对抗知识焦虑,从看懂这条开始
App 下载
AI不用看全图,靠“指点”搞定复杂推理
引用差距|坐标点输出|空间推理|迷宫导航|北大清华团队|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载引用差距|坐标点输出|空间推理|迷宫导航|北大清华团队|多模态视觉|人工智能
当你盯着手机里的迷宫图,指尖会不自觉跟着路径点划——这是人类天生的思考习惯:边指边想,让模糊的语言锚定具体的空间。但直到最近,AI还做不到这件“简单事”:它能看懂图里的每一个像素,却在数清一堆密集的小球、走出复杂迷宫这类任务上频频出错,甚至凭空编造不存在的路径。
2026年五一前,一支联合了北大、清华的团队悄悄捅破了这层窗户纸:他们让AI像人一样,在推理时同步输出精确的坐标点和边界框,把模糊的语言思考牢牢绑定在视觉空间上。结果在迷宫导航这类拓扑推理任务中,AI的准确率直接甩开了当前顶尖模型10个百分点以上。这背后,是一个被忽略了很久的AI瓶颈——引用差距。
你可以把AI的多模态推理想象成一场“看图说话”的考试:题目是“找出左边那只白狗,数清它身边的红球数量”。过去的AI就像一个只会读题的考生,能看到图里的所有元素,但当它用语言描述“左边那只”“身边的”时,这些模糊的指代就像没系紧的线,推理到后半段就会脱钩——要么把右边的狗当成目标,要么数漏了藏在阴影里的球。
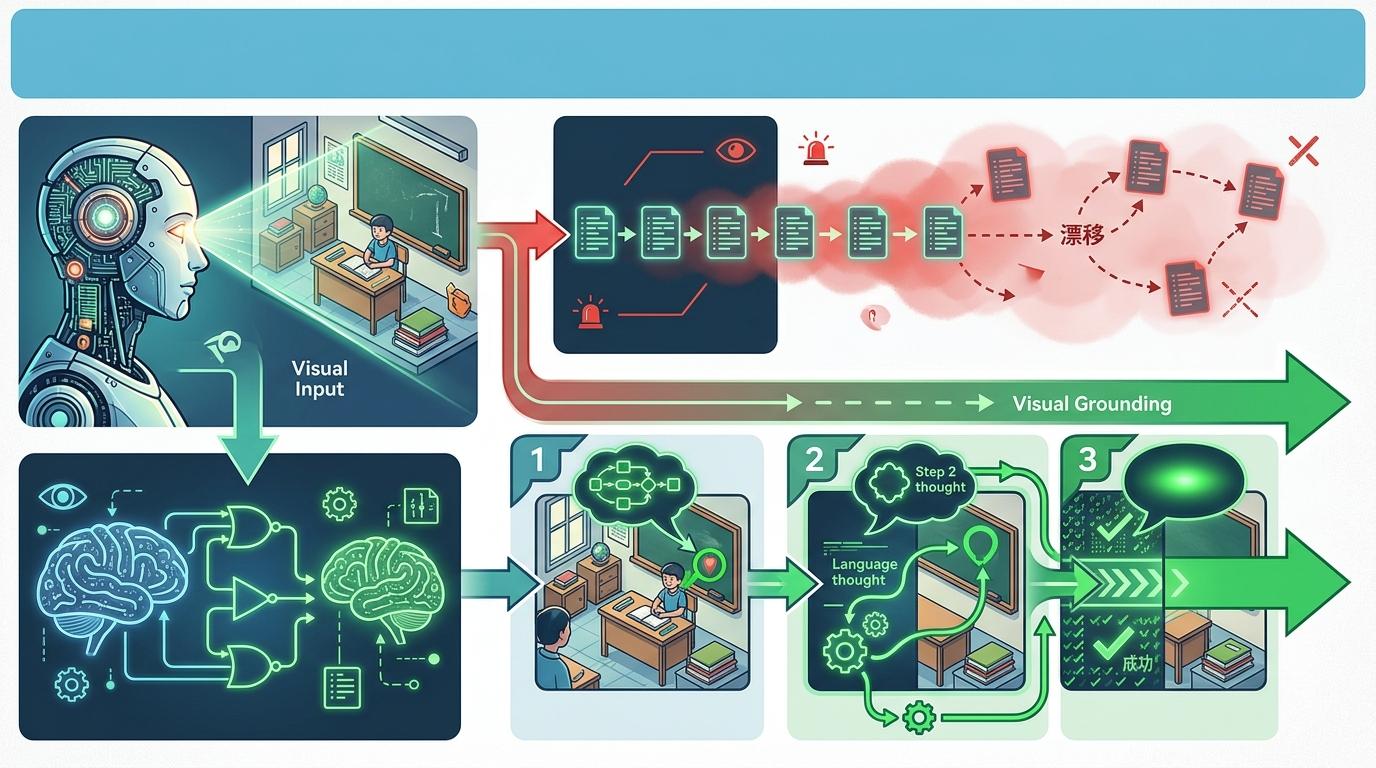
这就是引用差距(Reference Gap):自然语言天生是模糊的,无法像人类的手指那样,在连续的视觉空间里精准锚定一个物体。当推理链条变长,语言会彻底失去对视觉实体的追踪,AI就开始“胡言乱语”。
过去半年,主流的多模态模型都在拼命“练视力”:用更高分辨率的镜头、更精细的图像切割,让AI“看清”更多像素。但这支团队的研究指出,就算给AI一双完美的眼睛,它在拓扑推理、密集计数这类任务上还是会崩——问题根本不在“看不见”,而在“指不准”。
解决思路直接照搬人类的思考习惯:让AI边“指”边“想”。
团队给AI引入了视觉原语(Visual Primitives)——这就像给AI装了一根能在图上标记的手指:遇到需要定位的物体,它会输出一个边界框坐标,把“白狗”锚定在[[50,447,647,771]]这个精确区域;遇到需要规划路径的迷宫,它会输出一串连续的点坐标,把[[357,369],[260,372]]这类路径节点嵌进推理链里。
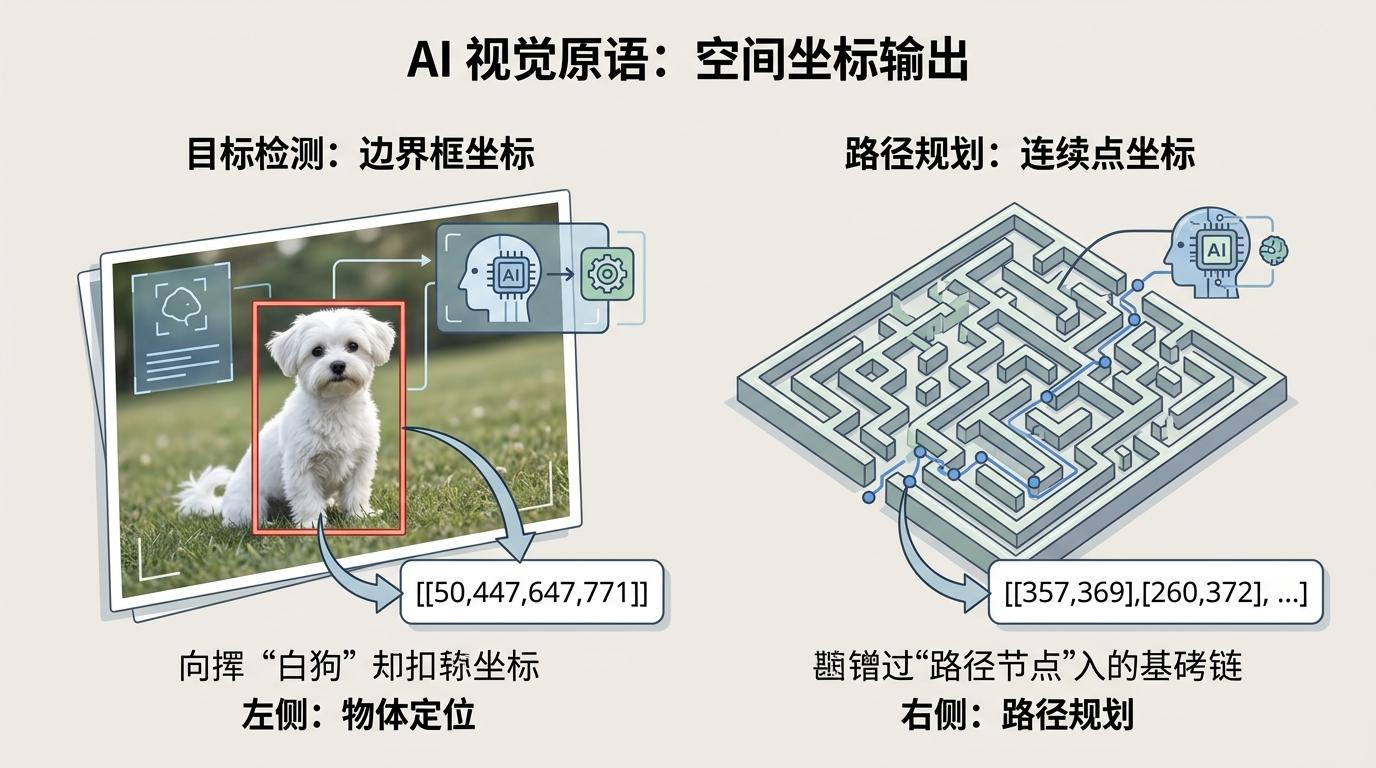
你可以把这个过程理解成:AI不再只用语言写“解题步骤”,而是在步骤里同步标注“我现在盯着这里”“我下一步要走到这里”。这种“边推理边落点”的方式,把语言思考牢牢绑定在具体的视觉实体上,从根源上避免了推理漂移。
为了让AI熟练掌握这根“手指”,团队的训练方式相当“硬核”:他们爬取了近10万个视觉数据集,经过语义和几何两道筛选,留下3万多个高质量数据源,生成4000万条训练样本。甚至专门设计了“伪可解迷宫”——把死路藏在迷宫中段,逼AI必须一步步标记路径,而不是凭直觉猜出口。
有意思的是,这支团队并没有跟着主流方向“堆视觉token”——相反,他们把视觉信息压缩到了极致。
一张756×756像素的图片,经过视觉编码后会产生2916个基础视觉token,再经过两次压缩,最终只保留81个视觉KV缓存条目——相当于把57万像素的图像,压缩成了81个关键“锚点”,压缩比达到了7056倍。同分辨率下,其他顶尖模型的视觉token数量普遍在800到1100之间,是它的10到13倍。
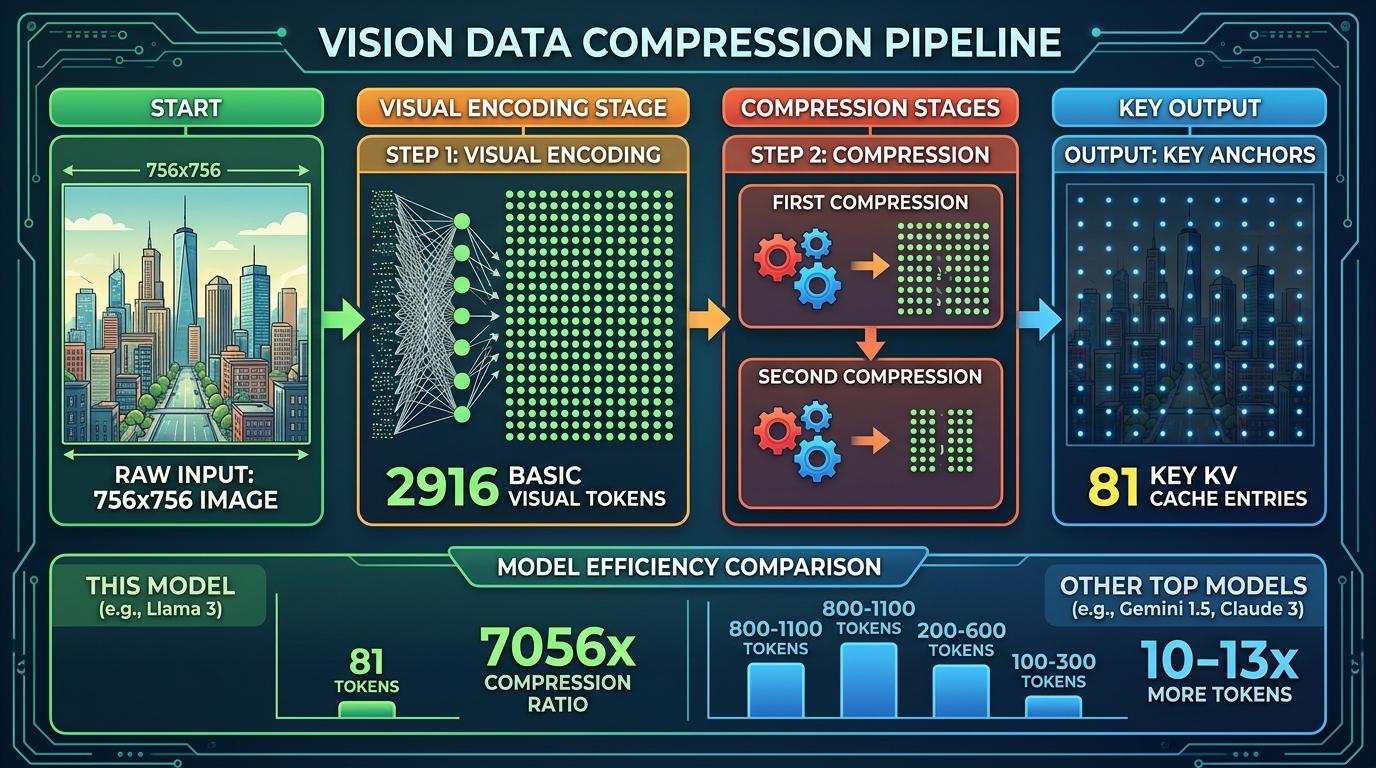
这种极致压缩的底气,来自团队的混合注意力架构:近期的视觉信息用完整注意力,中距离的用压缩注意力,最远的用重度压缩注意力,像人类的工作记忆一样,只聚焦最关键的信息。这不仅大幅降低了计算成本,还让AI能把更多算力用在“精准指点”上——在迷宫导航任务中,它的准确率达到66.9%,而当前顶尖模型只有50.6%;路径追踪任务中,它的准确率56.7%,领先第二名10.2个百分点。
当然,这个模型也有自己的短板:视觉token的上限是384,遇到密集的小目标容易掉精度;它还不会自己决定“什么时候该指点”,需要人类在提示词里触发;甚至在拓扑推理上,它的泛化能力也还局限在训练过的场景里。
当我们谈论AI的多模态能力时,总习惯盯着“它能看懂多少”,却很少想“它能不能精准抓住”。这支团队的尝试,更像是一次认知的回归:AI不需要复刻人类的“视力”,但可以复刻人类“边指边想”的思考逻辑。
从“看清像素”到“精准指点”,这不是一次技术的小修小补,而是多模态AI从“感知”到“认知”的一次小跨步。未来的AI或许不用看遍所有细节,只要像人一样,用一根“手指”锚定关键信息,就能在复杂的视觉世界里,走得更稳、想得更清楚。
看得更少,指得更准,想得更清。