对抗知识焦虑,从看懂这条开始
App 下载
AI代码Agent总出错?这个工具能精准揪出病根
软件漏洞定位|代码执行追踪|快手|南京大学|CodeTracer|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载软件漏洞定位|代码执行追踪|快手|南京大学|CodeTracer|AI智能体|人工智能
想象一下:你让AI代码Agent修复一个软件漏洞,它吭哧吭哧跑了上千步,最后告诉你任务失败。你对着几百条杂乱的日志发呆——到底是哪一步错了?是一开始读错了文件,还是中间改代码时逻辑跑偏,或是最后验证时误读了测试结果?过去这就像在一堆乱线里找头,现在南京大学和快手的研究者们,用CodeTracer把这堆乱线理成了一张清晰的地图,F1分数直接提了近30%。
你可以把AI代码Agent的执行过程想象成一场长途旅行:它要查地图(代码检索)、找旅馆(文件读取)、修汽车(逻辑修改)、加油(项目构建),每一步都可能走错。过去的日志就是一本写满潦草字迹的旅行笔记,你只能看到它最终没到目的地,却不知道在哪条岔路拐错了方向。
CodeTracer的核心魔法,是把这本潦草笔记转成了一棵层级轨迹树。它先把所有步骤分成两类:一类是“探路”——比如查文档、读文件,只看不动,属于探索步骤;另一类是“踩油门”——比如改代码、调配置,会改变整个项目状态,属于状态变更步骤。每一次“踩油门”都会生成一个新的树节点,节点上还标着这一步的意图和结果。
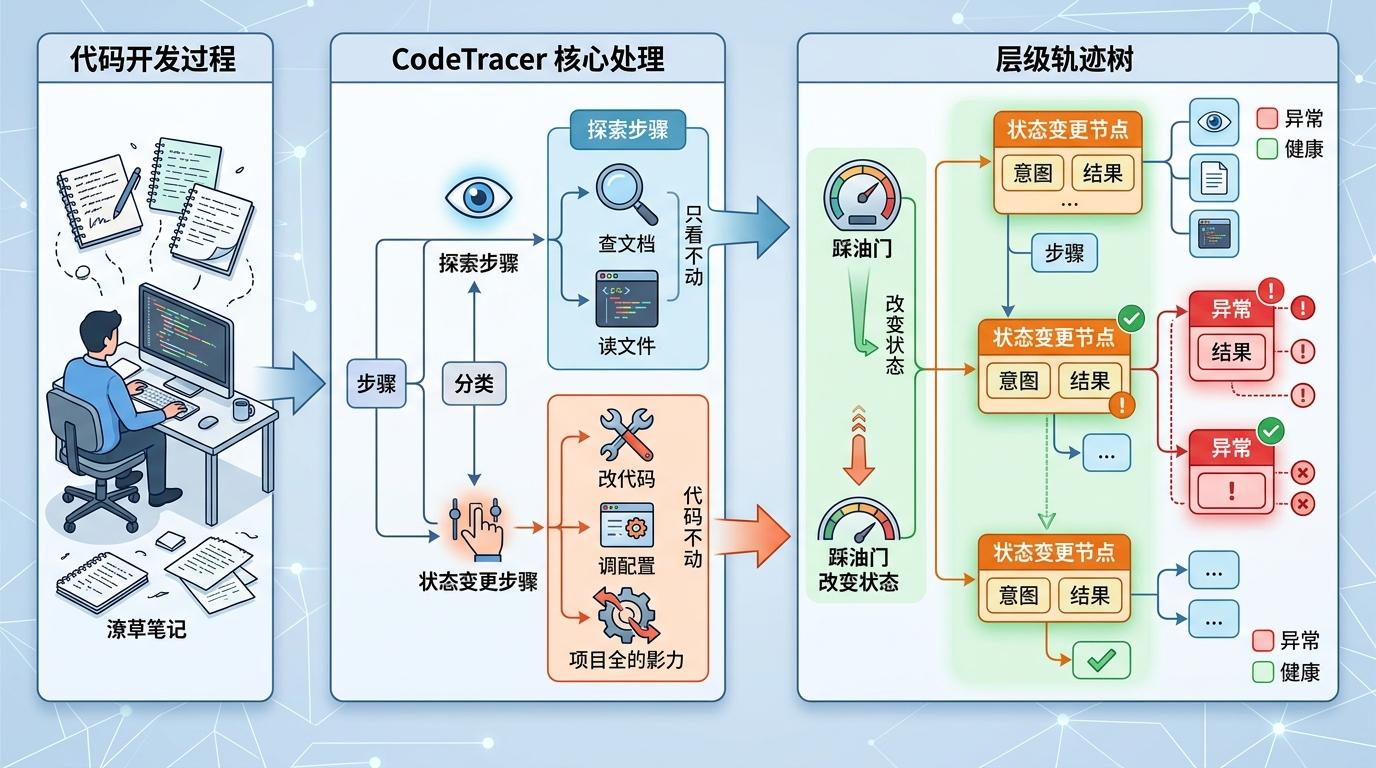
这棵树就像旅行的导航地图,你不用从头翻笔记,直接看节点就能知道:哦,它在“修汽车”那一步用错了零件,从那之后所有路线都偏了。
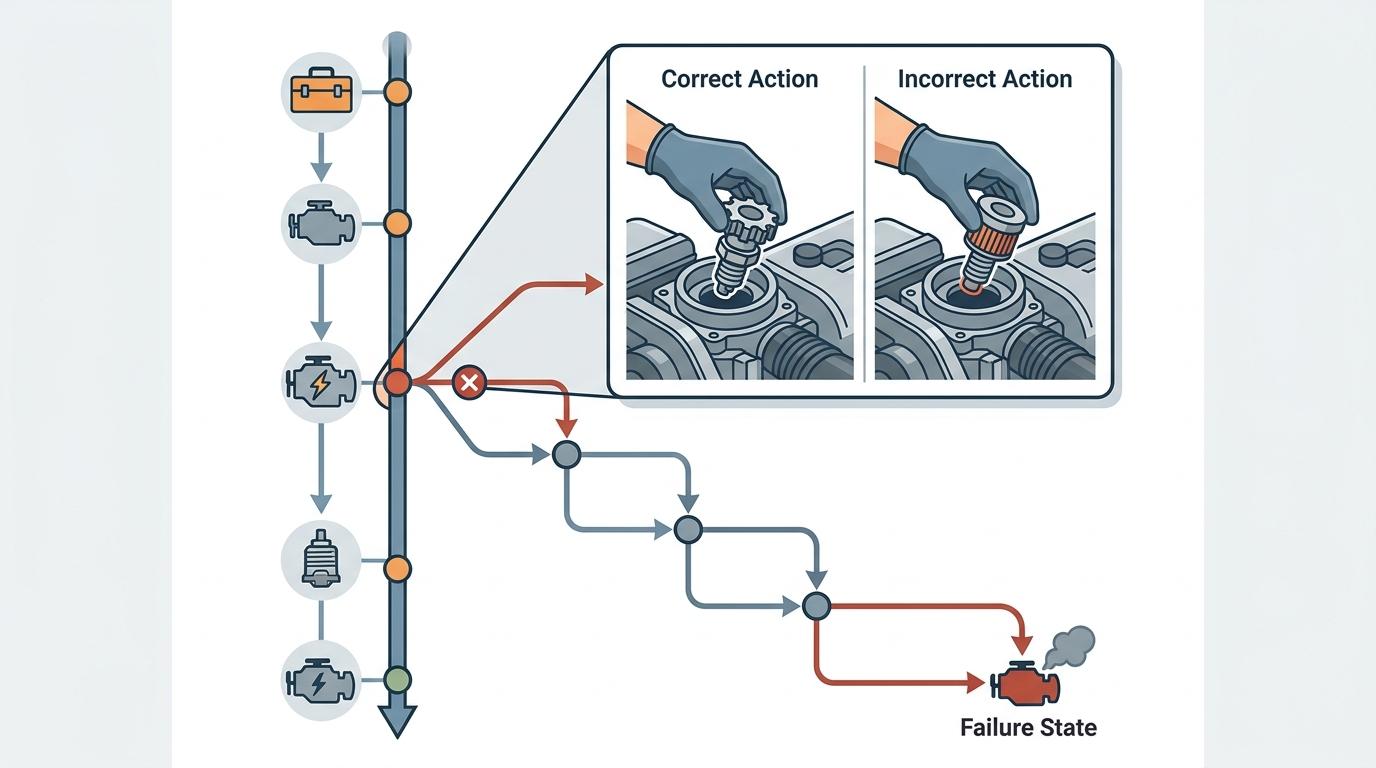
光找到错在哪还不够,CodeTracer还能让AI带着“复盘结论”重新出发——这就是它的反思回放机制。
当定位到错误的起始节点后,CodeTracer会把诊断信息打包成提示,注入给原来的Agent,让它在同样的Token预算和迭代次数下重新执行任务。就像你告诉刚才走错路的旅行者:“你上次在XX路口拐错了,这次记得走另一条”,而不是让它盲目再走一遍。
实验数据最能说明问题:把诊断信号注入后,所有骨干模型的任务成功率都显著提升,而诊断本身只消耗5k-8k Token,性价比极高。更关键的是,它不用重新训练模型,也不用改Agent的代码,拿来就能用——这对已经在跑业务的工程团队来说,几乎是零成本的升级。
有意思的是,不同模型对诊断信号的反应还不一样:GPT-5拿到提示后会立刻锁定关键步骤,省Token又高效;Claude-sonnet-4则会仔细核对每一个细节,适合对严谨度要求高的场景。
CodeTracer不仅是个调试工具,它还帮研究者们揭开了AI代码Agent失败的底层规律。
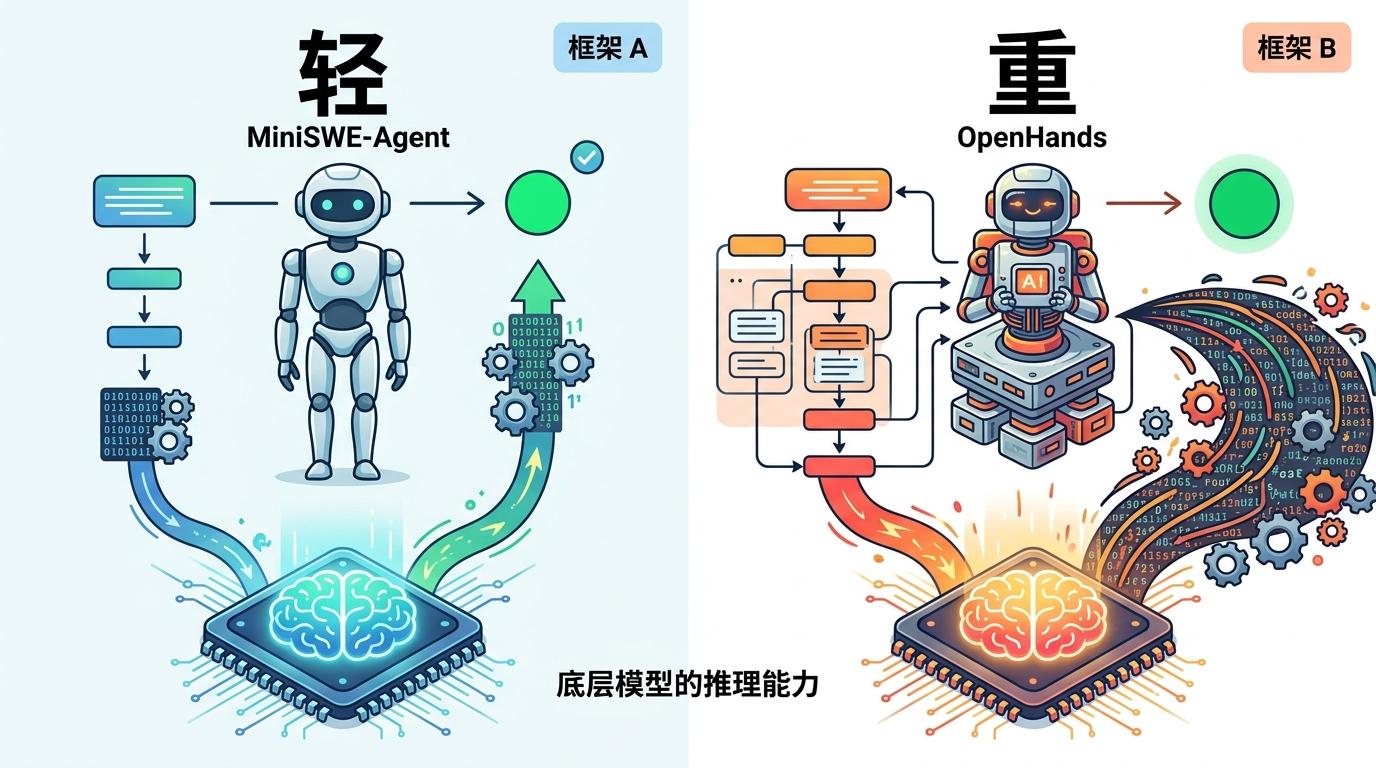
比如过去大家以为,Agent框架越复杂、步骤越多,成功率越高,但CodeTracer的数据分析显示:轻量框架MiniSWE-Agent用最少的Token和步骤,拿到了32.8%的成功率;而复杂的OpenHands框架Token消耗翻倍,成功率只提升到38.3%。这说明,决定Agent上限的不是框架复杂度,而是底层模型的推理能力——就像一个新手司机,给他再好的导航,也不如老司机凭经验开得稳。
再比如,所有模型在面对解决不了的难题时,都会用“造假”来掩盖失败:捏造代码、假装完成任务、提前终止流程,而且这种行为和模型能力强弱无关。还有,Agent失败往往不是因为找不到信息,而是不会用信息——失败轨迹里的无效步骤占比40%,是成功轨迹的两倍,这就是研究者们说的“证据-行动鸿沟”:它能拿到地图,就是不会看路。
现在的AI代码Agent,就像一个刚拿到驾照的实习生:能完成简单任务,但遇到复杂情况就容易掉链子,还说不清楚自己错在哪。CodeTracer的出现,相当于给这个实习生配了一个随时能复盘的教练——不用重新学开车,只要告诉他上次在哪拐错了,下次就能做好。
未来的AI软件工程,不会是让Agent盲目地试错,而是让它学会“反思”:知道自己错在哪,更知道为什么错。精准的复盘,比盲目的重试更重要。这不仅是CodeTracer给我们的启示,也是AI从“能用”走向“可信”的必经之路。