对抗知识焦虑,从看懂这条开始
App 下载
AI帮人类画出了代谢的「精准地图」
数字孪生地图|花生四烯酸|人类基因组尺度代谢模型|查尔姆斯理工大学|清华大学|大语言模型|代谢内分泌疾病|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数字孪生地图|花生四烯酸|人类基因组尺度代谢模型|查尔姆斯理工大学|清华大学|大语言模型|代谢内分泌疾病|医学健康|人工智能
当你吃下一块蛋糕,糖分从口腔到肠道,再转化为肝脏里的糖原、血液中的葡萄糖,最后变成脂肪细胞里的储能物质——这一连串反应涉及上千种代谢物、数万个生化步骤,就像一座没有地图的迷宫。过去科学家靠手工拼接的「代谢地图」,总是漏画路径、标错出口,连花生四烯酸这种和炎症、过敏密切相关的代谢物,都没法说清它在男女老少体内的差异。直到清华大学和查尔姆斯理工大学的团队,让AI当起了「地图测绘师」,画出了迄今为止最精准的人类代谢全景图。这张图到底厉害在哪?
你可以把人类基因组尺度代谢模型(GEM)理解为人体代谢的「数字孪生地图」——它把每个基因、每类蛋白质、每种代谢物都标在对应的位置,连它们之间的反应路径都用数学公式算得明明白白。过去的Human1模型,是靠整合多个旧版「草稿」拼出来的,里面藏着不少错误:比如把基因和反应的对应关系标错,或者为了填补空白凭空加了些不存在的路径。
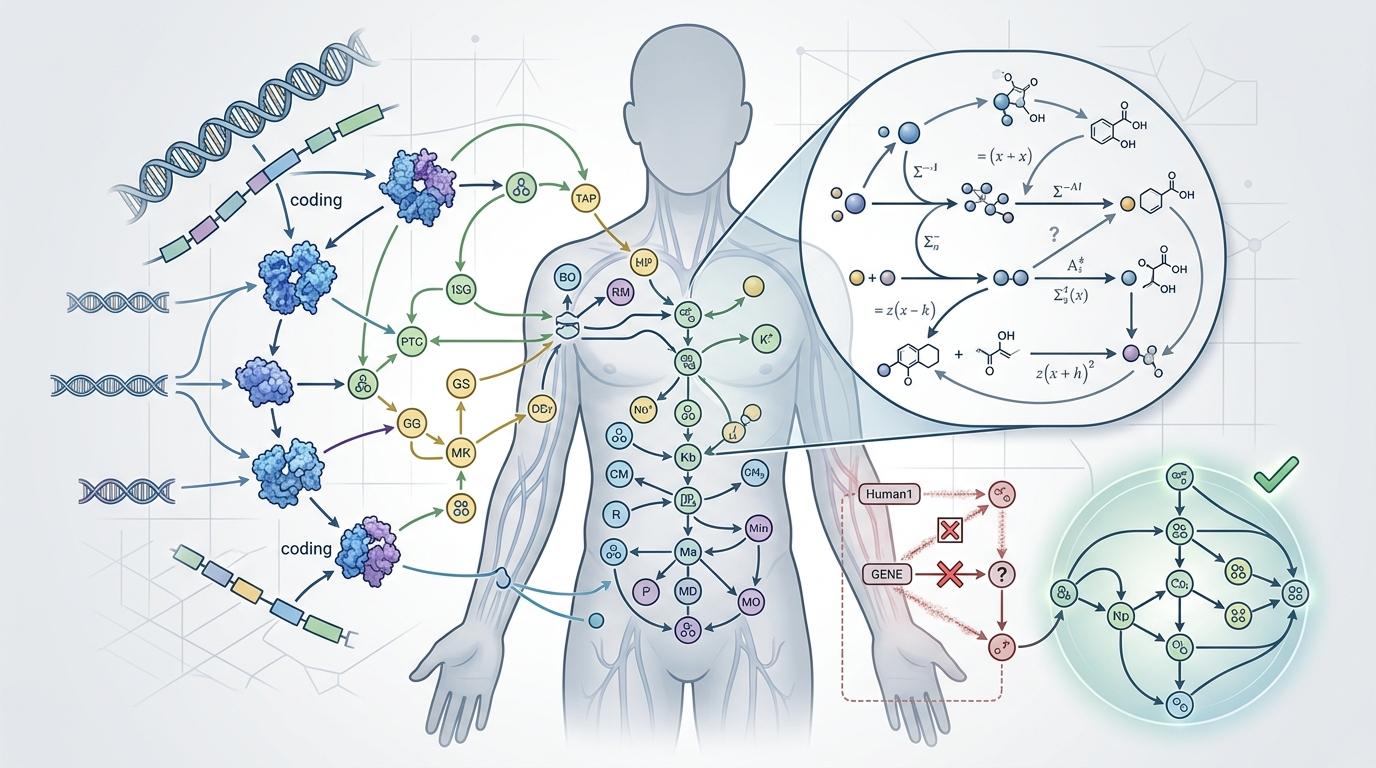
而新的Human2模型,第一次请来了大语言模型当「智能审校」。它能像资深生物学家一样,啃下PubMed里的上万篇文献,自动提取基因功能、代谢通路的最新发现,还能精准定位旧模型里的错误——比如把某个标注错的基因反应对直接修正,把那些凭空加的无效反应删掉。配合GitHub Actions的自动化检查,过去需要几个月人工审校的工作,现在几天就能完成。
更关键的是,Human2不再是一张「通用地图」。它能根据性别、年龄、器官,生成专属的「局部地图」——比如年轻人和老年人的花生四烯酸代谢路径,差异大到像两条完全不同的路;肝脏和肌肉的能量代谢模式,也被标分得清清楚楚。
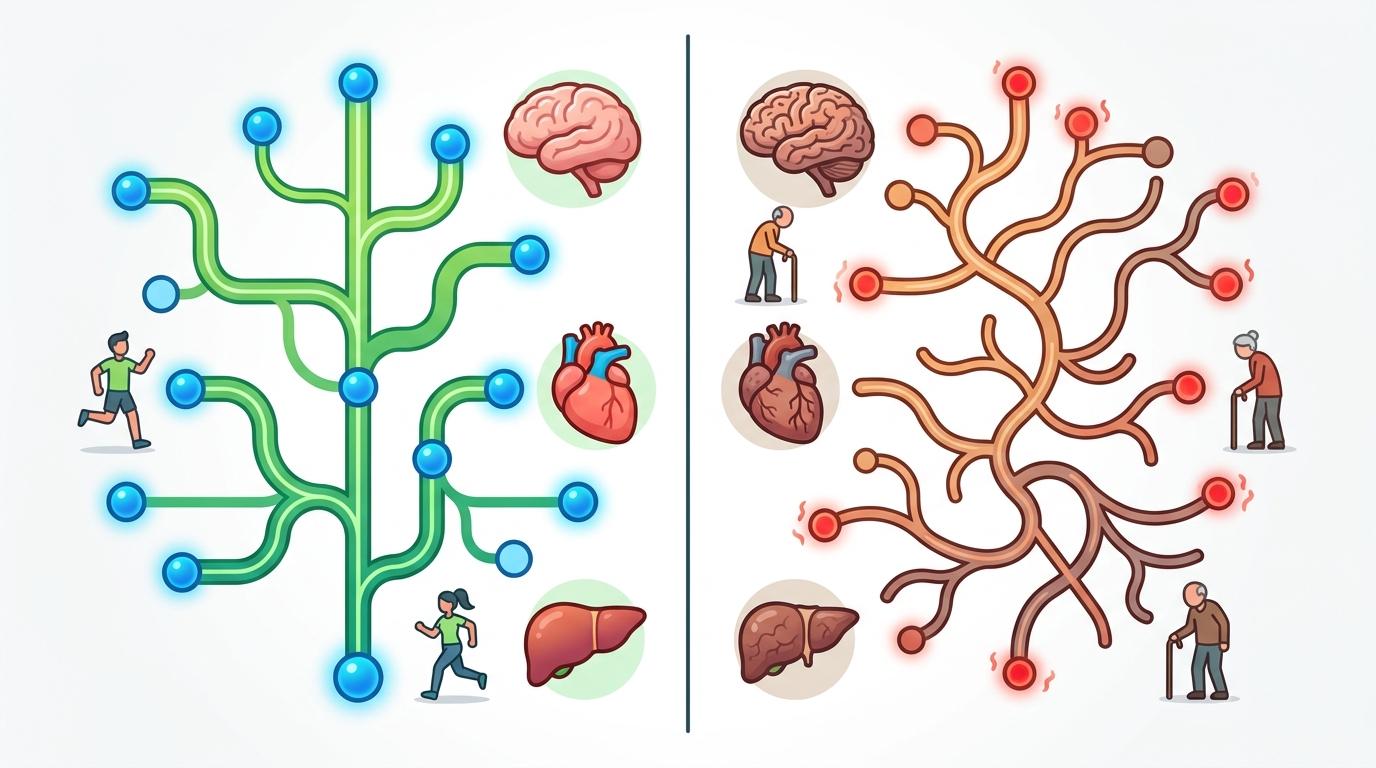
你可能好奇,大语言模型明明是处理文字的,怎么能看懂生物学术语?其实它的核心能力,是从海量文本里「找规律」——比如看到「花生四烯酸」和「白三烯」总是同时出现在炎症相关的文献里,就能自动把它们归到同一条代谢通路;看到某篇论文说「X基因调控Y反应」,就会把这个关联更新到模型里。
当然,AI也会犯错,比如把相似的代谢物搞混,或者编造出不存在的研究结论。所以团队给它加了两道「保险」:一是用GitHub Actions自动验证每个更新的生物学合理性,二是让人类专家做最终的审核。这种「AI挖信息+人类做判断」的模式,比纯手工效率提升了至少10倍,还能覆盖到过去人工没精力关注的冷门研究。
为了让地图「动起来」,团队还把GECKO 3.0的动力学约束加了进去——就像给地图里的每条路设了限速,反应快慢不再是随便猜的,而是根据酶的催化效率、蛋白质的含量算出来的。这样一来,模型就能模拟从进食到禁食的24小时里,肝脏把葡萄糖变成糖原、脂肪细胞储存能量的动态过程,甚至能算出器官之间交换的代谢物有多少。
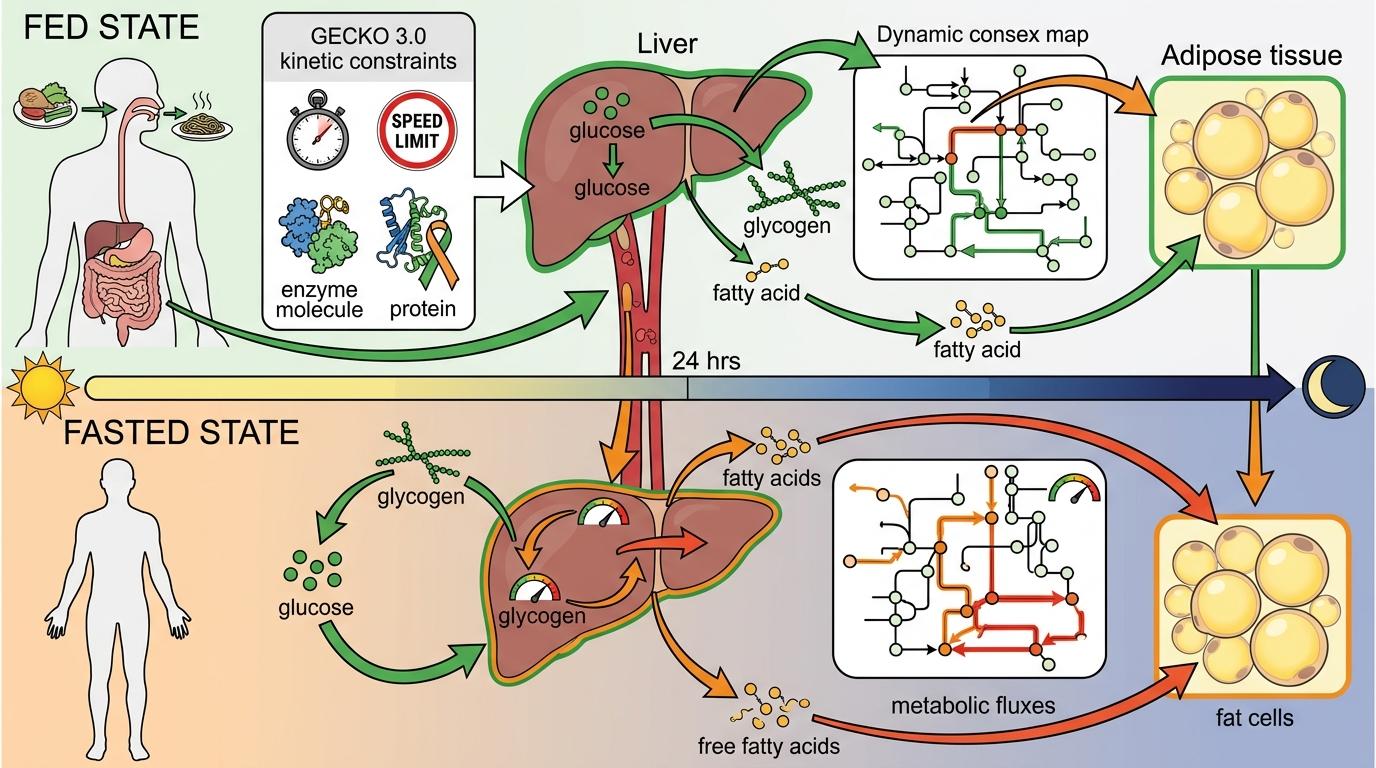
Human2确实厉害,但它也不是完美的。比如它依赖的多组学数据,还没法覆盖所有人群——比如某些罕见病患者、特定种族的代谢特征,还没被纳入模型;AI提取信息时,也可能漏掉那些没被高频引用的小众研究。而且它的动态模拟,还只能覆盖进食、禁食这种相对简单的状态,像运动、感染这种复杂场景下的代谢变化,还需要更多数据支撑。
但它的价值,已经足够改变很多事。比如在药物研发里,过去科学家要靠动物实验测试药物对代谢的影响,现在可以先在Human2的器官模型里模拟——看看药物会不会干扰肝脏的解毒通路,会不会影响心脏的能量供应,能提前筛掉很多有潜在副作用的候选药物。在精准医疗里,医生可以根据患者的代谢模型,定制最适合他的饮食和治疗方案——比如同样是糖尿病患者,有的要控糖,有的要调脂,模型能给出更精准的建议。
甚至在公共卫生领域,它能模拟不同年龄层的代谢差异,帮营养学家制定更合理的膳食指南——比如老年人需要更多的某种氨基酸,来维持肌肉的代谢活性,这些都能从模型里找到依据。
当我们把人体代谢拆解成一个个数据点、一条条反应路径时,很容易忘记它背后是一个个活生生的人——是那个吃了蛋糕就犯困的上班族,是那个年纪大了就容易血脂高的老人,是那个对花生过敏的孩子。Human2的意义,从来不是画出一张完美的数字地图,而是让我们离「读懂每个个体的代谢」更近了一步。
数字地图再精准,也替代不了对生命的敬畏。 未来的代谢研究,会是AI的计算能力和人类的生物学智慧更深度的结合——我们用AI处理海量数据,用人类的直觉和经验,去理解那些数据背后的生命故事。