对抗知识焦虑,从看懂这条开始
App 下载
告别手动标注,清华AI让细胞研究“无中生有”?
自动标注|亚细胞结构|显微图像数据|清华大学|多模态视觉|分子细胞生物学|生命科学|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动标注|亚细胞结构|显微图像数据|清华大学|多模态视觉|分子细胞生物学|生命科学|人工智能
在生命科学的宏伟叙事中,我们正处在一个黄金时代。超高分辨率显微镜让我们能以前所未有的清晰度,窥探细胞内部那个繁忙而精密的微观宇宙——细胞器穿梭往来,细胞骨架聚散离合,生命活动在此上演。然而,在这场视觉盛宴背后,一个巨大的瓶颈却将无数科学家困在了“最后”一公里:如何解读这海量的图像数据?
长期以来,答案近乎于一种“手工业”式的苦差。研究人员需要像刺绣工一样,在屏幕前花费数周甚至数月,手动圈点、勾勒、标注成千上万张显微图像中的亚细胞结构。这不仅耗时费力,极大地拖慢了研究进程,而且人工标注的偏差也像幽灵一样,时刻影响着数据分析的准确性。尽管深度学习(AI)的出现带来了曙光,但它“贪婪”的本性——对海量标注数据的依赖,让这个瓶颈愈发显得难以逾越。我们能看见一个新世界,却缺少一张高效、精准的地图去导航。
就在近日,清华大学生命科学学院欧光朔教授的课题组,在国际顶尖期刊《细胞生物学杂志》上投下了一颗“重磅炸弹”。他们发布了一项名为SynSeg的全新方法,彻底颠覆了游戏规则。这项研究的核心结论石破天惊:他们成功训练出一个强大的AI模型,能够精准分割多种亚细胞结构,而整个训练过程,完全不需要任何一张真实的手工标注图像。
这听起来像是科幻小说里的情节,AI如何凭空学会理解复杂的细胞结构?这项由博士生郭正阳作为第一作者的研究,为细胞生物学研究的自动化与定量化,推开了一扇全新的大门。
SynSeg的成功,源于一个极其深刻且反直觉的理念:要让AI学会识别真实世界,并不需要给它看完美的复制品,而是要让它在“比真实更真实”的挑战中淬炼成长。
研究团队没有试图用复杂的物理建模去精确模拟每一个细胞器的所有细节,这在计算上是极其昂贵且低效的。相反,他们采取了一种“抓本质”的策略:
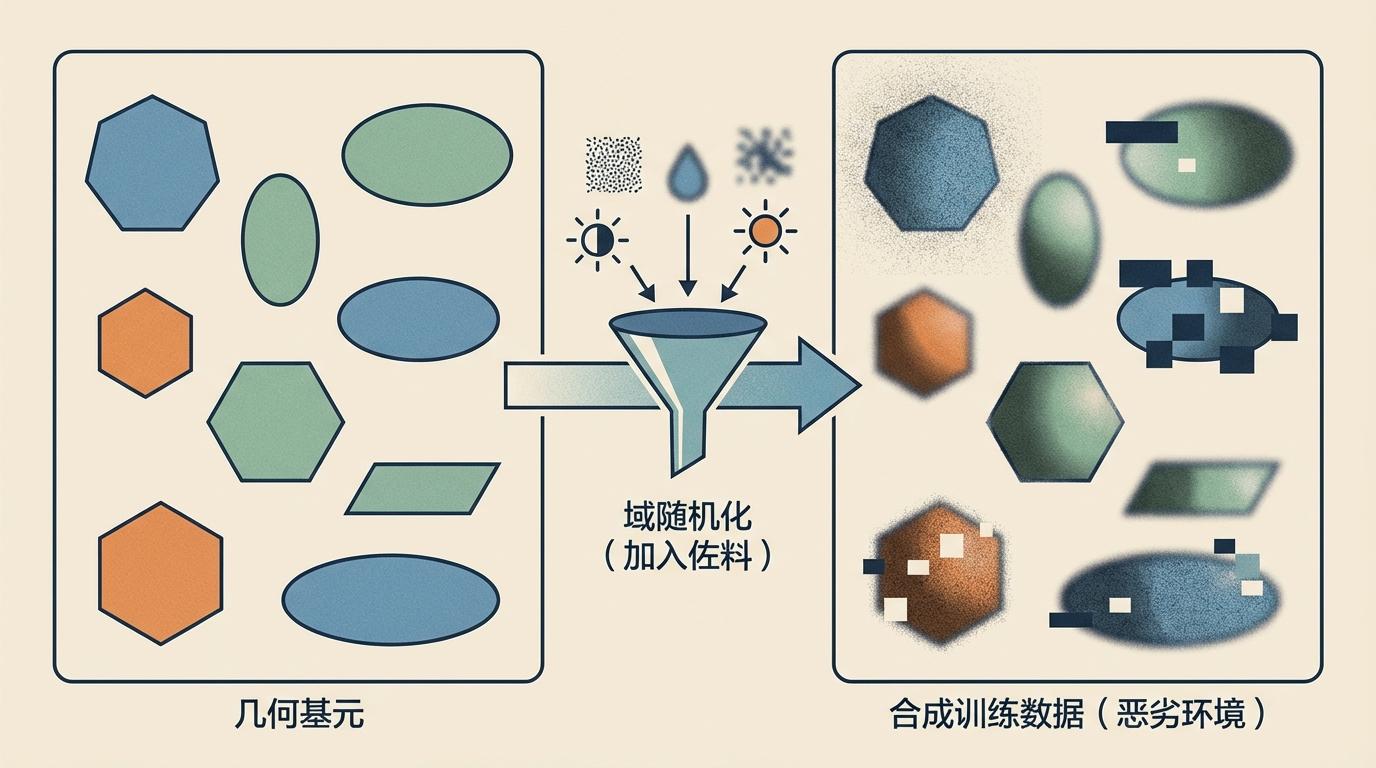
这就好比训练一名飞行员,不仅让他在风和日丽的模拟器中练习,更让他置身于狂风、暴雨、浓雾等各种极端天气组合中。当这位飞行员回到现实世界时,正常的飞行条件对他而言已是游刃有余。SynSeg正是通过这种“极限施压”式的训练,迫使AI模型学会识别结构形态的本质,而不是死记硬背特定图像的像素模式,从而获得了惊人的鲁棒性和泛化能力。
这场“虚拟训练”的效果如何?SynSeg在真实世界的测试中交出了一份近乎完美的答卷。
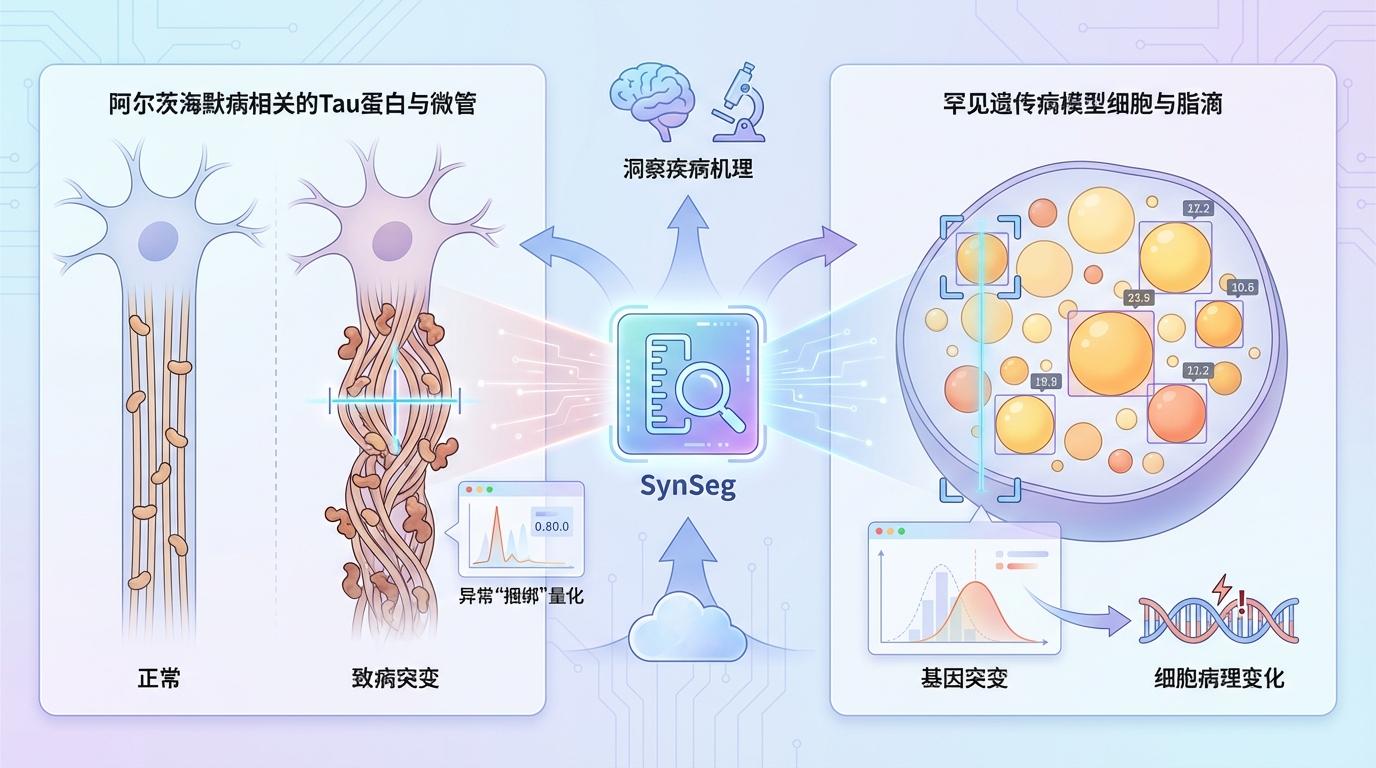
SynSeg证明了,一个优秀的自动化分析工具,能够将科学家从繁琐的劳动中解放出来,真正聚焦于数据背后的生物学问题,加速从基因到表型、再到疾病机理的研究进程。
SynSeg的突破并非横空出世,它站在了人工智能与生命科学交叉领域长期探索的肩膀上。AI的“数据饥渴症”是整个行业的共同痛点。过去,研究者们尝试了多种方法来缓解这一问题:
SynSeg的路径则更为彻底和优雅。它绕过了对真实数据的直接依赖,通过“第一性原理”——即从目标的几何本质出发,构建了一个高效、可控且几乎无限的数据生成引擎。这标志着在生物图像分析领域,一种**“合成数据驱动”的新范式**正在崛起。它不仅解决了数据标注的成本问题,更重要的是,它提供了一种全新的、更深刻的理解和训练AI模型的方式。
尽管SynSeg已经取得了巨大成功,但它也开启了更多的可能性和挑战。合成数据的质量和多样性如何进一步提升?如何确保模拟的几何特征能够覆盖所有未知的生物学形态?这些都是未来需要探索的问题。
更激动人心的是,SynSeg这样的技术,正是通往生命科学终极梦想——构建“虚拟细胞”——的关键基石。正如AlphaFold通过学习蛋白质的结构规则,实现了对蛋白质三维结构的精准预测一样,科学家们也梦想着有一天能够创建一个AI模型,模拟和预测细胞在各种遗传或环境扰动下的动态行为。
要实现这一宏伟目标,就需要海量的、标准化的、可解释的定量数据,而这正是SynSeg所开启的自动化、高通量分析范式所能提供的。它让我们离那个可以通过计算来设计实验、预测疾病、筛选药物的“计算细胞生物学”时代,又近了一大步。
从这个角度看,SynSeg的贡献远不止于一个聪明的算法。它是一种思想上的解放,证明了通过巧妙的抽象和模拟,我们可以教会机器用一种更接近本质的方式去理解复杂的生命世界。这场“无中生有”的智慧,正在为我们揭示生命微观宇宙的奥秘,开辟一条全新的探索之路。