对抗知识焦虑,从看懂这条开始
App 下载
AI的数据瓶颈被攻破?LLM重塑80%数据准备工作
数据映射|数据科学家|企业数据管道|数据清洗流程|数据准备自动化|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据映射|数据科学家|企业数据管道|数据清洗流程|数据准备自动化|大语言模型|人工智能
在每一座由数据驱动的现代企业大厦深处,都流淌着一条至关重要却又老旧不堪的“管道”——数据准备流水线。数据科学家们,就像经验丰富的管道工,日复一日地与这条管道搏斗。他们手持正则表达式的扳手,编写着越来越复杂的清洗规则,试图过滤掉五花八门的“脏数据”;他们耗费心神绘制跨系统的数据映射图,手动对齐那些本应同源却形态各异的表结构。这是一个公开的秘密:数据团队将近80%的时间和精力,都耗费在这场永无止境的“管道维修”上,而真正用于分析和建模的,不过是剩下的20%。

模型迭代的速度已达光年之外,但数据准备的效率却还停留在蒸汽时代。这种巨大的反差,正是企业智能化进程中最顽固的瓶颈。传统方法高度依赖人工与专家知识,像一套僵化的指令集,缺乏对数据背后真实“含义”的感知。然而,就在最近,一篇引爆学术圈的联合综述,如同一道闪电,划破了这片沉寂已久的夜空。
2026年2月,来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)等全球顶尖机构的研究团队,联合发布了一份题为《Can LLMs Clean Up Your Mess?》(大语言模型能清理你的烂摊子吗?)的重磅综述。这篇论文系统性地梳理了大语言模型(LLM)在数据准备领域的应用,并提出了一个颠覆性的论断:我们正处在一场从“规则驱动”到“语义驱动”的范式转移前夜,而LLM,将成为下一代数据管道的“智能语义中枢”。
这不再是科幻。研究者们指出,LLM的介入,让机器首次拥有了“理解”数据的能力。它不再是机械地执行“删除此列空格”或“转换日期格式”等预设规则,而是能够理解“这是一个客户地址,需要标准化”或“这两张表描述的是同一款产品,需要进行实体对齐”。这种从执行指令到理解意图的飞跃,正是重塑整个数据准备流程的关键所在。
该综述将LLM赋能的数据准备过程,清晰地划分为三大核心环节,它们共同构成了智能数据管道的全新蓝图:
数据清洗(Data Cleaning): 这是最基础也最繁琐的一环。LLM能够超越简单的规则匹配,智能识别并修复格式错误、填补逻辑缺失值、标准化不一致的表达。它就像一位拥有常识的编辑,能看懂“纽约市”和“NYC”指的是同一个地方。
数据集成(Data Integration): 当数据来自不同系统时,集成便是一场噩梦。LLM凭借其强大的语义理解能力,可以高效地进行实体匹配(判断不同表中的“苹果 iPhone 15”和“Apple iPhone 15”是否为同一商品)和模式匹配,自动完成跨源对齐,打破数据孤岛。
数据增强(Data Enrichment): 原始数据往往是“贫瘠”的,缺少上下文。LLM可以为数据自动打上语义标签、识别列类型(例如识别一串数字是邮政编码还是产品ID),甚至构建整个数据库的画像,让数据分析师“看得懂、用得好”。
更具实践指导意义的是,论文为工程团队描绘了三条将LLM融入数据准备工作的技术路径,各有侧重,适应不同场景:
基于Prompt的“轻骑兵”模式(M1): 这是最直接、灵活的方式。通过精心设计的提示词(Prompt)和少量示例,直接引导LLM完成特定任务。它非常适合小规模、高复杂度的场景,例如修复一张高价值的核心业务报表。但其缺点也同样明显,在大规模应用中,成本和结果的一致性难以控制。
RAG与混合系统的“主力军”模式(M2): 这是当下最主流的工程选择。它将LLM与检索增强生成(RAG)、传统规则系统或轻量级模型结合,形成混合架构。简单的、重复性的任务交给规则或小模型处理,而LLM则专注于处理“疑难杂症”和核心语义决策。例如,Jellyfish项目探索的“大模型教小模型”蒸馏范式,就是利用GPT-4的推理能力来训练一个更小、更经济的模型,专门用于大规模数据匹配,实现了成本与效果的绝佳平衡。
智能体编排的“未来军团”模式(M3): 这是最具想象力的前沿方向。让LLM扮演“指挥官”的角色,自主规划任务、调用外部工具(如Python库、API)来构建复杂的工作流。例如,CleanAgent项目就构建了一个能自主规划清洗步骤的智能体。尽管目前该路线在稳定性、调试成本上仍面临挑战,但它预示了数据准备走向完全自动化的终极形态。
尽管前景光明,但通往智能数据中枢的道路并非一片坦途。研究团队明确指出了横亘在理想与现实之间的三座大山:
推理成本与延迟: 在企业级TB/PB级别的数据量面前,LLM高昂的推理成本和延迟仍然是规模化应用的最大障碍。追求极致的准确率,可能意味着无法接受的计算开销。
稳定性与幻觉: 在金融、医疗等对数据准确性要求严苛的领域,LLM的“幻觉”问题是致命的。如何确保模型在关键任务中100%可控、可回溯,是工程落地前必须解决的信任难题。
统一评估体系的缺失: 当前,不同的研究采用不同的数据集和评估指标,导致各种方法之间难以进行公平的横向比较。缺乏一个像ImageNet之于计算机视觉那样的“黄金标准”,严重制约了技术的迭代和工程选型。
最终,该综述给出了一个清晰而务实的结论:短期内,用大模型完全取代现有数据管道是不现实的。更可行的路径,是将其作为“语义协调者”或“智能中枢”,嵌入到现有工作流的关键节点。
想象一下未来的数据管道:传统的ETL工具依然在高效地进行大规模的数据搬运和结构转换;而在这个管道的核心位置,一个LLM驱动的语义层正在发挥作用。当业务人员用自然语言提出“查询上季度华东地区所有新品的销售额”时,LLM不再是直接生成可能出错的SQL代码,而是先将这个需求精准地翻译成统一的、蕴含业务逻辑的语义查询语言(MQL),再由高性能的语义引擎将其转换为最优的、经过权限校验的执行计划。
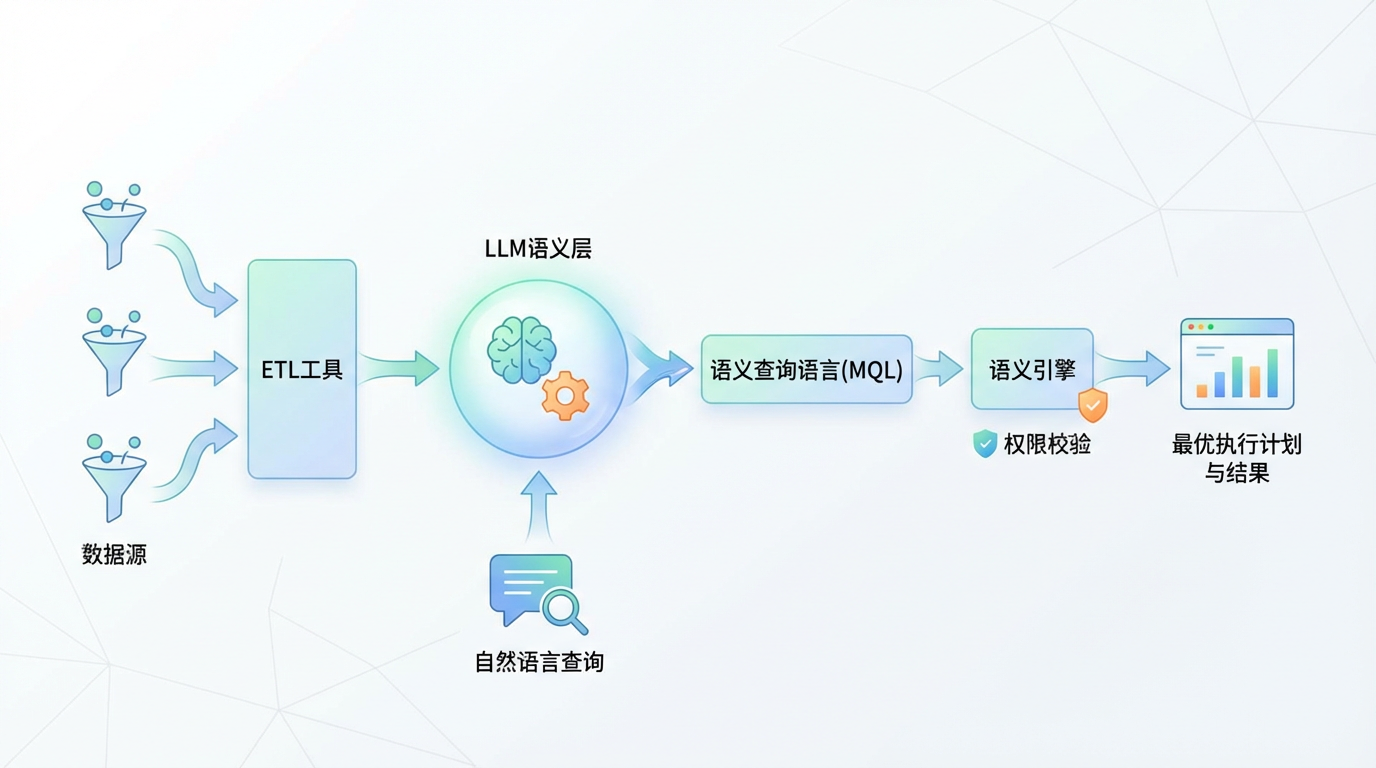
这场由LLM引领的数据准备革命,其核心并非用一种技术推翻另一种,而是一次深刻的“智能化升级”。它将数据工作者的角色从繁琐的“数据杂役”中解放出来,让他们能真正聚焦于洞察与决策。那困扰业界多年的“80%难题”,或许不会在一夜之间消失,但我们终于看到了一条清晰、可行的道路,通向一个数据能真正“理解”我们、并为我们智能工作的未来。