对抗知识焦虑,从看懂这条开始
App 下载
AI终于学会“放大看细节”,不再瞎猜相似图片
动态证据查找|图片细节检索|复旦大学|清华大学|V-Retrver框架|多模态视觉|人工智能
想象你在网购时,要从十张看起来几乎一样的白色沙发图里,找出那张抱枕带菱形格纹的——换作以前的AI,大概率会瞎蒙一个答案。但现在,清华大学、复旦大学等团队联手推出的V-Retrver框架,让AI学会了像人一样:拿不准就点开大图看细节。它在通用多模态检索基准上把准确率拉到了69.7%,比此前最好的模型高出近5个百分点,尤其在区分相似图片时,表现提升了10%以上。这背后,是多模态检索从“静态猜答案”到“动态找证据”的关键转折。为什么之前的AI会瞎猜?这得从它的“思考方式”说起。
以前的AI,是“看一眼就做题”的考生
你可以把传统多模态检索模型理解成这样的考生:拿到试卷上的图片,扫一眼就把内容压缩成几句文字描述,之后全程只靠文字推理选答案。比如面对十张白色沙发图,它会把每张图都概括成“白色沙发配抱枕”,至于抱枕纹理、沙发腿形状这些细节,早就被压缩没了。

这就导致一个致命问题:当候选图片语义高度相似、仅细节有别时,模型只能凭运气瞎猜。团队成员把这种局限形容为“用文本推理视觉,天生就会产生幻觉”。更糟的是,传统模型是“一次性看图”——看完就凭印象做题,遇到推理瓶颈时,不会像人一样回去再确认细节,只能硬着头皮往下推。
直给来说:
- 传统方法把图像压缩成固定特征或文本,丢失细节;
- 推理完全依赖文本,无法验证视觉信息;
- 面对相似图片,只能靠概率判断,准确率极低。
交错推理:让AI学会“边想边看边验证”
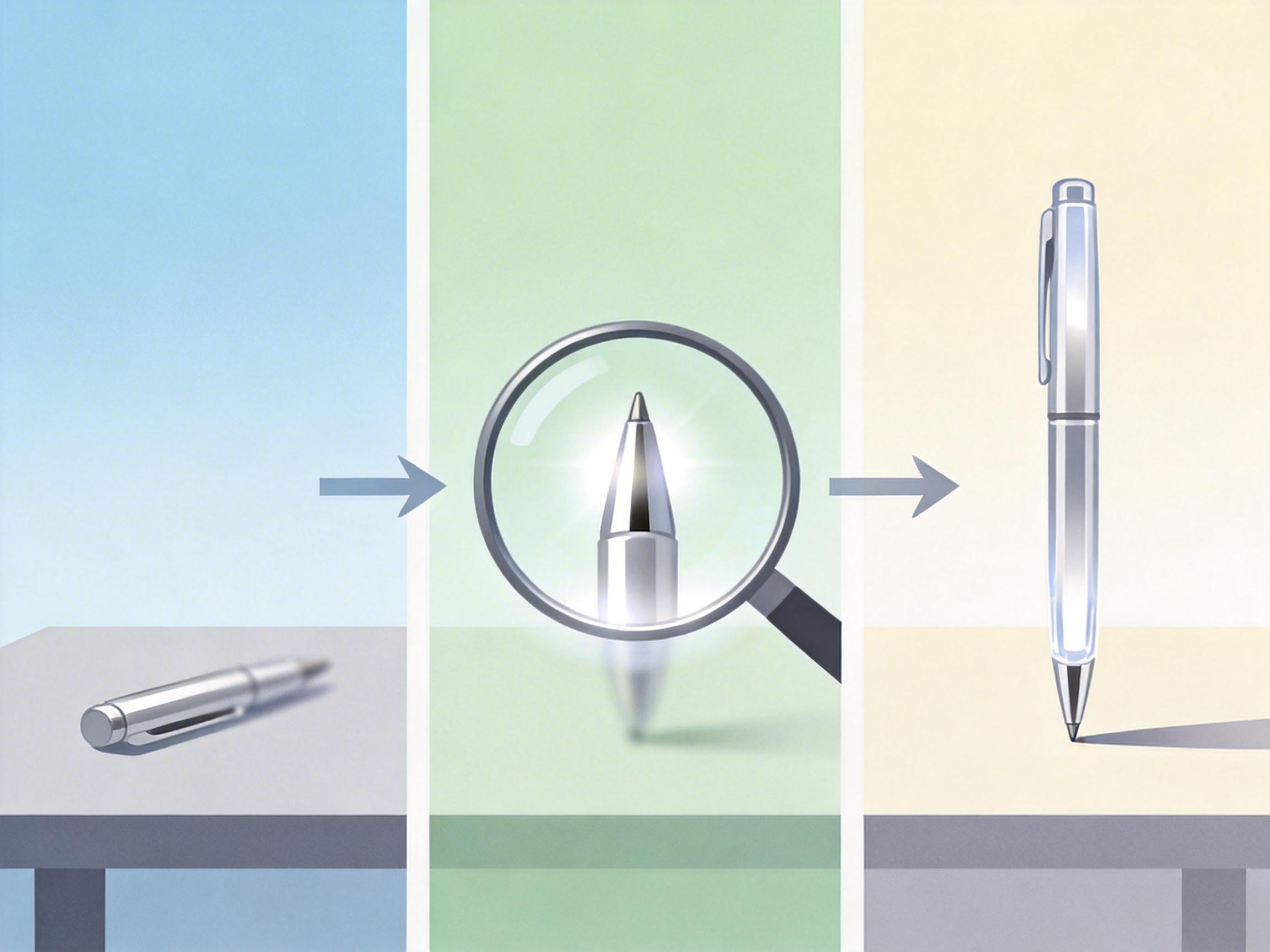
V-Retrver的核心,是把检索变成了一个“交错推理(Interleaved Reasoning)”的智能体过程——简单说,就是让AI在推理时能主动调用视觉工具,像人一样“产生疑问→放大看细节→得出结论”。
比如用户要找“桌上放着银色钢笔的图”,如果候选图里的钢笔很小很模糊,模型不会直接瞎猜,而是主动调用ZOOM-IN工具放大钢笔区域,确认颜色和款式后再做判断。这个过程就像你网购时,拿不准就点开商品详情页的细节图反复对比。
为了让AI学会这种能力,团队设计了三阶段训练: 第一阶段是监督微调,用合成数据教AI基本的工具调用逻辑,既要避免训练不足导致不会用,又要防止训练过度让AI“逢题必放大”; 第二阶段是拒绝采样微调,筛选出高质量的推理轨迹,确保AI的推理逻辑靠谱; 第三阶段是强化学习,给AI设置奖励机制:合理调用工具就加分,瞎调用或该用不用就减分,让AI学会“聪明地用眼”。
实验数据最能说明问题:在细粒度检索任务FashionIQ上,V-Retrver的准确率比前代模型高出13个百分点;在零样本测试中,面对从未见过的数据集,它的表现依然碾压专业检索模型。
不是完美方案,还有两道坎要跨
不过V-Retrver也绝非完美。最直接的问题是成本:动态调用视觉工具意味着更多的计算量,相比传统方法,它的推理时间更长,对硬件的要求也更高——目前还没法在手机这类边缘设备上流畅运行。团队也坦言,“我们在这个工作中没有专门做权衡,这确实是后续要解决的问题”。
另一个局限是工具太少。现在V-Retrver只有ZOOM-IN和SELECT-IMAGE两种视觉工具,面对更复杂的场景就不够用了。比如要找“穿黄色衣服的拿破仑”,如果候选图里有个长得很像的人也穿黄衣服,光靠放大细节没法区分,这时候就需要调用网络搜索工具,补充拿破仑的标志性特征来辅助判断。
更值得关注的是,这种“主动调用工具”的思路,本质上是让AI从“被动接受信息”转向“主动获取信息”,这不仅是多模态检索的范式转变,更是通用AI向类人认知靠拢的重要一步。但随之而来的,还有隐私和伦理问题——如果AI能主动调用网络工具,会不会在未经允许的情况下获取敏感信息?这也是未来必须同步解决的问题。
当我们惊叹于AI终于学会“放大看细节”时,其实更该意识到:真正的智能从来不是“一次性记住所有信息”,而是“在需要的时候主动找答案”。V-Retrver的意义,不仅是提升了多模态检索的准确率,更是验证了一条可行的路径:让AI像人一样思考,不是要复刻人类的大脑,而是要复刻人类解决问题的逻辑——观察、质疑、验证、结论。
未来的AI,或许不需要记住所有细节,但一定要知道,该去哪里找答案。