
1 天前
1 天前
当一位生物学家花三个月啃完上百篇文献,终于画出一条RNA序列的优化方向时,GPT-Rosalind只用了17分钟——而且它的预测准确率,超过了95%的人类顶尖专家。这不是科幻片里的场景,是OpenAI刚刚交出的真实测试数据。这款以DNA发现关键人物罗莎琳德·富兰克林命名的AI,正在把生命科学里最耗时、最烧脑的推理工作,压缩到以小时甚至分钟计算的维度。问题是:它到底是怎么做到的?又会把动辄十年起步的药物研发,推到哪条新的赛道上?
你可以把通用大模型想象成一个什么都懂一点的“超级文科生”,能写论文能编代码,但碰到生物实验室里的具体问题——比如怎么设计一套分子克隆的试剂组合,怎么从几十万条基因序列里找出靶点——它就会露怯。而GPT-Rosalind是OpenAI在这个“文科生”的基础上,给它塞进了一整个生命科学图书馆,还专门训练了它“做科研的逻辑”。
它的核心是**垂直领域推理模型**——简单说,就是把“读文献-提假设-找证据-验结论”这套科学家的思考流程,变成了AI能精准执行的算法。比如在RNA序列预测任务里,它不会像通用模型那样凭文本相似性瞎蒙,而是会调用50多个生物数据库里的结构数据、实验数据,先分析序列的折叠方式,再推导它的功能,最后和已知的同类序列做交叉验证。
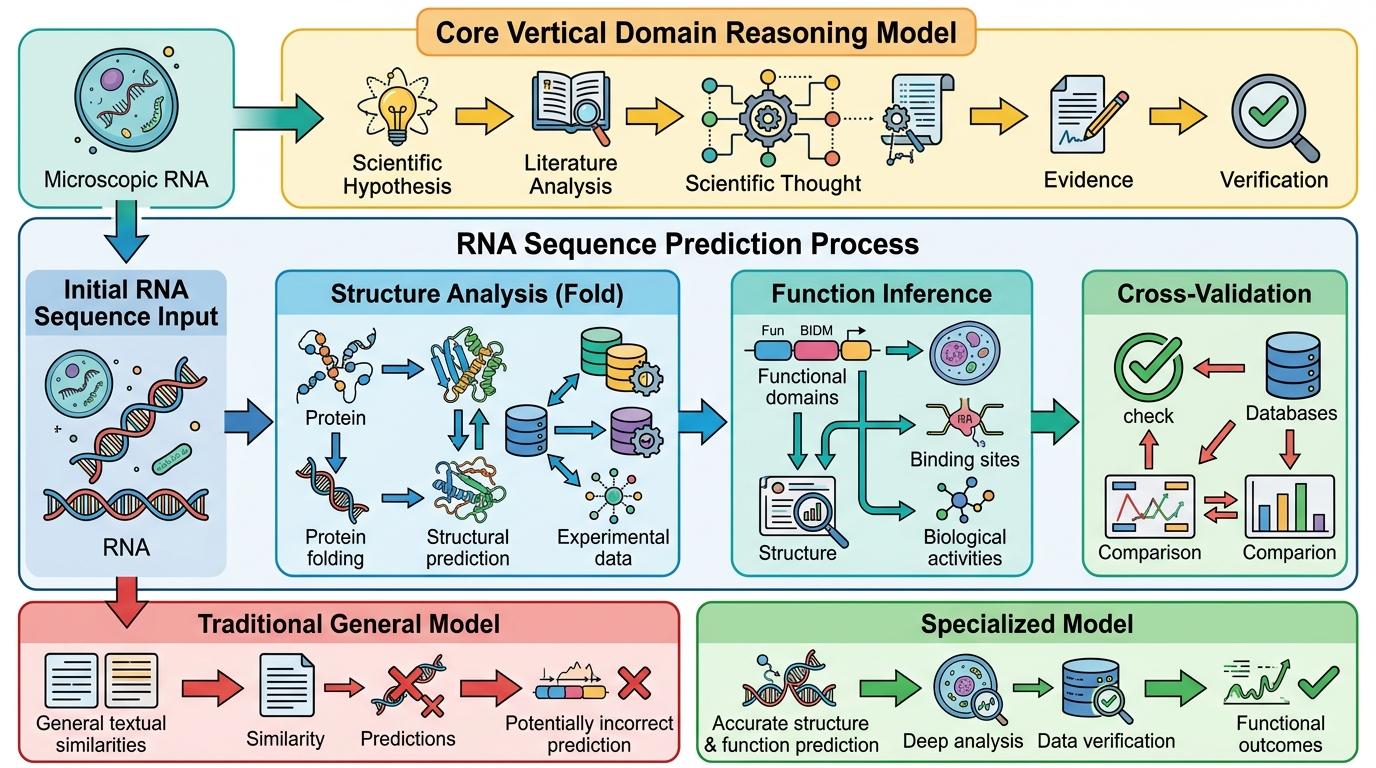
在BixBench这个专门测试AI生物信息学能力的基准里,它打败了包括GPT-5.4在内的所有对手;在CloningQA任务中,它能直接给出从引物设计到酶选的完整实验方案,细节精准到某款试剂的使用浓度。这种能力,已经不是“辅助工具”级别,而是能直接当科研伙伴用了。
如果说GPT-Rosalind的推理能力是“大脑”,那OpenAI同步推出的生命科学研究插件,就是它的“手脚”。过去,一个科学家要完成一次蛋白质结构分析,得先去PDB数据库查结构,再用AlphaFold做预测,然后找工具做分子动力学模拟,每一步都要切换软件、导出导入数据,光是整理格式就得花半天。
这个插件把50多个这样的工具和数据库连在了一起,就像给AI装了一套自动化流水线。你只要说“帮我分析这个突变对蛋白质功能的影响”,它会自动去查相关的文献,调用AlphaFold对比突变前后的结构,用分子模拟工具预测稳定性,最后把所有结果整理成一份带引用的分析报告——全程不需要你打开任何一个专业软件。
更关键的是,这个插件是免费开源的。这意味着不管是顶尖药企的实验室,还是普通高校的课题组,都能用上这套“超级工具箱”。安进的科学家已经用它把靶点验证的时间从3个月压缩到了2周;莫德纳则用它加速了mRNA序列的优化,把疫苗研发的前期流程缩短了40%。
但这里藏着一个容易被忽略的点:它真正改变的不是“做实验的速度”,而是“提假设的效率”。过去科学家可能几个月才能想出3个值得验证的假设,现在AI一天就能给出30个,而且每个都带着数据支撑——这相当于把科研的“试错效率”提高了10倍。
当AI能轻松设计出具有特定功能的生物序列时,一个绕不开的问题也随之而来:怎么防止它被用来设计危险的病原体?
OpenAI给GPT-Rosalind装了两层安全锁。第一层是“前置过滤”,它会自动识别涉及生物武器、毒素设计的请求,直接拒绝响应;第二层是“后置验证”,所有AI生成的序列和实验方案,都会和全球已知的病原体数据库做对比,哪怕是功能相似但序列完全不同的“新型毒素”,也能通过结构同源性检测被揪出来。
但这还不够。目前全球的DNA合成厂商主要靠“序列同源性”筛查订单,也就是对比已知的病原体序列,而AI能设计出和已知毒素功能一样,但序列相似度极低的蛋白——这就像给病毒换了件衣服,能轻松绕过现有的筛查系统。OpenAI的解决方案是,给所有AI生成的序列加上“数字水印”,同时推动厂商升级筛查技术,从“看序列”变成“看结构”。
更值得关注的是,这种“技术突破+风险防控”的模式,正在成为AI进入敏感科研领域的标准。GPT-Rosalind不是第一个,也不会是最后一个——未来每一个能改变行业的AI工具,都得先过“安全合规”这道关。
当安进的科学家用GPT-Rosalind算出的方案,第一次在实验室里得到符合预期的蛋白时,他们可能没有意识到,自己正在见证一场科研范式的转移。过去,生命科学的突破靠的是“试错+运气”——比如青霉素的发现,比如CRISPR的偶然问世;但现在,AI正在把它变成一门“可预测的工程学科”。
AI不是替代科学家,而是给科学家装了加速器。它能帮你把十年的路,压缩成三年;把一百次失败的实验,变成十次精准的验证。但最终,决定我们能走多远的,还是人类对生命本质的好奇——AI只是帮我们把这份好奇,变成答案的速度快了一点。
毕竟,罗莎琳德·富兰克林当年用X射线拍下DNA照片时,靠的不是速度,是不肯放弃的坚持。而现在,AI正在把这份坚持,变成更多人能享受到的健康。
点击充电,成为大圆镜下一个视频选题!