对抗知识焦虑,从看懂这条开始
App 下载
视觉模型不再只会做题,开始学着适应真实世界
CVPR 2026|康奈尔大学|视频编辑|真实世界适应|视觉模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载CVPR 2026|康奈尔大学|视频编辑|真实世界适应|视觉模型|多模态视觉|人工智能
当你用视频编辑软件抠人物时,是不是总遇到这种糟心场景:刚手动修正了被遮挡的手臂,下一秒镜头一转,模型又把背景当成了人物?过去十年,计算机视觉把「在实验室里把题做对」这件事做到了极致——模型越来越大,数据集越来越厚,基准测试的分数刷得越来越高。但这些「高分选手」一拿到真实世界的考卷,就会暴露致命缺陷:默认输入信息完整、任务目标固定、场景变化可预期。这个假设错了。现实世界里,视频会有遮挡,照片角度会乱飘,用户的需求会临时改变。而CVPR 2026的一批研究,正在把视觉模型从「考场优等生」,逼成「能在野地里生存的探险家」。
康奈尔大学的研究团队先撕开了旧范式的口子。过去的交互式视频分割,看起来是人机协作:用户点一下,模型改一下,但本质是「伪交互」——用户的修正只管用这一帧,下一次遇到同样的遮挡,模型还是会犯同样的错,因为它的内部参数是冻结的,根本没学会「记住」用户的反馈。
你可以把这种传统模型想象成一个只会背标准答案的学生,遇到新题型只会卡壳。而他们提出的LIT框架,相当于给模型装了个「随身错题本」——用轻量级的LoRA模块,在模型推理时实时吸收用户的修正反馈,局部更新参数。用户纠正一次,模型就会针对这个视频里的遮挡、光照变化形成短时适应,下次再遇到类似情况,就不会再错。
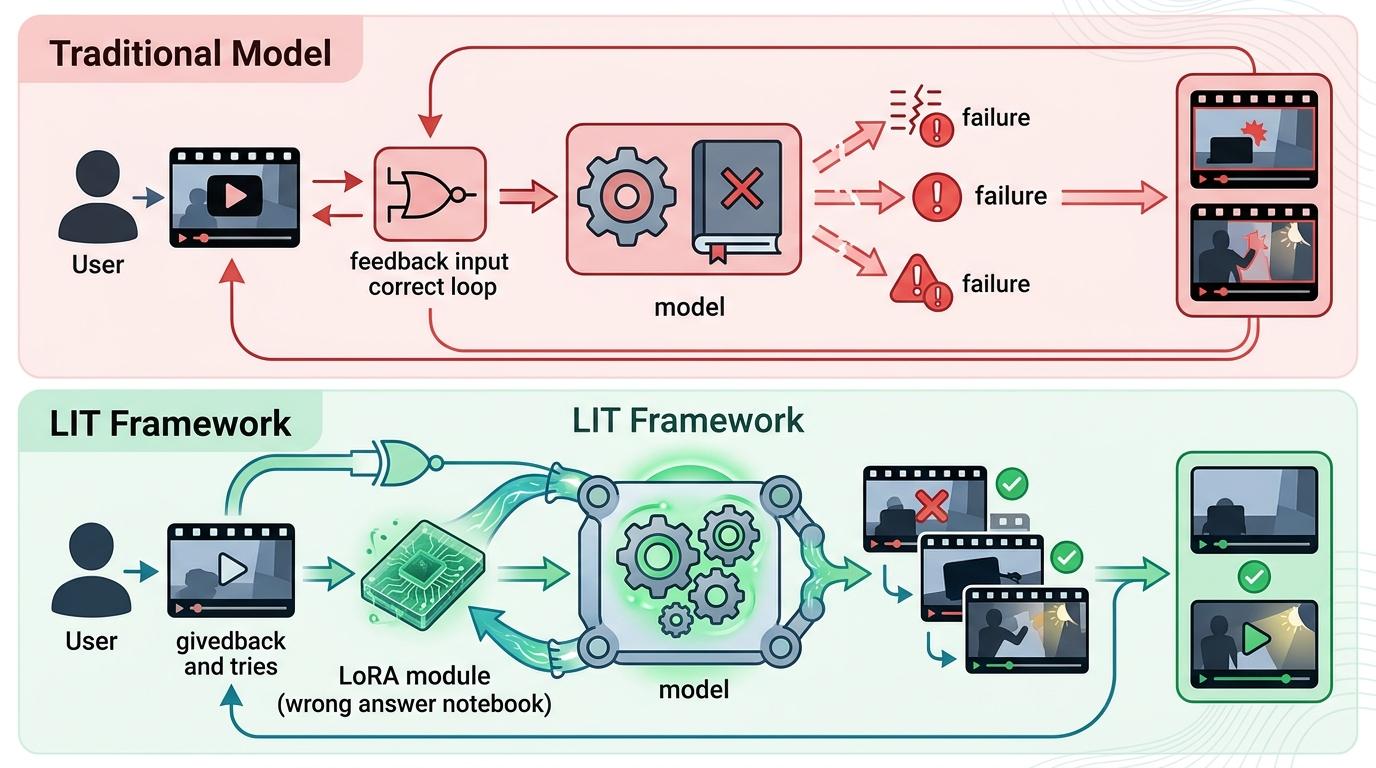
这不是简单的精度提升,而是打破了视觉模型几十年的边界:推理不再是参数冻结下的被动执行,模型第一次能在使用过程中「成长」。实验数据显示,它能减少18%-34%的用户纠正次数,把标注时间缩短20%以上,每次在线学习的开销仅0.5秒,远低于人工纠错的时间成本。
如果说LIT解决了「模型能在任务中学习」的问题,那么INSID3则走得更远——它证明模型甚至不用重新训练,仅凭上下文就能理解新任务。
过去的分割模型,要识别新物体必须先给它一堆标注数据微调,就像学新单词必须先背词典。但INSID3直接跳过了「查词典」的步骤:它基于自监督训练的DINOv3模型,这个模型在训练时看过海量无标注图像,已经把图像里的语义对应关系刻进了自己的特征里。研究团队发现,DINOv3的特征里藏着一个小bug:会受绝对位置干扰,比如两张图里同一位置的像素会被误判为相似。他们用「位置偏置消除」的方法把这个bug修好后,模型就能仅凭一张带标注的参考图,在另一张图里精准找到对应物体——不管是猫、狗,还是医学影像里的病变,甚至是物体的某个局部部件。
在测试中,它的分割精度比同类无训练方法高7.5%,参数却少了3倍。这意味着,视觉模型终于能像人类一样,看一眼示例就明白「我要找的是什么」,而不是必须先接受专门训练。
当模型能自己学习、自己理解任务后,下一个要突破的,是「信息不完整」的现实困境。
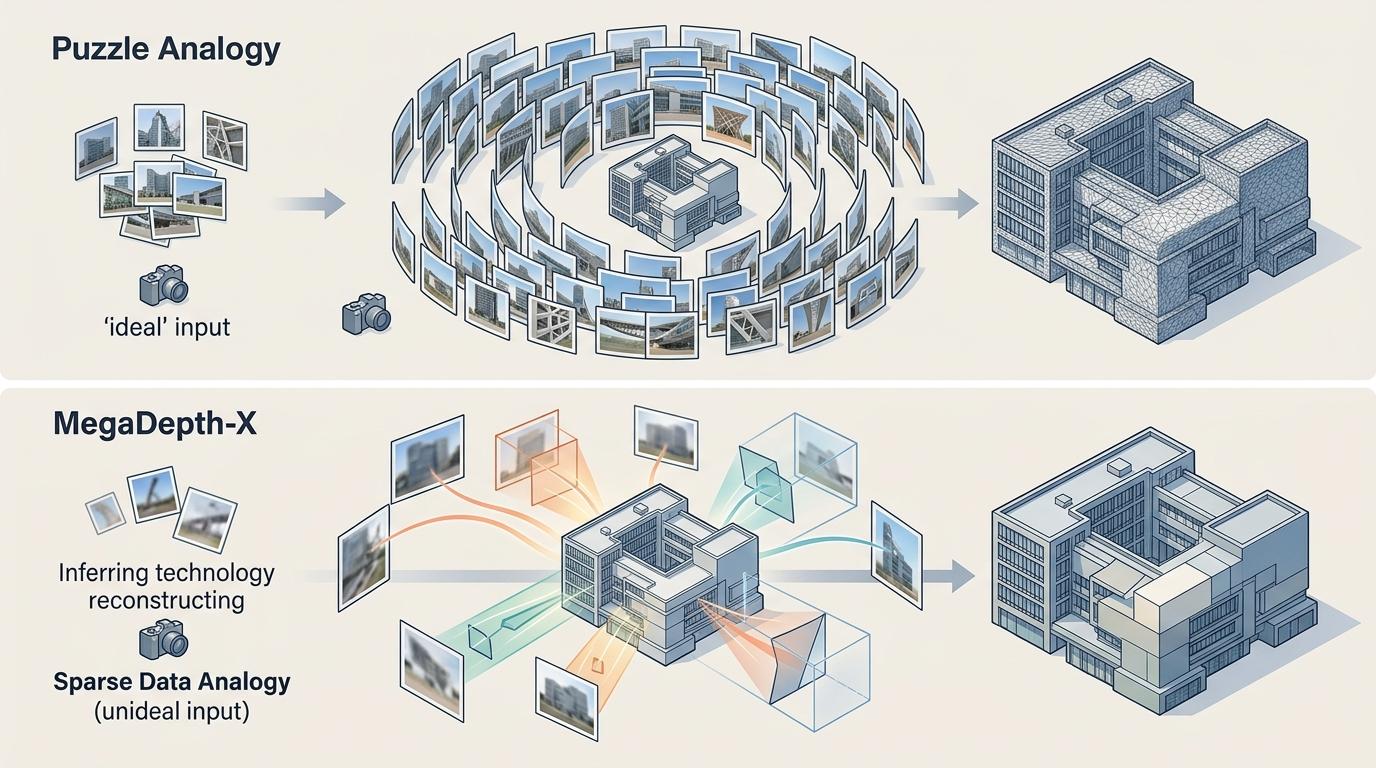
传统的三维重建模型,依赖的是角度统一、重叠度高的理想照片,就像拼拼图时所有碎片都在眼前。但真实世界里,我们能拿到的往往是用户随手拍的几张零散照片——角度歪、清晰度差、主体只露一小部分。康奈尔大学的MegaDepth-X数据集,专门模拟了这种「长尾场景」:故意用稀疏、低重叠的照片训练模型,逼它学会从碎片信息里推断完整结构。
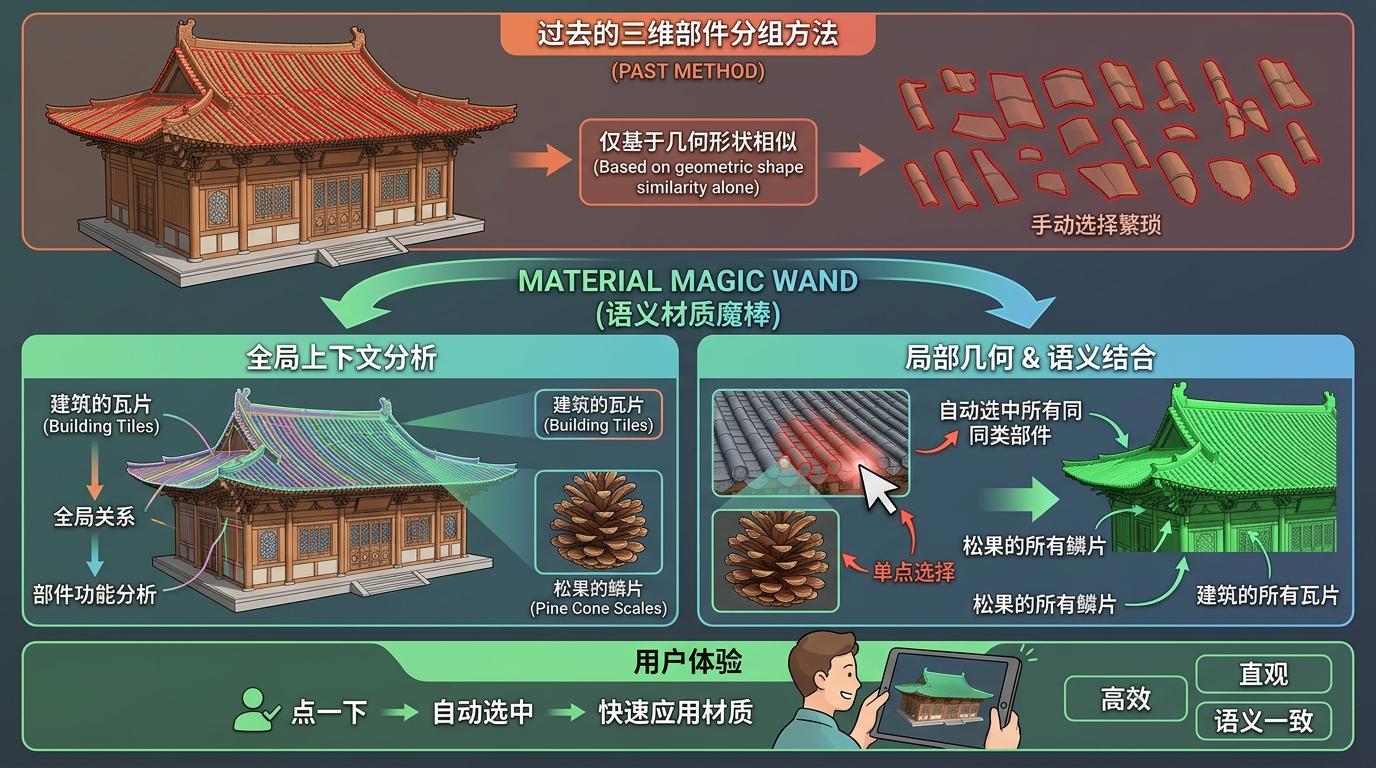
多伦多大学和Adobe的Material Magic Wand,则把这种「补全能力」延伸到了语义层面。过去的三维部件分组,只会找几何形状相似的部分,比如长得一样的窗户。但真实世界里,很多部件形状不同却该用同一种材质——比如松果的鳞片、建筑的瓦片。这个工具给模型装了个「语义雷达」,让它能结合局部几何和全局上下文,判断哪些部件应该共享材质,用户点一下鳞片,就能自动选中所有鳞片,不用一个个手动选择。
这些研究的共同指向是:视觉模型不再只盯着「标准答案」,而是开始学习「在不完美里找最优解」。
从「做题家」到「探险家」,计算机视觉的这次转向,本质上是向人类视觉系统的一次靠拢——我们从来不是在信息完整、目标明确的情况下理解世界,而是在碎片里拼凑真相,在互动中修正认知,在变化里保持适应。
视觉智能的终极目标,从来不是在基准测试里拿满分,而是成为一个能在复杂、混乱、充满意外的真实世界里,持续理解、持续调整、持续成长的「观察者」。从做对题,到活下去,这才是智能的起点。