对抗知识焦虑,从看懂这条开始
App 下载
AI告别参数竞赛,产业验收时代已至
真实场景应用|ROI|制造企业|全域AI试验场|北京亦庄|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载真实场景应用|ROI|制造企业|全域AI试验场|北京亦庄|AI产业应用|人工智能
当技术方的PPT不再堆参数、算力榜单,而是开始蹲在需求方桌边算ROI;当企业老板不再问“你们模型有多强”,而是直接甩来“仓库缺货率降30%要多少钱”——2026年的AI行业,终于从实验室的云端,踩进了产业的泥地里。北京亦庄的一场对接会上,技术方被两家制造企业围着抢方案的场景,像一根针,刺破了过去两年AI行业的泡沫:现在,能解决真问题的AI,才配谈价值。
你可以把北京亦庄的“全域AI试验场”,理解成一个没有围墙的AI“新兵训练营”——不再是在实验室里给AI喂干净的标注数据,而是直接把它扔进制造车间的油污、医院急诊的嘈杂、物流仓库的混乱里。这里有24个大项、88个细分场景的真实需求:从汽车零部件的AI质检,到政务审批的数字员工,每一个需求都带着具体的预算、明确的KPI,甚至还有“搞不定就扣钱”的硬约束。
和传统的AI试点不同,这个试验场的核心是“全域开放”——政府不搞定向扶持,而是把所有场景摊开,让技术方和需求方直接对接。就像那次对接会上,一家做AI视觉检测的团队,刚坐下10分钟就被两家餐饮连锁企业围住:一家要解决后厨餐具的自动消毒检测,另一家要监控食材的新鲜度。没有虚头巴脑的“技术交流”,开口就是“能做到99.9%准确率吗?多少钱?多久能上线?”
这种模式的本质,是把AI的“验收权”还给了产业。过去AI行业的话语权在技术团队手里,比的是模型参数、跑分;现在,话语权转到了需求方手里,比的是能不能解决真问题、能不能算清投入产出比。

很多人以为AI落地难在技术,但从亦庄的实践看,真正的坎在技术之外。
第一关是“数据关”。不是缺数据,是缺“能用的数据”。制造车间里的传感器数据,可能一半是噪音;医院的病历数据,格式五花八门还涉及隐私。一家做AI预测性维护的团队就遇到过:企业提供的设备运行数据,连时间戳都不统一,模型训练到一半就卡壳。要把这些“脏数据”洗干净,成本可能比训练模型还高。
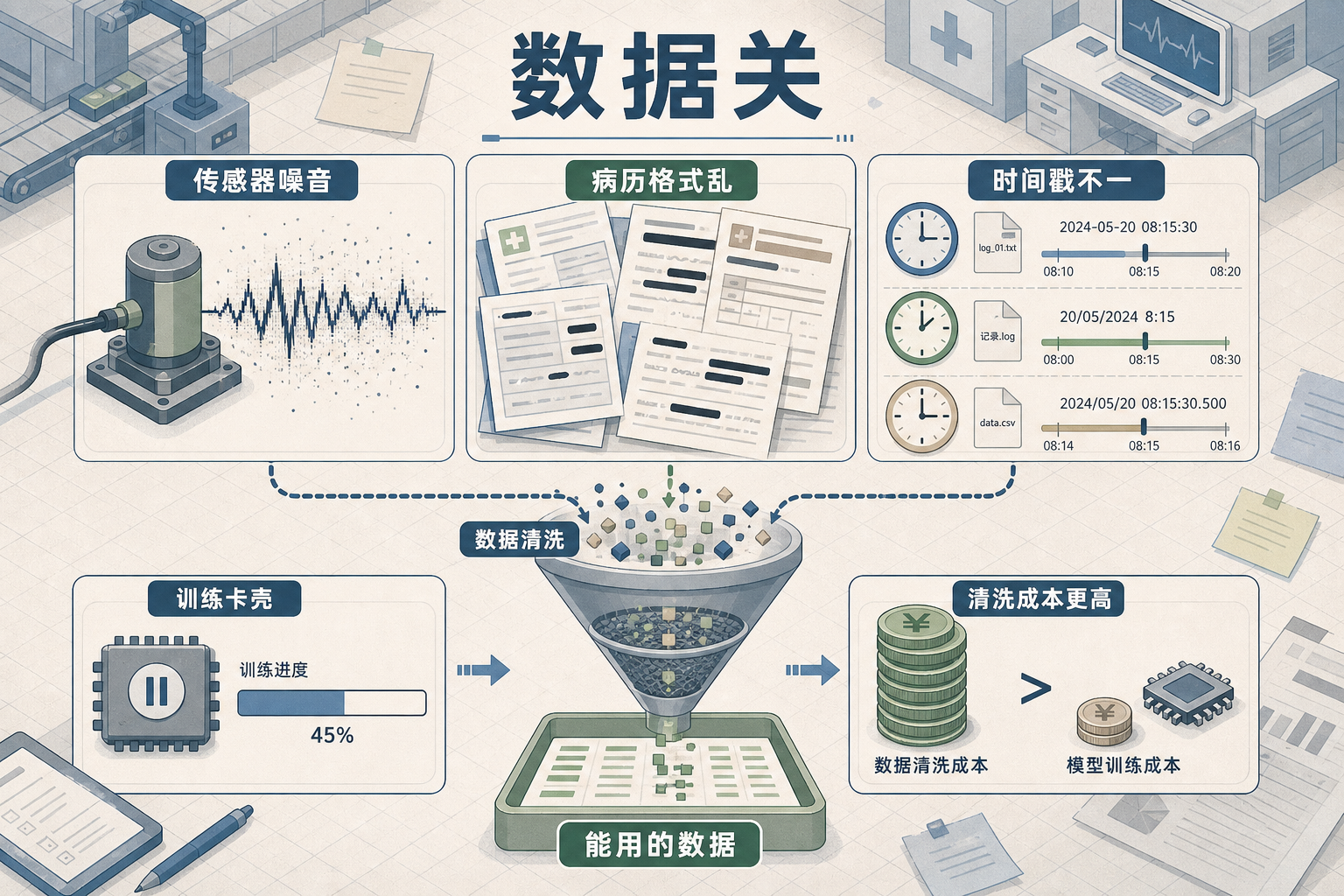
第二关是“组织关”。AI不是装个软件就行,它要动企业的流程、甚至动员工的饭碗。一家物流企业引入AI路径优化系统后,老司机集体抵触——他们靠经验攒下的“最优路线”,被AI否定了。最后企业只能搞“双轨制”:AI算的路线供参考,老司机的经验也保留,花了半年才让大家接受AI是“助手”不是“对手”。
第三关是“信任关”。AI的“黑箱”特性,让很多企业不敢用。比如AI诊断的疾病,医生不敢直接采信;AI算的金融风险,银行不敢直接放贷。一家做AI法律文书的团队,花了一年时间优化模型的可解释性,每一条AI生成的合同条款,都要附上对应的法条依据,才终于拿到了律所的订单。
这些坎,没有一个是靠技术突破能直接解决的,它需要企业、技术方、甚至政府一起磨合,像拼拼图一样,一点点把AI嵌进产业的肌理里。
当AI真的走进产业,人和机器的关系也在悄悄变化。过去大家怕AI抢饭碗,但亦庄的案例里,更多的是AI把人从重复劳动里解放出来,去做更有价值的事。
比如京东的数字人直播,让中小商家不用再花高薪请主播,24小时直播带货,而原来的主播,转去做内容策划、用户运营——这些是AI做不好的。顺丰的AI Agent把路径规划从分钟级降到毫秒级,快递员不用再花时间算路线,能多送几单货,收入反而涨了。
这里的核心是“人机共生”:AI擅长处理数据、重复劳动,人擅长创意、沟通、决策。一家制造企业用AI做质检后,原来的质检工人,转去做AI模型的标注和优化,工资涨了20%,工作也更轻松了。
当然,这种转变也需要企业调整组织架构、员工提升技能。亦庄的试验场里,很多企业都和高校合作开了AI培训班,教员工怎么用AI工具、怎么和AI协作。未来的工作,不再是“人 vs 机器”,而是“人 + 机器”。
当技术的泡沫褪去,AI终于露出了它本来的样子:不是颠覆一切的“黑科技”,而是像电、互联网一样的基础设施。它不会凭空创造奇迹,但能给每个愿意拥抱它的产业,带来效率的提升、成本的降低。
亦庄的对接会散场时,需求墙上的纸条还在增加,技术方的名片也被抢空了。这场没有宏大叙事的会议,其实是一个信号:AI的“验收时代”已经来了,能通过产业真实场景检验的AI,才能真正落地生根。
技术的价值,从来不在实验室里,而在解决真问题的现场。