对抗知识焦虑,从看懂这条开始
App 下载
你晒的遗传风险分,可能卖了你的基因
基因型反推|基因隐私|哥伦比亚大学|多基因风险评分|基因组学|公共政策|社会人文|生命科学
对抗知识焦虑,从看懂这条开始
App 下载基因型反推|基因隐私|哥伦比亚大学|多基因风险评分|基因组学|公共政策|社会人文|生命科学
想象一下:你在论坛匿名贴出自己的多基因风险评分——那串用来判断糖尿病、乳腺癌遗传概率的数字,想请教网友怎么解读。你以为只是分享了一个无关隐私的“风险等级”,但实际上,这串数字可能已经把你的基因密码递到了陌生人手里。
2026年初,哥伦比亚大学的研究团队捅破了一层窗户纸:原本被认为“安全”的多基因风险评分(PRS),竟然能被反向破解出高精度的个人基因型。更让人不安的是,只要27个相关基因位点的信息,就能在50万人的数据库里精准定位到你——甚至你的家人。为什么一串汇总数字会变成隐私炸弹?这得从风险评分的底层逻辑说起。
先搞懂什么是多基因风险评分。你可以把它理解成:给你基因组里数十到数千个“基因小标记”——也就是单核苷酸多态性(SNP,简单说就是基因组上的单个字母差异)——每个标记按对疾病的影响程度打个分,最后把所有分数加起来,得到你患某种病的遗传风险值。比如某个SNP对应冠心病的权重是0.003456789,你的基因型是1,那这一项的得分就是0.003456789×1。
过去大家觉得这种汇总数据很安全,就像只告诉你“全班平均分是85”,你不可能反推出每个同学的分数。但哥伦比亚大学的研究发现,这个类比错了。
真实的风险评分计算里,每个SNP的权重精度极高——能精确到小数点后16位。这就像每个同学的分数都被乘以了一个独一无二的、精确到分的系数,最后加起来得到总分。当参与计算的SNP数量不多(比如50个以内)时,反向推导的难度会骤降。
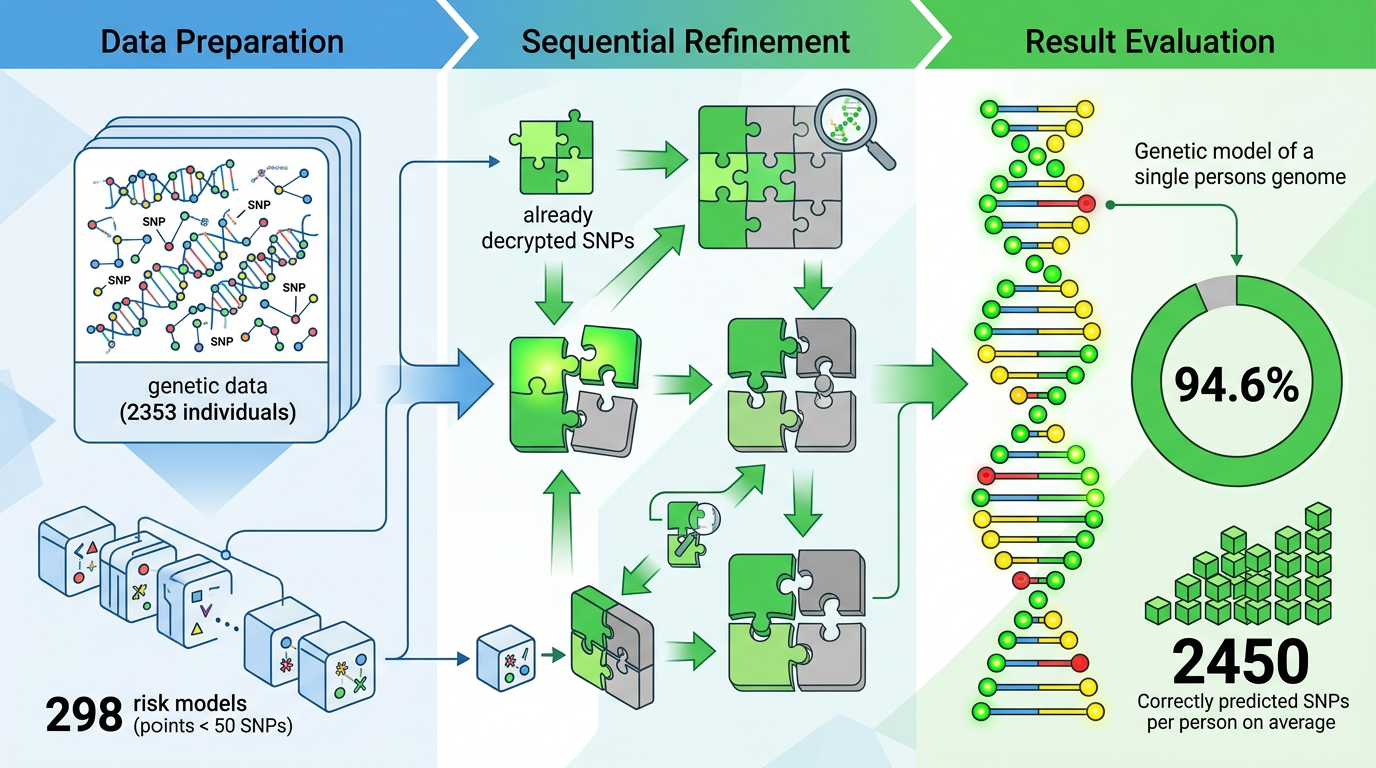
研究团队用298个包含50个以下SNP的风险模型,对2353人的基因数据做了测试。他们先从最小的模型入手,像拼拼图一样,用已经破解的SNP信息缩小更大模型的解空间,最后平均能以94.6%的准确率还原一个人的基因型——平均每人能猜对2450个SNP位点。
这种反向破解本质上是个数学问题——经典的“子集和问题”:给你一个目标数(风险评分),再给你一组带权重的数字(SNP位点和对应权重),找出哪组数字的加权和等于目标数。这本来是个计算量极大的难题,但风险评分的两个特性让它变得可行:
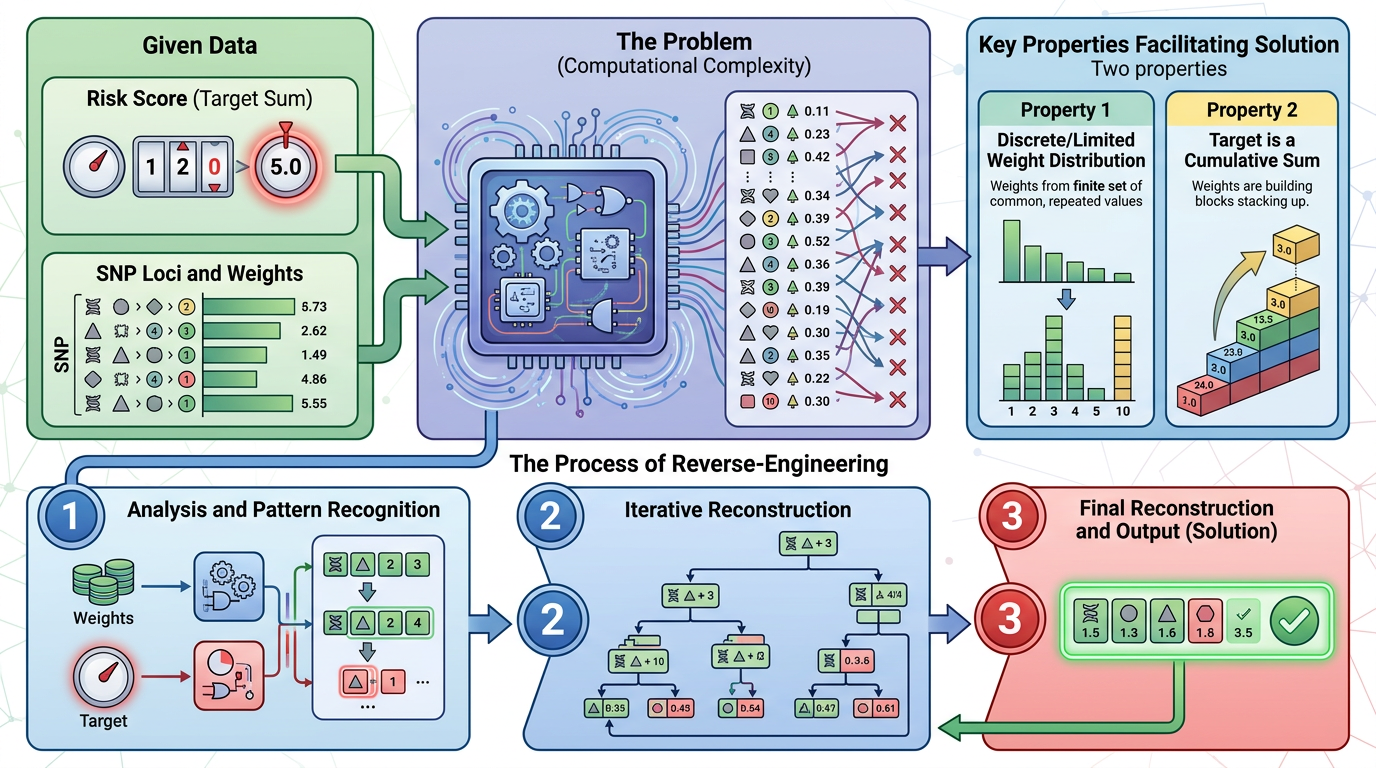
第一,权重精度足够高。每个权重的16位小数相当于给每个SNP位点做了独一无二的“标记”,不同SNP的加权值几乎不可能重复,大大缩小了可能的组合数量。 第二,群体遗传数据可以帮着“作弊”。攻击者可以用公开的族群基因频率数据,把那些概率极低的基因型组合直接排除——比如某个SNP在东亚人群里的出现概率只有0.1%,那它就不太可能出现在你的基因型里。
更值得警惕的是,非欧洲裔人群的隐私风险更高。因为目前绝大多数基因研究数据都来自欧洲人,非欧洲裔人群的基因频率数据差异更大,反而更容易被精准定位。研究显示,非洲裔和东亚裔人群被识别的概率比欧洲裔高得多——这相当于在本就存在健康数据鸿沟的基础上,又添了一道隐私鸿沟。
我认为,这是当前基因研究领域最容易被忽略的公平性问题:当我们在谈论基因技术的进步时,少数族群不仅没享受到同等的技术红利,反而要承担更高的隐私风险。
既然风险评分的隐私漏洞已经被发现,有没有办法补上?研究团队提出了一个简单又有效的办法:降低权重的精度。
比如把原来16位小数的权重四舍五入到3位,这样攻击者反向推导的难度会呈指数级上升,但对风险评分的预测准确性几乎没有影响——研究显示,精度降低后,风险评分的预测能力只下降了不到1%。
除此之外,还有一些更技术化的防护手段:比如用同态加密技术,让计算在加密状态下完成,全程不暴露原始基因数据;或者用联邦学习,让多个机构在不共享数据的情况下联合训练模型。但这些技术目前要么计算成本太高,要么还在实验室阶段,离大规模应用还有距离。
更现实的问题是,现在公开数据库里已经有447个存在漏洞的风险模型。这些模型就像没上锁的抽屉,任何人都可以伸手去拿里面的隐私。研究团队的建议是:不要再公开发布高精度的风险模型权重,同时在研究设计阶段就把隐私保护考虑进去——尤其是涉及少数族群时。
我们总以为,把复杂的基因数据简化成一个数字,就能兼顾便利和隐私。但这次的研究提醒我们:在基因技术面前,没有绝对的“安全简化版”。每一个汇总数据的背后,都可能藏着一个能被还原的个体。
基因数据的特殊性在于,它不仅属于你自己,还属于你的家人、你的族群。它不像银行密码,可以随时修改;也不像普通的个人信息,泄露了可以补救。一旦泄露,就是终身的、甚至代际的风险。
“越简化的基因数据,可能藏着越不简单的隐私陷阱。” 当我们拥抱基因技术带来的便利时,别忘了给它加上一把足够坚固的隐私锁——这不仅是为了保护自己,也是为了不让技术的进步,变成少数人的“隐私收割机”。