对抗知识焦虑,从看懂这条开始
App 下载
手机超分快113倍还不糊,这届竞赛玩明白了
图像清晰化|单步扩散模型|移动端超分辨率|VIPSL团队|NTIRE 2026|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像清晰化|单步扩散模型|移动端超分辨率|VIPSL团队|NTIRE 2026|多模态视觉|人工智能
你有没有过这种经历:手机里存着一张模糊的旧照片,想放大看清细节,结果要么等半分钟出一张满是马赛克的图,要么干脆卡在加载界面?这不是你的手机太烂,而是「移动端超分辨率」一直是道无解的题——要让模糊照片变高清,得用复杂模型算半天;要快,就得牺牲画质,鱼和熊掌似乎永远不可兼得。但NTIRE 2026这场竞赛,直接把这道题的答案掀在了桌面上:VIPSL团队的方案,把基准模型的速度提了113倍,画质还没崩。这不是简单的「优化」,而是把过去十年的技术死胡同,凿出了一条新大路。
你可以把传统的超分模型想象成爬楼梯——要从模糊的低清图爬到高清图,得一步一步去噪、修复,每一步都要算半天,手机处理器根本扛不住。而这次竞赛里的「单步扩散模型」,直接把楼梯改成了电梯。
传统扩散模型要花几百步迭代去噪,就像你要擦干净一个满是泥点的盘子,得蘸水、打洗洁精、反复擦拭几十次。单步扩散模型则是直接把脏盘子放进洗碗机,一次操作就搞定。它跳过了中间所有的迭代步骤,用一个训练好的网络,直接把低清图映射成高清图。
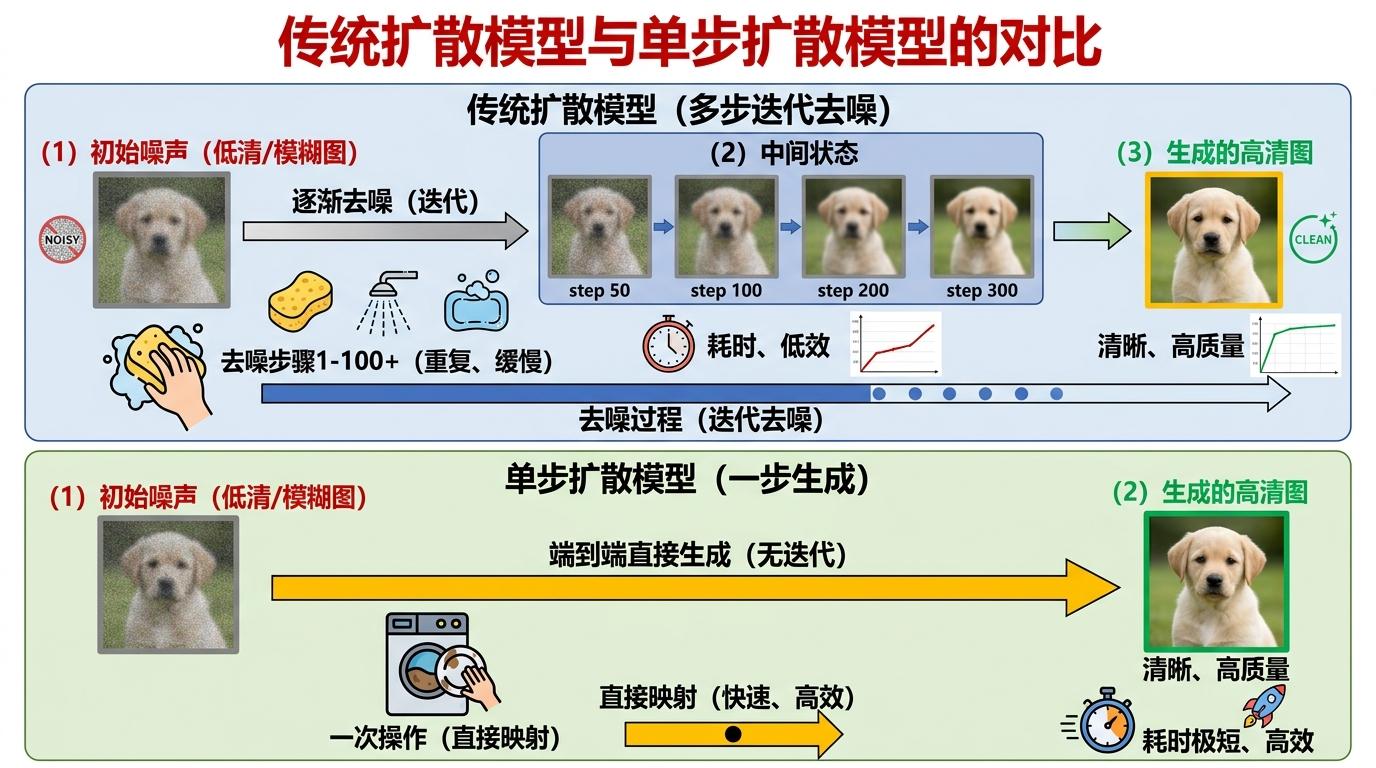
但真实的机制比洗碗机更精确:它不是凭空生成细节,而是通过学习海量图像的「纹理规律」,比如皮肤的毛孔、树叶的脉络,在低清图的基础上补全最合理的细节。TODSR团队还做了个更巧妙的优化:他们把低清图的特征和扩散模型的潜在空间做了「对齐」,就像给电梯精准定位到你所在的楼层,不用再一层层停靠,进一步提升了稳定性和速度。
如果说单步扩散是解决了「快」的问题,那「知识蒸馏」就是解决了「好」的问题。你可以把它想象成:一个教授(大模型)把自己几十年的知识,浓缩成一本薄讲义(小模型),让学生(移动端模型)不用读几百万字的专著,就能掌握核心内容。
三星AICamera团队的方案就是最好的例子:他们先用一个性能超强的大模型OSEDiff生成高清图,然后让一个轻量的小模型去「模仿」大模型的输出。这个小模型就像一个学徒,跟着教授一笔一划地学,最后画出来的画,和教授的几乎一模一样,但耗时只有几十分之一。
他们还加了个「细节增强模块」,就像学徒学完基础后,专门去练最容易出效果的细节——比如人物的睫毛、建筑的窗格。这样一来,小模型不仅快,还能保留大模型的细节质感。更关键的是,整个过程不需要大模型一直在场,学生学会了就可以独立干活,完美适配手机的有限算力。
这次竞赛里还有个有意思的趋势:越来越多的团队不再执着于「用哪种模型最好」,而是开始「混搭」。就像你做饭时,不会只用电饭锅或炒锅,而是根据食材选最合适的工具。
YuFans团队就把扩散模型和GAN模型的输出按7:3的比例融合——扩散模型擅长生成丰富的纹理,但偶尔会有伪影;GAN模型擅长保持结构稳定,但细节不够生动。把两者的输出像调鸡尾酒一样混合,再加上一点后处理的「调味」,最后出来的图既有扩散模型的细节,又有GAN模型的稳定。
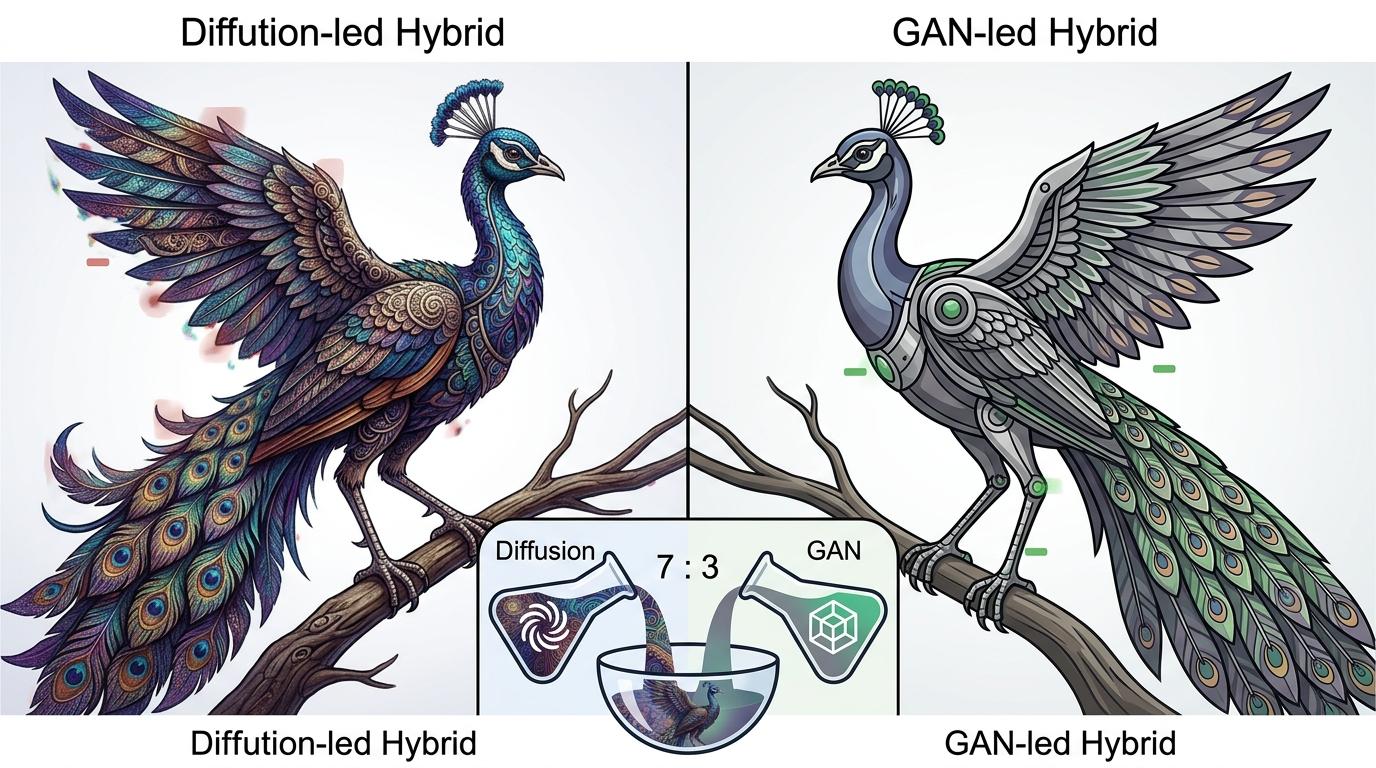
更聪明的是他们的训练方法:直接把竞赛用来评分的6种图像质量指标,当成了模型的「学习目标」。就像考试前老师直接把考点告诉你,你不用瞎猜重点,直接对着考点复习。这种「指哪打哪」的优化,让模型的得分直接拉满,也给未来的研究指了条明路:与其追求「完美的模型」,不如追求「最适合任务的模型组合」。
这场竞赛最让人兴奋的,不是113倍的速度提升,而是它打破了一个持续十年的偏见:移动端AI就只能是「低配版」。过去我们总觉得,要在手机上跑AI,就得牺牲性能、降低精度,但这次的冠军方案证明,只要找对了方法,鱼和熊掌可以兼得。
未来的手机拍照,可能再也不会有「糊片」的烦恼:你随手拍的一张夜景,手机能在瞬间把噪点去掉、把暗部细节拉满;你存了十年的旧照片,一键就能修复成4K高清。更重要的是,这种「算法+硬件」的协同优化思路,会从超分扩散到更多领域——比如实时翻译、AR特效、自动驾驶。
真正的高效,不是妥协,而是精准的适配。 当我们不再强求用大模型解决所有问题,而是学会让小模型「聪明地干活」,移动端AI的黄金时代才刚刚开始。