对抗知识焦虑,从看懂这条开始
App 下载
机器人梦中进化:AI在想象中学会自我纠错,现实瓶颈被打破?
任务失败|自我纠错|演示学习|机械臂|具身智能|人工智能
对抗知识焦虑,从看懂这条开始
App 下载任务失败|自我纠错|演示学习|机械臂|具身智能|人工智能
一台精密的机械臂,在无数次演示学习后,能精准地将方块放入指定位置。但某一次,初始位置稍有偏差,机械臂的夹爪碰到目标边缘,任务卡住了。它不断重复错误的动作,直到被强制重启。这一幕,是具身智能领域长期以来的困境缩影:机器人只是一个“脆弱”的模仿者,它们能完美复刻“正确”的路径,却对“错误”束手无策。一旦现实偏离了训练数据,哪怕一丝一毫,累积的误差就会导致任务彻底失败。
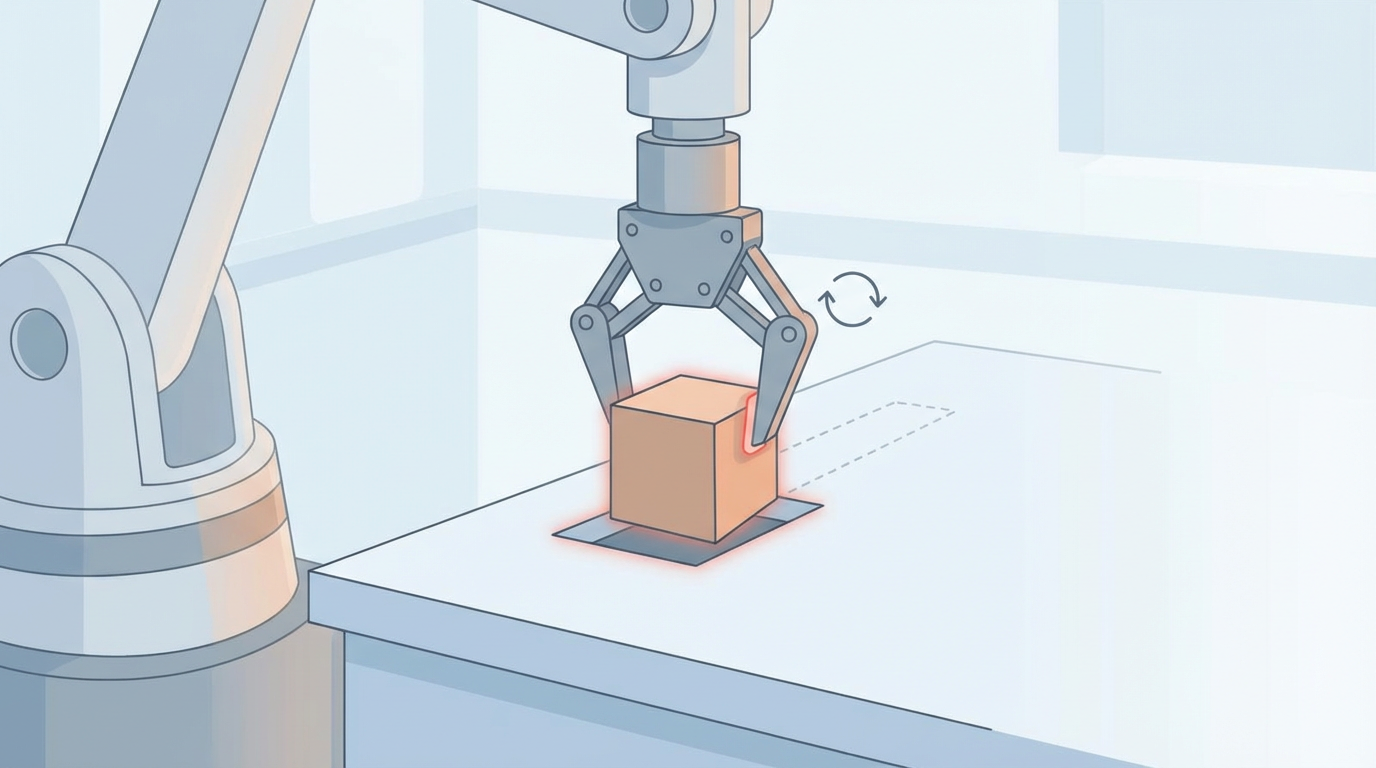
为了解决这个问题,科学家们想到了强化学习(Reinforcement Learning, RL)——让机器像人一样,通过试错来学习。然而,这引出了另一个几乎无法逾越的障碍:高昂的现实代价。在物理世界中进行数百万次试错,不仅意味着巨大的时间消耗和硬件磨损,更伴随着不可控的安全风险。具身智能的进化,似乎被“模仿学习的脆弱性”和“现实交互的昂贵性”这两道紧箍咒牢牢锁住。
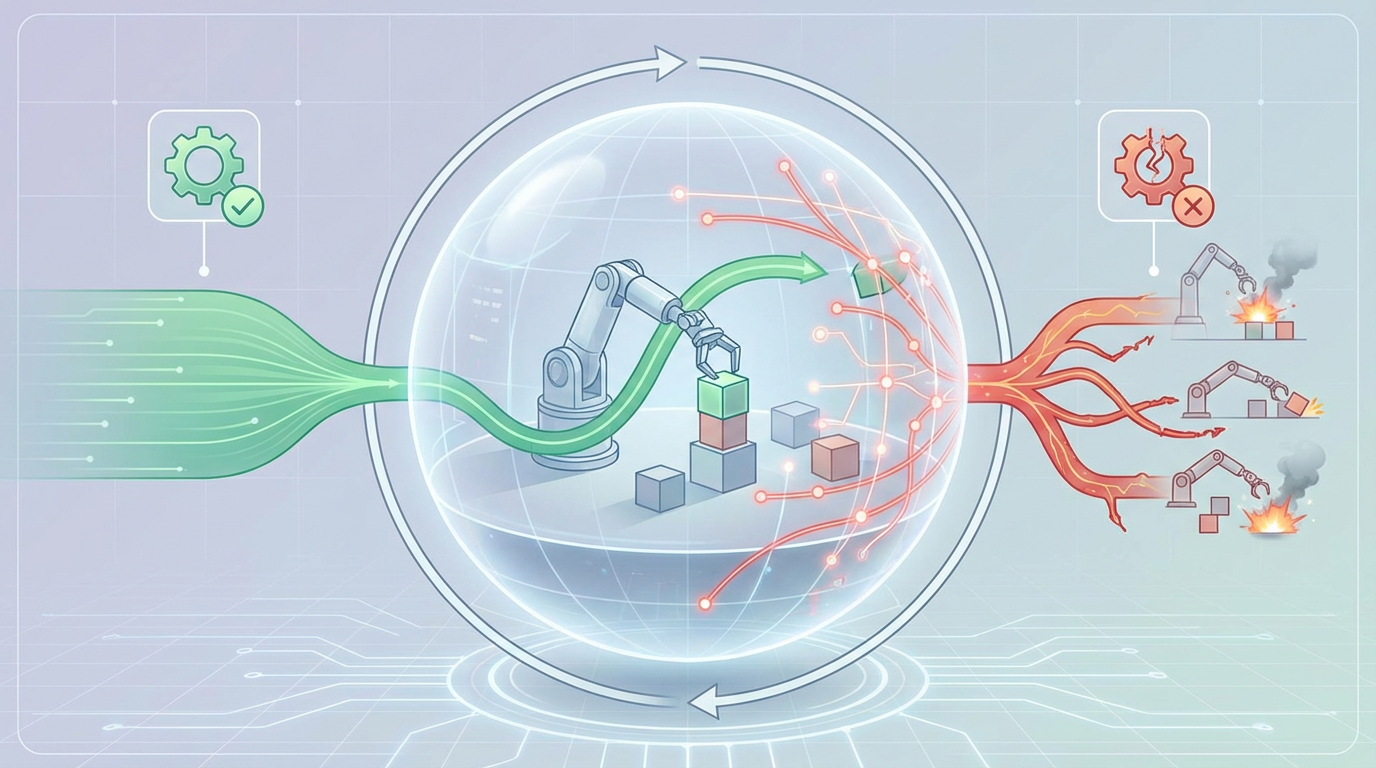
直到最近,一则来自学界的消息,为打破这一僵局带来了曙光。来自香港科技大学PEI-Lab与字节跳动Seed团队的一项名为WMPO(World Model-based Policy Optimization)的研究,提出了一种颠覆性的范式:让机器人在“想象”中训练。这项已被顶会ICLR 2026接收的研究,首次证实了机器人无需在现实世界中进行昂贵的交互,仅凭在脑海中的“排练”,就能学会如何从失败中恢复,甚至涌现出令人惊叹的“自我纠错”能力。
WMPO的核心,是为机器人构建一个高质量的“想象空间”,或者说,一个高保真的“世界模型”。这个模型与以往抽象的、基于潜空间的模拟器有本质区别,它是一个像素级的视觉世界模型。
这意味着,当机器人“想象”一个动作时,它看到的不是一串代码或抽象的符号,而是一帧帧与真实世界无异的、清晰的视觉画面。这个“梦境”能够精准预测出每一个动作将带来的物理后果。
然而,要让“想象”足以替代“实践”,这个梦境不仅要能模拟成功,更关键的是,必须能真实地模拟失败。传统的模仿学习数据里几乎全是成功的案例,机器人无从得知“搞砸了会怎样”。为此,WMPO引入了一项关键机制——策略行为对齐(Policy Behavior Alignment)。
研究团队不仅用完美的专家演示数据来训练这个世界模型,还让机器人当前的策略在模型中自由探索,生成大量非专家、甚至充满错误的轨迹。然后,再用这些“失败案例”去对齐和校准世界模型。如此一来,这个虚拟世界就学会了机器人可能会犯的各种错误,以及这些错误导致的真实物理后果。它成了一个既能预演成功,也能预知失败的完美“沙盒”。
有了这个能真实模拟成败的“梦境”,WMPO将强化学习的过程完全迁移到了想象空间。它采用了一种名为**在线组相对策略优化(Online GRPO)**的方法,这就像在机器人的“脑海”里进行一场达尔文式的生存竞赛。
具体来说,针对同一个初始状态,机器人会在世界模型中生成一组不同的候选动作序列,也就是多条不同的“想象轨迹”。然后,一个内部的“奖励函数”会像裁判一样,评估每一条轨迹的优劣,判断其是否最终完成了任务。
关键在于,这种评估是“相对”的。模型比较的是组内哪条轨迹“更好”,而不是给出一个绝对的分数。这种“组内竞争”机制,天然地让模型偏好那些即使中途犯错、但最终能通过调整来完成任务的路径。那些遇到障碍就卡死的“脆弱”策略,会在一次次的想象竞赛中被自然淘汰。
通过这种方式,机器人不再需要价值网络来辅助判断,大大降低了训练的复杂度和硬件要求。更重要的是,它在一次次的“想象试错”和“路径比较”中,内生地学会了如何纠错。
理论的优雅最终需要现实的检验。在“方块套圈”这类精细操作任务中,WMPO的成果令人震撼。
当只学习模仿的基座模型在尝试中因碰撞或姿态偏移而卡死时,经过WMPO训练的策略展现出了截然不同的行为:它会主动将方块抬起,重新调整姿态对准目标,然后再次尝试,直到成功。整个过程连贯而果断,仿佛一个懂得思考和变通的人类。
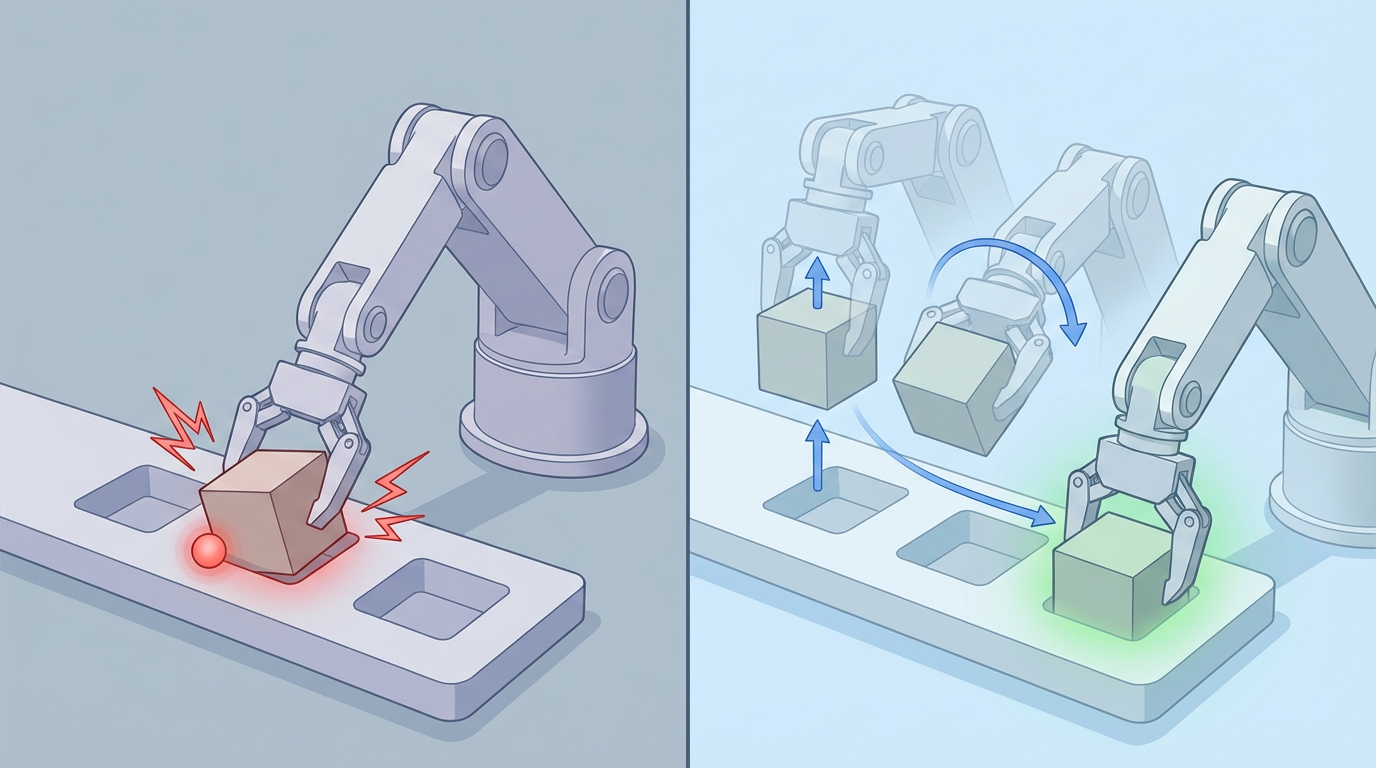
这类复杂的纠错行为,从未在任何专家演示数据中出现过。 它是模型在无数次“想象中的失败与比较”后,自然涌现出的高级智能。实验数据也印证了其高效性:
WMPO的成功,不仅仅是一项算法的突破,它深刻地揭示了具身智能未来发展的一个核心方向:高质量的“想象”足以替代昂贵的“实践”。
通过将强化学习过程与现实世界解耦,WMPO为解决具身智能面临的数据和成本双重瓶颈,指明了一条充满想象力的道路。它让机器人从一个只能被动模仿的“学徒”,进化为一个能够在内心世界中进行推演、反思和自我完善的“决策者”。
当然,这项技术目前主要在结构化的操作任务中得到验证,其在更开放、更复杂场景下的泛化能力仍是未来需要探索的课题。但它无疑已经开启了一扇新的大门,门后是一个机器人能够通过“思考”和“想象”来适应我们这个复杂多变的世界的未来。
正如达芬奇所言,“简单是终极的复杂”。WMPO用纯粹的视觉模拟,让机器人拥有了“想象力”这一看似简单的能力,而这,或许正是通往通用人工智能那条漫长道路上,一次至关重要的飞跃。