对抗知识焦虑,从看懂这条开始
App 下载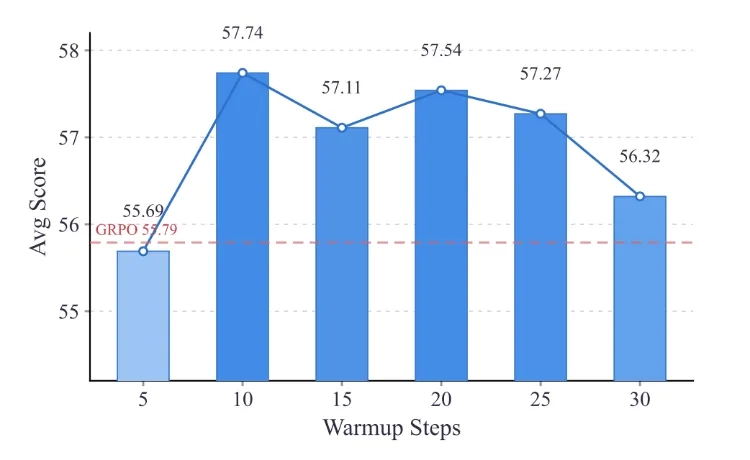
不看题目练推理,大模型找到新捷径
推理能力提升|反常识训练|腾讯AI Lab|新加坡国立大学|中国科学院自动化所|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推理能力提升|反常识训练|腾讯AI Lab|新加坡国立大学|中国科学院自动化所|大语言模型|人工智能
想象一下:让你做数学题,却不给你题目,只告诉你“刚才写的步骤全错了,重写”。你会觉得这是恶作剧,但中国科学院自动化所、新加坡国立大学和腾讯AI Lab的研究团队,真的用这种“反常识”方法,让大模型的推理能力在20步内就实现了跃升——推理过渡步骤增加14.89倍,反思步骤增加6.54倍,训练效率比传统方法快3倍。
这不是玄学,而是摸到了大模型的“认知底层”:经过万亿级数据预训练的模型,早已把推理逻辑藏在了参数里,只是被“必须绑定具体问题”的训练规则限制住了。现在,研究团队要做的,就是拆掉这层限制。
过去训练大模型推理,就像给学生做专项刷题:给一道题(输入x),让模型写解题步骤(输出y),然后根据答案对错给奖励,本质是优化“看到x后输出y的概率P(y|x)”。但问题是,大模型在预训练时已经学过无数数学题、逻辑题的解题逻辑,这些知识就像存在脑子里的“解题模板库”,只是平时做题时,它只会调用和当前题目匹配的模板。
新方法PreRL直接跳过了“题目”这一步,它不管模型面对的是什么题,只看模型写出来的推理步骤本身,直接优化“写出合理推理轨迹的概率P(y)”——相当于不看学生做的是哪道题,只看他写的解题思路对不对,对就强化,错就修正。
你可以把这个过程想象成:老师不看学生的作业题,只看他的草稿纸,只要草稿纸上的推导逻辑是对的,就给他加分,不管他在解哪道题。这样一来,学生就会把精力放在打磨通用的推导逻辑上,而不是死记某类题的解法。

更关键的是,研究团队通过理论和实验验证:这种“直接改脑子”的优化方向,和传统“按题解题”的优化方向高度对齐——也就是说,这么练出来的能力,完全能用在实际解题上,不是空架子。
有意思的是,研究团队发现,在这个“预训练空间”里,正样本强化(给正确推理步骤奖励)几乎没用,甚至会让模型的推理多样性下降——就像让学生反复抄正确答案,最后只会死记硬背,不会灵活推导。
真正起作用的是负样本强化:只给错误的推理步骤“扣分”,也就是告诉模型“你刚才写的这个推导逻辑是错的,以后别这么想”。仅仅20步负样本训练,模型的推理过渡步骤(比如从“已知条件A”推到“可以得出B”)就增加了近15倍,反思步骤(比如“刚才的推导有问题,应该换个方向”)增加了6.5倍,用3倍更少的训练步数就达到了86%的准确率。
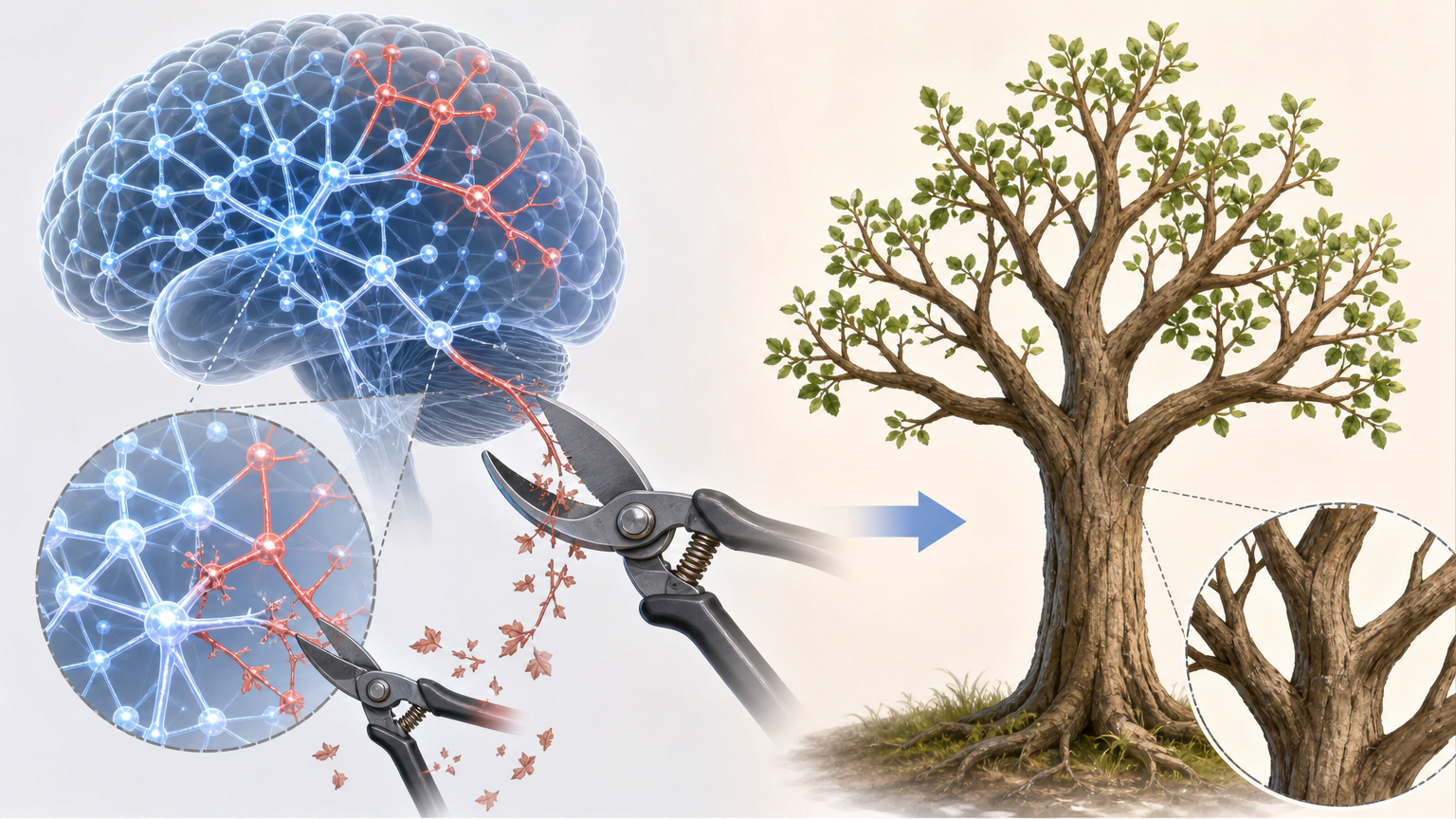
这背后的逻辑很简单:大模型预训练时已经学过无数正确的推理逻辑,但也夹杂了很多错误的“思维定式”。负样本强化就像一把剪刀,快速剪掉那些错误的思维分支,让模型的注意力自然集中到剩下的正确逻辑上。就像给一棵树剪枝,去掉枯枝败叶,剩下的枝干才能长得更粗壮。
当然,这种方法也有局限:只剪枝不引导,模型可能会陷入“为了避免错误而写更长的步骤”的怪圈,导致输出越来越冗长。所以它更适合做“热身训练”,为后续的精细化训练打基础。
研究团队在PreRL的基础上,提出了双空间强化学习(DSRL):先让模型在“预训练空间”里做20步左右的负样本热身,剪掉错误思维分支,激活通用推理能力;再回到传统的“按题解题”空间,用标准强化学习做精细化刷题。
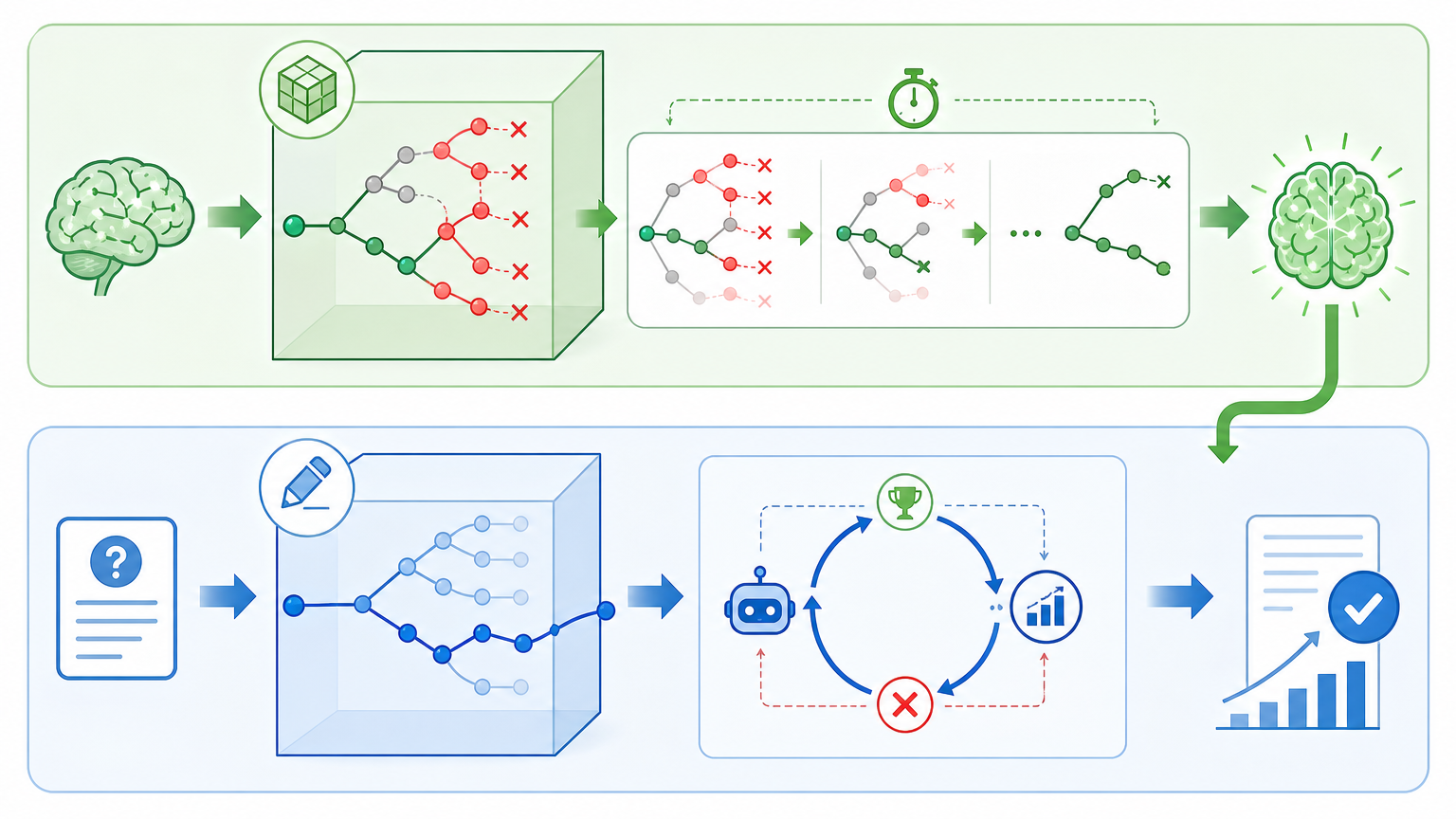
这种组合拳的效果远超单一方法:在MATH500、AMC23等6个数学推理基准测试中,DSRL在Qwen3-4B和Qwen3-8B模型上,全面超越了PPO、GRPO等当前主流的强化学习方法。其中Qwen3-4B在AIME24基准上,比GRPO高出4.69分;Qwen3-8B的平均得分达到58.47,是所有测试方法中的最优解。
更重要的是,DSRL还解决了传统方法的“泛化能力差”问题:在分布外任务(比如没见过的题型、知识密集型任务)上,它的表现也明显更好——Qwen3-4B在GPQA-Diamond(知识问答)上比GRPO高3.79分,在MMLU-Pro(多学科推理)上高5.37分。这说明,经过预训练空间的热身,模型的推理能力不再是“刷题刷出来的应试技巧”,而是真正的“通用逻辑思维”。
不过,这种方法也不是万能的:热身步数需要精准控制,太少激活不了推理能力,太多则会让模型过度发散;而且目前只在数学推理任务上验证了效果,在其他复杂推理任务(比如逻辑推理、代码生成)上的表现还需要进一步测试。
当我们还在纠结怎么给大模型出更多、更难的题时,研究团队已经跳出了“刷题”的框架,直接去激活模型本身已经具备的能力。这就像我们一直以为要让运动员跑得快,就得让他每天跑更多公里,却忘了其实可以先帮他调整呼吸、优化步姿——那些藏在身体里的潜力,才是最值得挖掘的。
大模型的“涌现能力”从来不是凭空出现的,而是预训练时埋下的种子,只是需要合适的方法去唤醒。这次的研究,就是找到了一把唤醒种子的钥匙:与其在“解题”的表层反复打磨,不如直接去优化“思考”的底层逻辑。
好的训练,不是教模型做题,而是教它怎么思考。