对抗知识焦虑,从看懂这条开始
App 下载
AI算力卡脖子的破局者,藏在一根硅针里
中国企业|内存墙|3D堆叠工艺|HBM内存|硅通孔TSV|先进材料|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载中国企业|内存墙|3D堆叠工艺|HBM内存|硅通孔TSV|先进材料|AI算力|前沿科技|人工智能
当你用AI生成一张4K图片、和大模型聊完一段复杂代码时,你可能没意识到:此刻有几十亿个数据正以每秒数万亿次的速度,在GPU和内存之间疯狂穿梭。过去三年,AI模型参数从百亿跃升至万亿,但传统内存的带宽增速,却只跟上了算力的1/5——这就是困住AI的「内存墙」。直到一种叫HBM的3D堆叠内存出现,而它的核心,是一根直径仅3微米的硅通孔TSV。最近,一家中国企业宣布突破了TSV工艺的关键材料,这意味着AI算力的天花板,正被一根细针悄悄捅破。
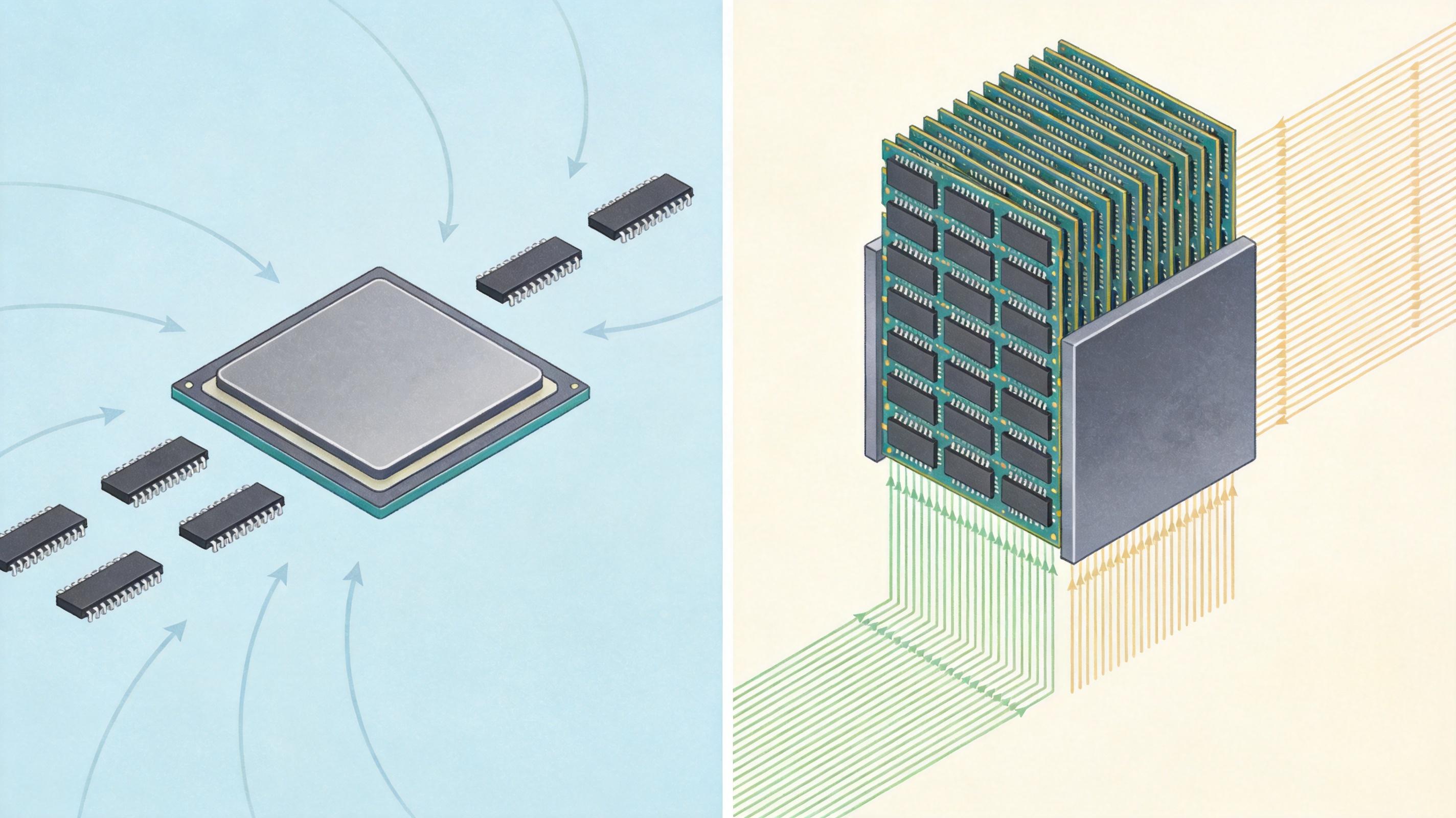
你可以把传统内存想象成一排紧挨着CPU的书架:CPU要数据,就得一本本从书架上取,再一本本放回去,速度再快也架不住书架和书桌的距离。而HBM,是把几十层DRAM芯片像叠蛋糕一样堆起来,再用成千上万根TSV——也就是比头发丝细20倍的硅制「针管」——把每一层芯片直接连起来,同时连到GPU上。
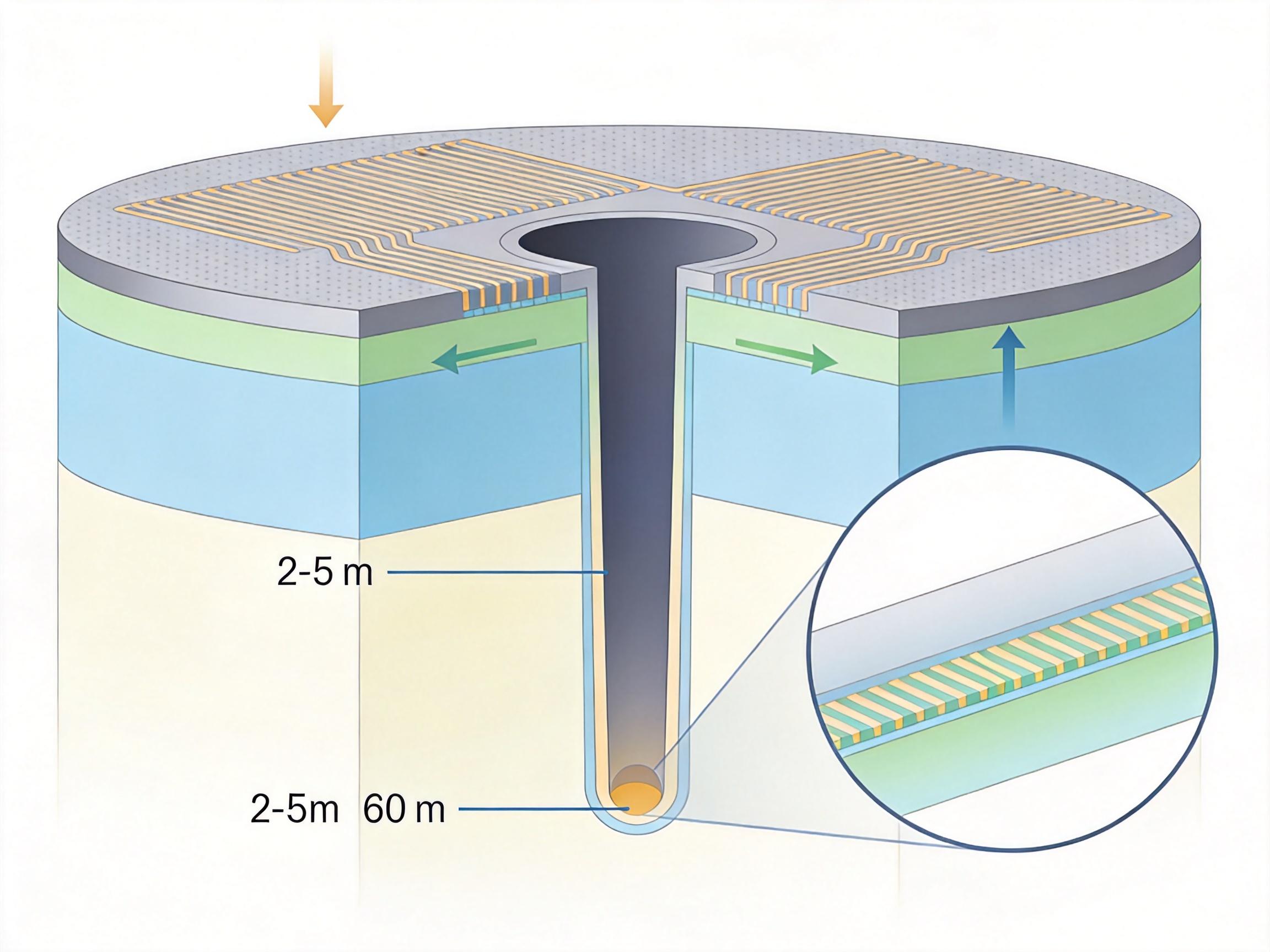
这不是简单的堆叠。TSV的直径要控制在2-5微米,深度却要达到60微米,相当于在一张A4纸上钻一根穿过100张纸的细孔,还得保证每根孔壁光滑、没有毛刺,否则数据传输就会出错。华特气体提供的刻蚀气体,就是用来精准「钻」这些细孔的关键:它能在硅片上烧出垂直的深孔,同时在孔壁形成一层保护膜,避免孔口坍塌。
更关键的是,这些硅针让HBM的总线宽度达到了1024位,是传统DDR内存的16倍。NVIDIA H100 GPU搭配的HBM3,单卡带宽能到3.35TB/s——相当于每秒传输800部高清电影。这直接解决了AI训练时,GPU因为等数据而「摸鱼」的问题,算力利用率能从原来的30%提升到80%以上。
很少有人知道,HBM的制造成本中,TSV工艺占了整整30%,而其中最影响良率的,就是刻蚀环节。如果刻蚀气体的纯度不够、配比不对,要么孔壁会有残留的硅渣,导致数据传输中断;要么孔口会出现「喇叭口」,后续填充铜时容易形成空洞——只要有一根TSV出问题,整层芯片就报废了。
华特气体的突破,在于优化了刻蚀气体的成分和配比。他们开发的含氢氟碳气体,能在Bosch刻蚀工艺中,一边刻蚀硅片,一边在孔壁形成均匀的聚合物保护膜,既保证了孔的垂直性,又减少了刻蚀速率不均匀的问题。有数据显示,使用这种气体后,TSV的刻蚀良率能提升15%以上,直接降低了HBM的制造成本。
但这并非终点。当前HBM4已经开始测试混合键合技术,也就是把芯片直接用铜原子粘在一起,不再需要TSV的「针管」。这对刻蚀气体的要求更高——需要更精准地控制刻蚀深度和表面平整度,否则键合时就会出现空洞。而华特气体已经在布局下一代刻蚀气体,为HBM4的量产做准备。
全球HBM市场目前被三星、SK海力士和美光三家垄断,他们占据了97%的产能。但很少有人注意到,HBM的供应链不止是芯片制造,材料、设备、封装等环节同样关键——而中国企业正在这些隐形战场上突破。
华特气体的刻蚀气体,已经进入了韩国、新加坡等海外半导体厂商的供应链,成为HBM制造中不可或缺的一环。除了材料,国内设备厂商如华海清科、纳微科技也在开发HBM专用的刻蚀、键合设备。长鑫存储预计2026年实现HBM3量产,虽然比国际巨头晚了3-4年,但已经打破了海外的技术封锁。
更值得关注的是,当前HBM的供应极度紧张,三星、SK海力士的产能已经排到了2027年。中国企业的突破,不仅能缓解国内AI产业的「内存焦虑」,更能在全球供应链中占据一席之地。但我们也必须清醒:高端刻蚀设备、混合键合技术等核心环节,我们还落后于国际水平,需要持续投入研发。
当我们谈论AI算力的突破时,我们往往盯着GPU的参数、模型的大小,却忽略了像TSV、刻蚀气体这样的「隐形基石」。这些藏在芯片深处的技术,才是决定AI能跑多快、走多远的关键。
「算力的突破,从来不是单点的爆发,而是链条的协同。」这句话或许能概括HBM带给我们的启示:从一根3微米的硅针,到一瓶看不见的气体,再到整个供应链的协同,每一个环节的突破,都在为AI的未来铺路。而中国企业在这些隐形战场的努力,正在让AI算力的天花板,变得越来越高。