对抗知识焦虑,从看懂这条开始
App 下载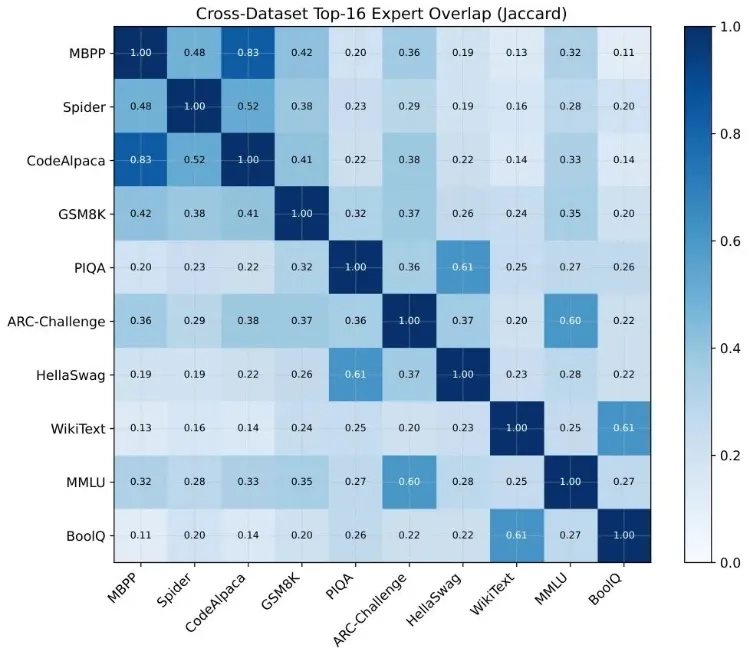
给MoE模型微调砍70%成本,性能几乎没降
参数稀疏化|GPU账单|微调成本|专家路由机制|MoE-Sieve|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载参数稀疏化|GPU账单|微调成本|专家路由机制|MoE-Sieve|大语言模型|人工智能
当你盯着GPU账单上的六位数数字时,可能不会想到:你正在为一群“摸鱼”的模型专家买单。那些动辄百亿参数的MoE大模型,看起来是分工明确的超级团队,实则藏着一个公开的秘密——每层里只有不到三成的专家在真正干活,剩下的七成几乎全程躺平。2026年3月,一项名为MoE-Sieve的研究把这个秘密摆到了台面上:只要给最忙的25%专家“开小灶”,就能砍掉70%的微调成本,性能还和全员微调几乎没差。这到底是怎么做到的?
你可以把MoE模型想象成一个有上百名医生的超级医院:每个病人(输入token)进来,分诊台(路由器)会把他分给最擅长的几个医生(专家)。为了不让医生们太闲,医院管理层(预训练时的负载均衡损失)会尽量让每个医生接待的总病人数差不多——这就是MoE模型“全局平衡”的由来。
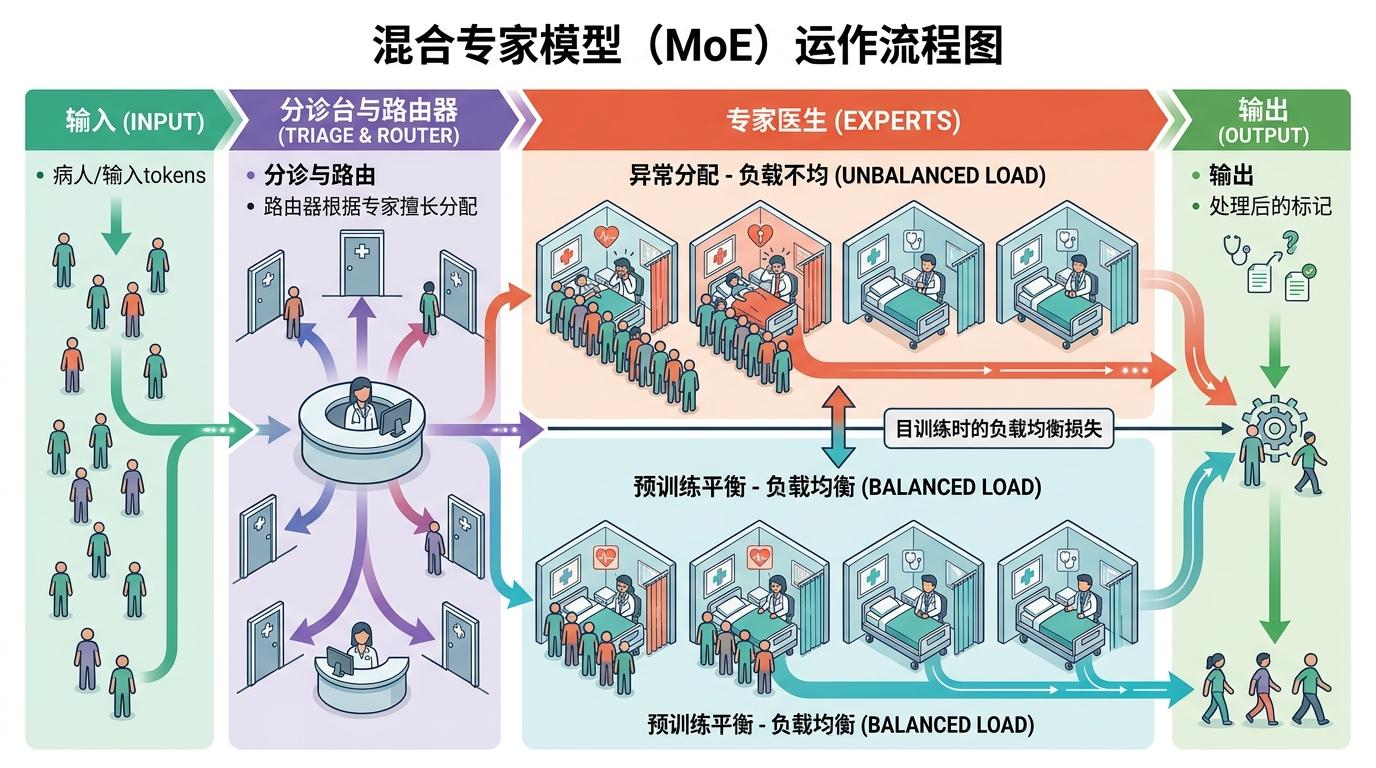
但研究者们发现,这种平衡是“拆东墙补西墙”式的:医生A可能在一楼急诊忙到脚不沾地,到了二楼门诊就闲得发呆;医生B则刚好相反。在任何单独的一层里,病人的分配极端倾斜——用变异系数(CV)衡量的话,层内的失衡程度是全局的4到5倍。
对OLMoE、Qwen1.5-MoE等三个主流模型的统计显示,每层里前25%的“热门专家”,处理了37%到53%的token;而OLMoE里甚至有28.5%的专家,接到的任务量还不到平均水平的一半。这些“冷专家”就像医院里常年坐冷板凳的医生,几乎没机会接触真实病例,自然也没法积累经验。
既然大部分专家在摸鱼,为什么还要给每个人都配备昂贵的LoRA“培训课程”?MoE-Sieve的思路简单到让人拍大腿:直接给专家做“绩效裁员”,只给最忙的那批人培训。整个过程只需要三步,甚至不需要额外的复杂算法:
第一步:统计绩效。拿10%的任务数据跑一次前向推理,不用训练,只记录每层每个专家被选中的次数——就像医院统计每个医生的接诊量。研究者发现,哪怕只用10%的数据,选出来的热门专家和用全量数据的结果重合度极高,足够可靠。
第二步:筛选骨干。在每层里,把专家按接诊量从高到低排序,选出前25%的骨干——比如64个专家里挑16个。这个比例是经过实验验证的最优解:既保证了核心能力,又能最大化节省资源。
第三步:定向微调。只给这些骨干专家挂载LoRA适配器,其他专家直接冻结。但要注意,注意力层、路由器和那些“全科医生”(共享专家)还是要正常微调——毕竟分诊台不能乱,基础的通用能力得保住。
结果惊人:在Spider文本转SQL、GSM8K数学推理等6项任务中,MoE-Sieve的准确率和全员微调的差距都在±1个百分点以内,5项任务达到了统计上的等效性。同时,可训练参数减少了70%-73%,模型检查点缩小了71%-73%,训练时间直接砍半。
有人可能会问:是不是随便选25%的专家都行?研究者做了对照实验:随机选25%的专家微调,性能比MoE-Sieve平均低2-2.5个百分点。更有意思的是,用路由统计选8个专家的效果,比随机选16个还要好。
这说明,路由信号精准地指出了哪些专家是真正“有用”的。不同任务激活的专家集合也完全不同——代码任务和常识推理任务的热门专家重合度极低,就像外科专家和儿科专家的专长完全不重叠。这也反过来证明,MoE模型的专家确实实现了“专业化分工”,而不是随便凑数的。
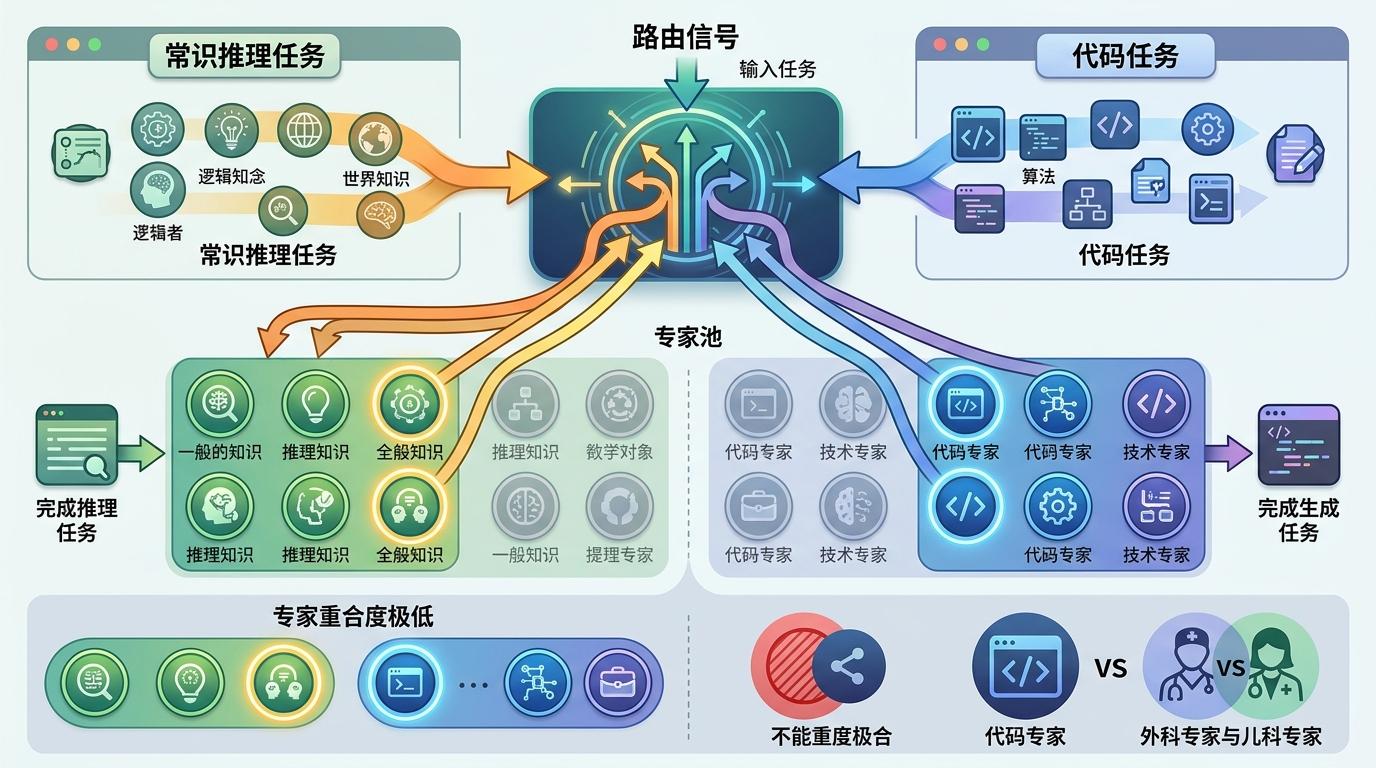
研究者还提出了一个“冷专家噪声源”假说:那些很少被激活的冷专家,微调时得到的梯度信号既稀疏又不稳定,给他们加LoRA不仅没用,反而会像给坐冷板凳的医生强行安排培训一样,引入不必要的噪声,导致训练结果波动更大。实验数据也支持这个假说:MoE-Sieve在5/6的任务中,都降低了不同随机种子下的性能波动,训练更稳定。
当然,MoE-Sieve也有局限:目前只在文本领域的中等规模模型上验证过,25%的筛选比例也只是经验值,缺乏理论支撑;而且它只优化了微调阶段,推理时还是要加载所有专家参数,没法直接加速推理。
当我们为大模型的参数规模疯狂加码时,MoE-Sieve的研究像一盆冷水——它提醒我们,与其追求更大的模型,不如先把现有的模型用透。那些被我们忽略的“低效”细节里,往往藏着最务实的解决方案。
未来,这种“基于数据洞察的极简优化”可能会成为大模型领域的主流:不需要复杂的算法创新,只需要沉下心来,看看模型内部到底在发生什么。毕竟,最好的技术,往往是让用户感觉不到它的存在——就像MoE-Sieve,悄无声息地帮你省了70%的成本,你却几乎感觉不到性能变化。
好的技术,总是在解决真实的问题。