对抗知识焦虑,从看懂这条开始
App 下载
2498个AI化学家联手,把合成成功率提至95%
化学实验流程|AI专家系统|分子结构合成|耶鲁大学|MOSAIC系统|催化化学|AI产业应用|数理基础|人工智能
对抗知识焦虑,从看懂这条开始
App 下载化学实验流程|AI专家系统|分子结构合成|耶鲁大学|MOSAIC系统|催化化学|AI产业应用|数理基础|人工智能
当化学家盯着一个从未合成过的分子结构时,过去的第一反应往往是——先查几百篇文献,再准备三个月的试错。但耶鲁大学的一套AI系统,把这个流程压缩到了几分钟:输入分子结构,它直接给出能进实验室操作的完整步骤,连试剂用量、加热时长、提纯方法都精确到细节。更夸张的是,它对37种全新化合物的首次合成成功率达到了95%,甚至搞定了文献里公认“做不出来”的反应。这不是什么全能大模型,而是2498个“AI专家”的集体智慧——MOSAIC系统。为什么一群“专科AI”,反而比通才大模型更靠谱?
你可以把整个化学合成知识想象成一个巨大的写字楼,每个房间里坐着一个只懂某类反应的专家——比如102室专管氯代芳香环的偶联反应,307室只研究氮杂吲哚的环化。MOSAIC做的第一件事,就是用一套算法把这座写字楼精确划分成2498个“沃罗诺伊单元”——每个单元都是一个专家的专属地盘,边界由反应的相似性决定。
核心的划分工具是KMN神经网络,它能把每一个化学反应转换成一串128维的数字向量,也就是“反应特异性指纹”。两个反应的向量距离越近,就说明它们的机理、底物越像。再用FAISS这个高效检索工具把所有向量聚类,那些挤在一起的向量就形成了一个个专家的“工位”。
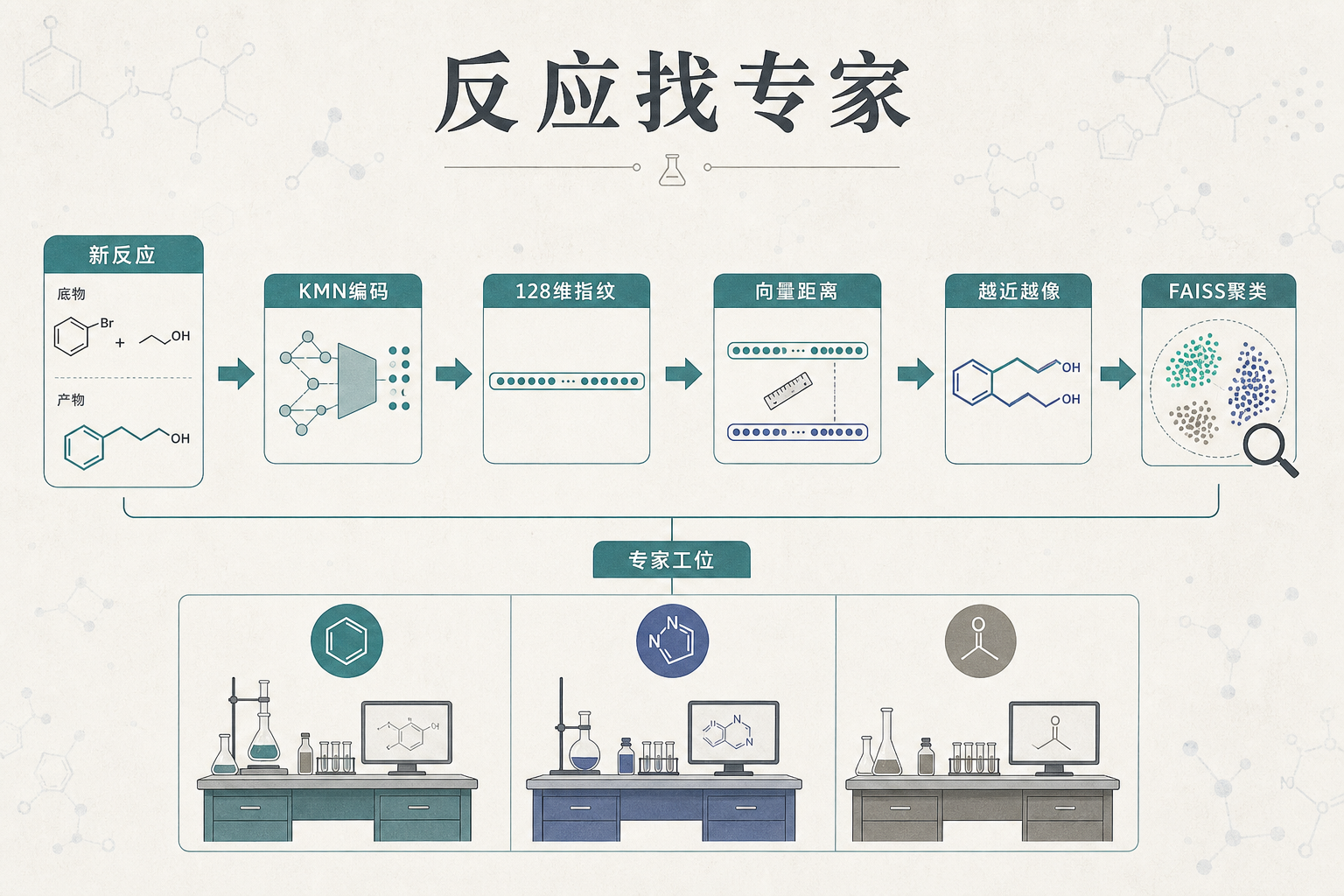
训练的时候先让一个基础模型把所有反应扫一遍,再针对每个工位的细分数据做二次微调。就像先让每个实习生了解公司全貌,再派去特定部门深耕。这种“先通后专”的方式,既避免了单一模型的“样样通样样松”,又不用像训练全能大模型那样烧掉几百张GPU卡——MOSAIC只需要几张卡就能跑通。
当你输入一个新反应时,MOSAIC不会像通用大模型那样瞎编,而是先算出这个反应的向量指纹,然后在2498个工位里找距离最近的几个专家。比如那个文献里说“做不出来”的5-氮杂吲哚衍生物,系统算出它的向量距离最近的专家工位有320——远高于通常150的置信阈值,意味着这几乎是个没人碰过的新领域。
但MOSAIC没有放弃,它激活了几个相邻工位的专家,让它们一起“会诊”。结果这些专家基于各自的领域知识,拼出了一条从未被报道过的环化路径。研究人员照着步骤做,居然一次就成功了。
更实用的是,MOSAIC会给每个预测附上一个“靠谱度分数”:向量距离小于100时,实验成功率超过75%;大于200时,成功率降到50%左右。过去只有资深化学家能凭经验判断的“这个反应值不值得试”,现在变成了一个可量化的数字。如果对单个专家的结果不放心,还能让多个专家投票——预测试剂时,单个专家的精确匹配率只有22.4%,三个专家投票后直接翻倍到43%。
更值得关注的是,MOSAIC解决了一个长期被忽视的问题:化学知识的“碎片化”。每年上百万篇化学论文发表,没有任何一个化学家能读完,更别说把这些分散的知识串起来。通用大模型虽然能记住一些知识点,但它的“记忆”是模糊的、容易出错的。
而MOSAIC的专家分区架构,相当于给每一类反应都建了一个标准化的“知识抽屉”。新的反应数据进来,不用把整个系统推倒重来,只需要新增一个抽屉或者给已有抽屉添点东西就行。这种“去中心化”的设计,让资源有限的学术实验室也能持续给系统“喂数据”——不用买几百张GPU卡,几张A100就能让系统不断进化。

这和我们过去对AI的想象不太一样:不是要训练一个无所不知的“超级大脑”,而是要搭建一个能不断吸纳、整理专业知识的“知识网络”。就像一个不断扩容的图书馆,每个书架都由最懂这个领域的人打理,你要找答案时,直接去最相关的书架找就行,不用翻遍整个图书馆。
MOSAIC的成功,其实是给AI的“全能神话”泼了一盆冷水——在高度专业的领域,一群分工明确的“专科生”,往往比一个样样都学的“优等生”更有用。它让我们看到,AI不一定非要模仿人类的“通用智能”,有时候,把人类擅长的“分工协作”做到极致,反而能解决更实际的问题。
未来的AI化学助手,或许不会是一个能和你聊所有化学问题的“聊天机器人”,而是一个能精准找到最懂这个反应的“专家”,并把他们的知识整合成可执行方案的“调度者”。专业的事,交给专业的AI。当AI终于学会了“攒知识”而不是“装知识”,化学实验室里的试错成本,才真正开始降低。