对抗知识焦虑,从看懂这条开始
App 下载
AI终于学会说“我不知道”,还能省1/3算力
推理步骤置信度|Beta-Binomial模型|诚实开关|新加坡科技设计大学|华盛顿大学|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推理步骤置信度|Beta-Binomial模型|诚实开关|新加坡科技设计大学|华盛顿大学|大语言模型|人工智能
你有没有遇到过这种AI:解数学题时每一步都给出0.95以上的自信分数,最后答案却错得离谱?它不是故意撒谎,而是根本不知道自己哪一步开始跑偏了。传统AI推理就像一个永远嘴硬的学生,哪怕没把握也硬要给出一个确定答案,这种“自信的错误”在医疗、金融等关键场景里隐患极大。2026年5月,华盛顿大学和新加坡科技设计大学的团队,给AI装上了“诚实开关”——让它既能给推理步骤打分,又能坦诚说出“这个分数我有多确定”。更关键的是,这个小小的改变能在几乎不降低准确率的情况下,把AI推理的Token消耗砍掉1/3。
你可以把传统过程奖励模型(PRM)想象成一个只会打分数的老师:对学生的每步解题过程,它只会给出0-100的分数,却从不说明这个分数的可信度——是基于扎实知识的判断,还是凭感觉给的?实际训练中,这个“分数”来自16次蒙特卡洛采样的成功比例,比如16次里有10次做对了,就给0.625分。但问题是,16次采样的随机性很大,这次是10次下次可能是8次,传统模型会硬着头皮去拟合这个充满噪声的单点,很容易把采样误差当成真实规律。
BETAPRM的核心创新,是用Beta-Binomial分布重新建模这个过程:它不再把16次采样的成功次数当成固定标签,而是假设每步推理的真实成功概率本身是一个有波动的范围。模型会输出两个参数:一个是类似传统分数的均值μ,代表它判断的成功概率;另一个是浓度κ,代表它对这个判断的置信度——κ越大,说明这个分数越靠谱,κ越小,说明不确定性越高。
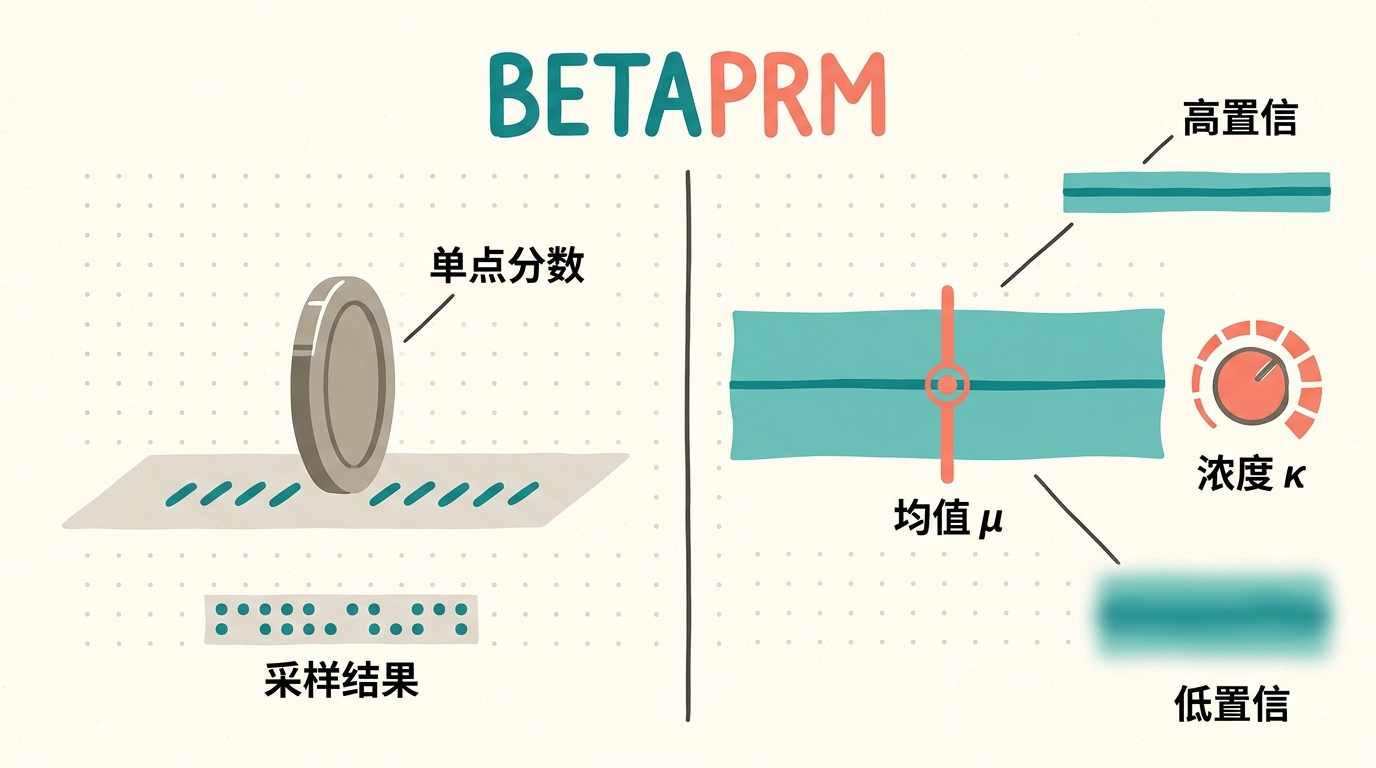
用做饭打个比方:传统模型只会说“这个菜咸度合适(0.8分)”,而BETAPRM会说“我有90%的把握,这个菜咸度合适(μ=0.8,κ=18)”,或者“我觉得这个菜咸度合适,但只有50%的把握(μ=0.8,κ=2)”。为了防止模型“瞎自信”,训练时还加了一个正则化项:如果模型给出的均值和实际采样结果差得远,还敢说自己很确定,就会被惩罚。
有了置信度信号,AI推理就能实现“按需分配算力”,这就是自适应计算分配(ACA)机制。传统的Best-of-N推理是不管三七二十一,固定生成16个候选答案再选最优,哪怕其中某个候选一开始就遥遥领先,也要浪费算力生成完所有16个。ACA则像一个聪明的面试官,一旦确定某个候选人明显优于其他人,就提前结束面试;如果暂时分不出胜负,就针对最不确定的部分再深入考察。
具体来说,ACA分三步运行:首先生成一小批候选答案,用BETAPRM给每个答案的每一步打分并标注置信度;然后计算当前最优候选的“下置信界”——也就是它最差情况下的可能分数,和其他候选的“上置信界”——也就是它们最好情况下的可能分数,如果最优候选的最差情况都比别人的最好情况好,就直接停止生成;如果不行,就找出当前最有竞争力的候选,把它置信度最低的推理步骤截断,重新生成后续内容,相当于“针对薄弱环节再考一次”。
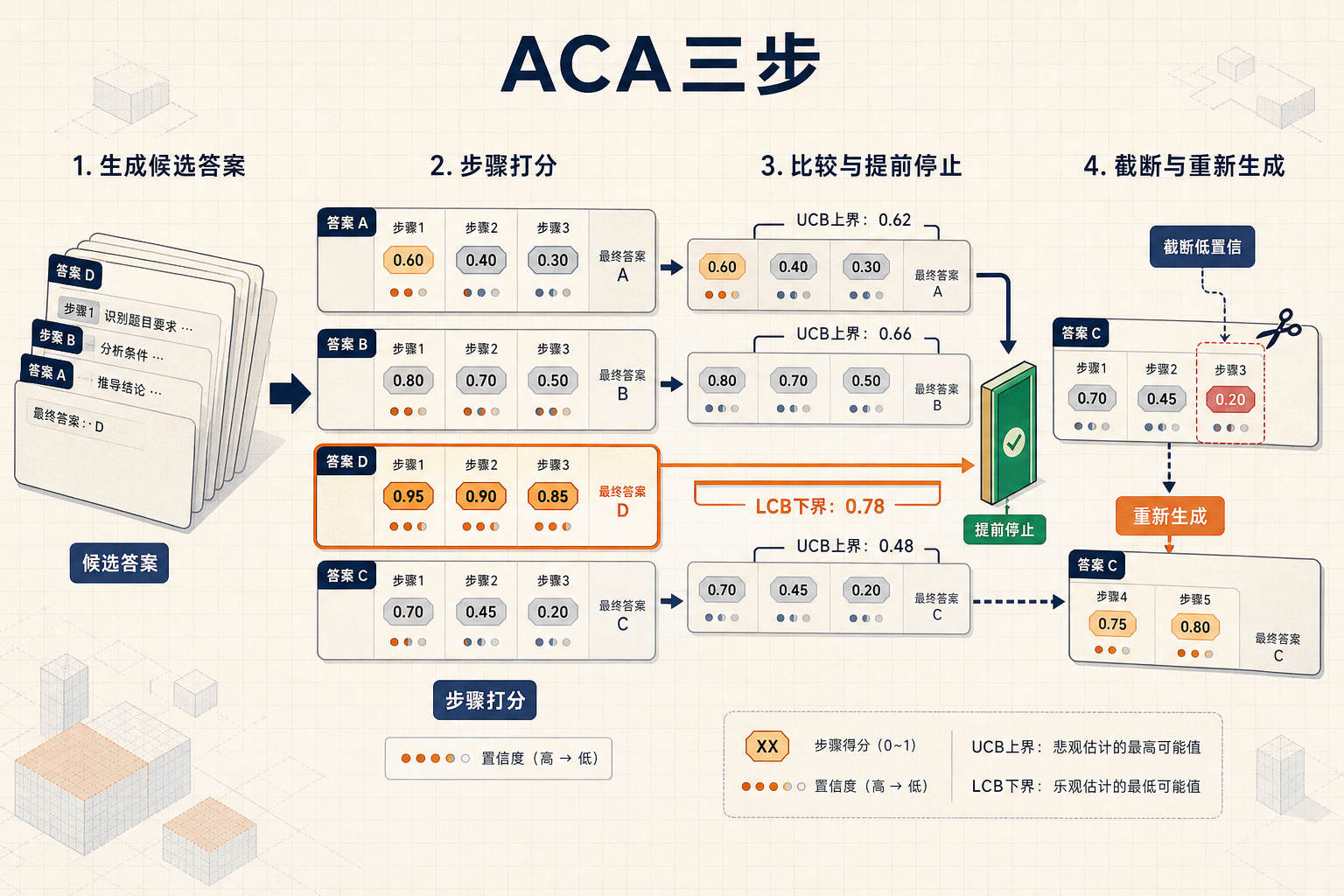
实验数据显示,这种动态调整能在保持甚至小幅提升准确率的情况下,把Token消耗减少16.7%到33.6%。比如用InternVL2.5-8B模型在MathVision数据集上测试,传统方法准确率25.00%,Token消耗12.3千;用ACA后准确率升到26.32%,Token消耗降到8.1千,直接省了1/3还多。
目前BETAPRM的实验主要集中在数学和视觉推理场景,在4个不同的多模态骨干模型、4个数学推理基准上,它都比传统PRM平均提升了1.3到3.4个百分点的准确率,而且在步骤级错误检测任务上表现和传统模型相当,甚至略有提升——这说明引入置信度信号并没有牺牲模型对具体步骤对错的判断能力。
但它的潜力不止于此。这种“让AI学会表达不确定性”的思路,完全可以推广到文本推理、强化学习、人机交互等更多场景:比如在客服AI中,当它对用户问题没有把握时,直接转人工而不是硬着头皮回答;在强化学习中,当模型对某个动作的后果不确定时,优先选择更保守的策略;在医疗AI中,给诊断结果附上置信度,让医生能更合理地参考AI建议。
当然,当前方法也有局限:训练需要每步都有蒙特卡洛采样的成功计数,数据采集成本较高;而且只在数学推理场景验证过,能不能泛化到其他领域还需要更多实验。但不可否认的是,它给AI推理指出了一个新方向:比起让AI“假装什么都知道”,让它“知道自己不知道”,才是迈向可信AI的关键一步。
我们总期待AI能给出确定的答案,就像小时候期待老师给出唯一的标准答案。但真实世界里,不确定性才是常态——医生看病会说“大概率是感冒,但不排除肺炎”,法官判案会考虑“证据链的可信度”,就连我们自己做决策时,也会权衡“这件事我有几分把握”。
BETAPRM的意义,不止是提升了AI推理的效率和准确率,更在于它让AI开始学会像人类一样思考:不追求绝对的确定,而是在不确定性中给出负责任的判断。**可信的AI,从学会说“我不知道”开始。**未来的AI不该是一个永远自信的判官,而该是一个坦诚的顾问——既能给出专业建议,也能如实告知建议的风险,让人类最终掌握决策的主动权。