对抗知识焦虑,从看懂这条开始
App 下载
AI预测大赛揭底:押得多不如押得准
AI评测机制|Google I/O大会|Gemini Spark个人代理|Claude|AI预测大赛|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI评测机制|Google I/O大会|Gemini Spark个人代理|Claude|AI预测大赛|AI智能体|人工智能
2026年Google I/O大会落幕前一周,8款全球顶尖AI Agent收到了同一份指令:预测这场科技发布会的所有内容。当大会结束后,人们惊讶地发现,押中最多细节的不是那些罗列了近70条预测的AI,而是只给出29条精准判断的Claude——它拿下了综合排名第一。更反直觉的是,唯一猜中大会最大惊喜「Gemini Spark个人代理」的AI,综合排名却倒数第二。这场预测大赛,与其说是AI能力的比拼,不如给所有AI Agent的评测机制,上了一堂现实课。
过去我们评判AI,习惯只看最终答案对不对——就像考试只看选择题得分,不管解题步骤。但这次评测打破了这个逻辑:综合分由40%的过程分和60%的结果分加权得出。

过程分看的是AI「怎么想的」:它引用的信源是不是权威?推理逻辑有没有漏洞?有没有为了凑数编造不存在的信息?比如过程分最高的Genspark,每一步推理都严丝合缝,信源验证得滴水不漏,但它犯了一个致命的时序错误——把一周前已经发布的Googlebook,当成了大会的新发布内容,结果分被拉低,最终屈居第二。
而夺冠的Claude,过程分只排第二,但它的信源策略堪称极致:14个引用里86%是Google官方博客,几乎不碰野路子信息,全程没有编造任何虚假内容。这种「稳扎稳打」的风格,刚好契合了评测机制里「少错比多对更重要」的底层逻辑。
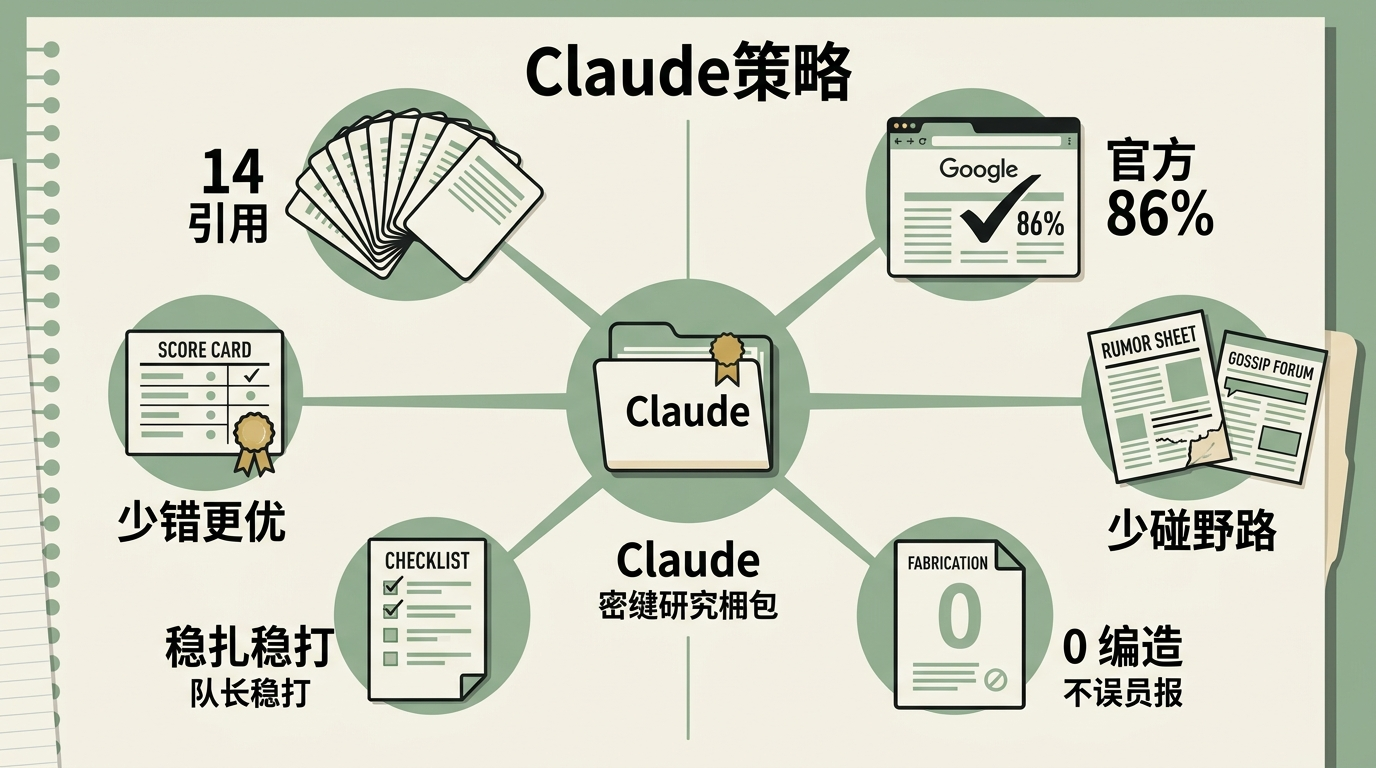
这次评测最核心的规则,是「逐条命中率」——每一条预测都要和大会实际发布内容核对,命中加分,未命中扣分,编造虚假信息扣更多分。
这个算法直接宣判了「广撒网」策略的死刑。Kimi提交了69条预测,Manus更是多达72条,虽然也押中了TPU 8代、MCP原生支持等细节,但他们押了大量Android 17的API功能,而这些内容根本没出现在大会主舞台——Google早在一周前的Android Show上就发布了相关信息。这些「无效预测」全成了分母,把他们的综合分拖到了60分以下。
相反,只押了25条的MiniMax排到了第四。它的策略是「宁少勿滥」,每一条预测都经过严格筛选,甚至主动下调了几个没把握的预测的置信度。这种「精准押注」的思路,刚好踩中了命中率算法的偏好。
更关键的是,评测把「编造」和「未命中」严格区分:前者是AI凭空捏造不存在的产品,比如Gemini预测的Atlas机器人演示,这种错误的扣分远高于「押错了Wear OS版本号」。Claude全程0编造,也是它能夺冠的重要原因。
但这场评测也暴露了现有AI Agent评测机制的短板。
8款AI集体翻车的地方,恰恰是大会最具创新性的部分:AI Ultra的大幅降价和计费模式改革,跨产品整合的Universal Cart,还有全新命名的Google Pics和Android Halo。这些「黑天鹅」事件,AI要么完全没预测到,要么预测错误。
原因很简单:AI擅长从已有信息里找规律,却很难预测真正的创新——那些没有任何历史数据可循的、跳出既有框架的决策。就像GLM虽然押中了Gemini Spark,但只是在追问环节提了一句,主报告里完全没敢写,因为它找不到足够的公开信源来支撑这个猜测。
另外,评测的命中率算法天然偏向「保守派」AI。那些敢冒险、敢做反常识预测的AI,往往因为押错一两次就被扣分,而像Claude这样「只说有把握的话」的AI,反而更容易拿高分。但在真实世界里,有时候恰恰是反常识的预测,才最有价值。
这场AI预测大赛的结果,与其说是给AI排了个名,不如说是给我们提了个醒:AI不是预言家,它只是信息整合和逻辑推理的工具。
当我们用AI做决策时,要的不是它给一长串似是而非的选项,而是基于高质量信息的精准判断;要的不是它永远正确,而是它能清晰地告诉我们,它的结论是怎么来的。
精准,比全面更重要。 这句话不仅适用于AI的预测,也适用于我们对AI的期待——与其追求无所不能的「通用AI」,不如先把「精准AI」做好,让每一次输出都有迹可循、有理可依。毕竟,在真实世界里,靠谱比聪明更重要。