ImageNet-1K分类任务上,ViT³的准确率达到83.5%-85.5%,超越了Mamba等线性复杂度模型,和ConvNeXt、InternImage等主流卷积模型性能相当,同时保持了线性计算复杂度和高并行推理速度。
但ViT³还不是终点——传统TTT每次更新只覆盖几十个Token,GPU利用率不到5%,太浪费硬件资源。另一项名为LaCT的研究解决了这个问题:它把每次更新的Token范围扩展到数千甚至数百万个,GPU利用率直接拉满到接近理论峰值,还能处理百万级Token的超长序列,甚至支持140亿参数的视频扩散模型。
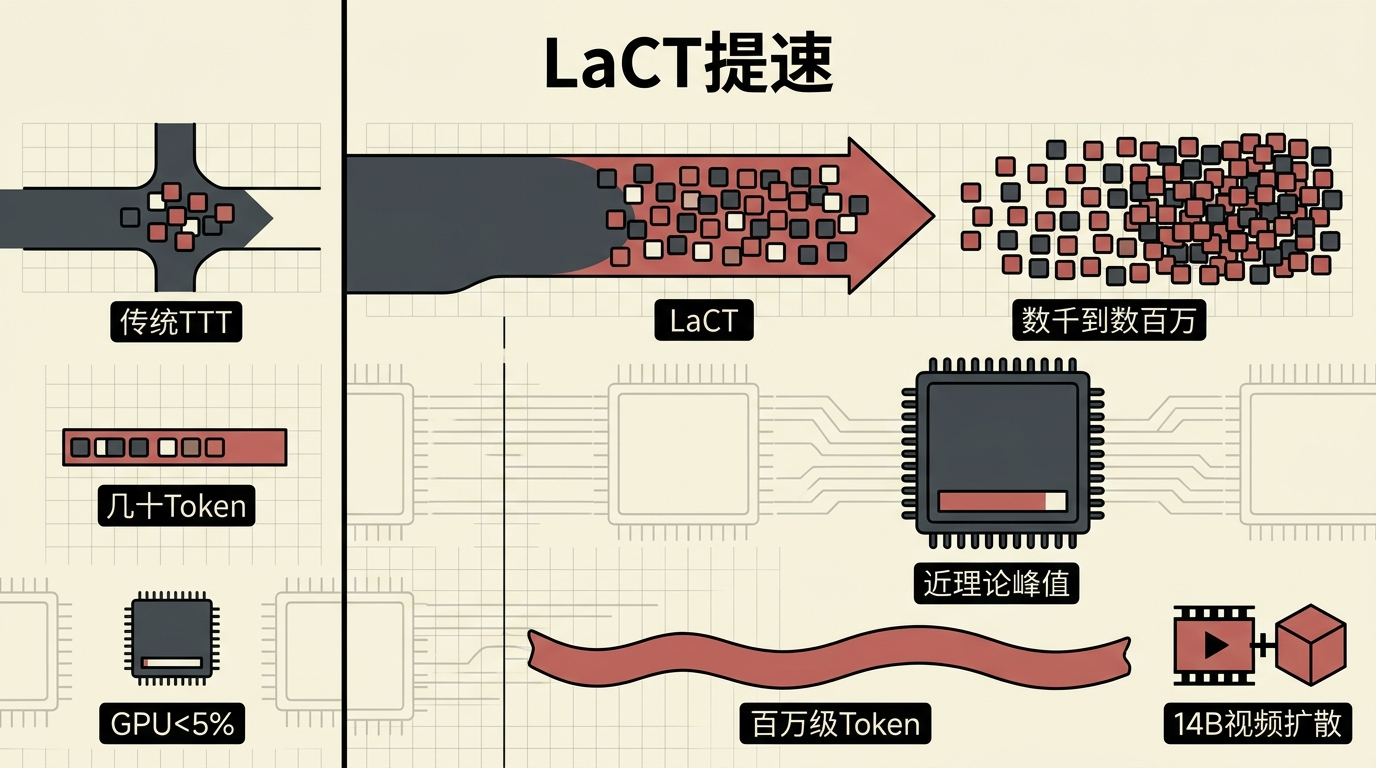
更重要的是,LaCT不需要定制复杂的CUDA核,普通开发者也能轻松实现——这为TTT从实验室走向产业应用扫清了硬件障碍。
当我们还在为大模型的参数竞赛欢呼时,清华团队的研究给了一个重要的提醒:有时候,比堆参数更有价值的,是换个角度重新理解问题。
TTT范式的本质,是让模型在测试时也能保持「学习能力」——这打破了「训练完就固定」的传统AI思维,就像给模型装了个实时更新的大脑。未来,随着深层内部模型优化难题的破解、更高效自监督任务的探索,TTT或许能让视觉AI在低算力设备上也能处理超高清视频、医疗影像这类复杂任务。
好的AI模型,不该只在训练时聪明,更要在干活时会学习。