对抗知识焦虑,从看懂这条开始
App 下载
AI自主干活不再失控,这个内核管得住
自主AI控制|API调用安全|高危操作拦截率|香港中文大学|ArbiterOS|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自主AI控制|API调用安全|高危操作拦截率|香港中文大学|ArbiterOS|AI智能体|人工智能
当AI开始自己调用API、删文件、连设备,你以为训练时教它的“规矩”还管得住吗?2026年的测试数据给了冰冷答案:在涉及私钥泄露、文件误删的高风险任务里,主流智能体的高危动作拦截率只有6.17%——意味着16次危险操作里,只能拦住1次。更糟的是,攻击者只要换个话术就能绕过提示词约束,用户盯着弹窗确认也看不出API调用藏着的猫腻。直到香港中文大学的团队拿出ArbiterOS,把这个数字拉到了92.95%。它不是又一个外挂过滤器,而是给自主AI补上了缺失的“刹车系统”。
你可以把传统智能体想象成一个拿着车钥匙的司机:既负责规划路线,又直接掌控油门刹车——一旦它被误导,车就直接冲出去了。ArbiterOS做的,就是把钥匙收回来,自己当那个管油门的人。
它的核心是“特权分离”:AI只负责输出“我要做什么”的想法,所有要落地的动作,都得先经过ArbiterOS的四步审核。第一步是拦截——在AI删除文件、调用敏感API的动作真正执行前,先把操作拦下来;第二步是解析,把AI说的自然语言转成机器能看懂的结构化指令,比如“动作:HTTP请求,目标地址xxx,携带数据来自本地配置文件”;第三步是治理,用动态污点追踪盯着数据的来龙去脉——如果AI要发送的数据是从敏感配置里读出来的,哪怕请求本身看起来正常,也会被直接阻断;最后一步是观测,把整个过程记成可溯源的证据链,方便事后复盘优化规则。
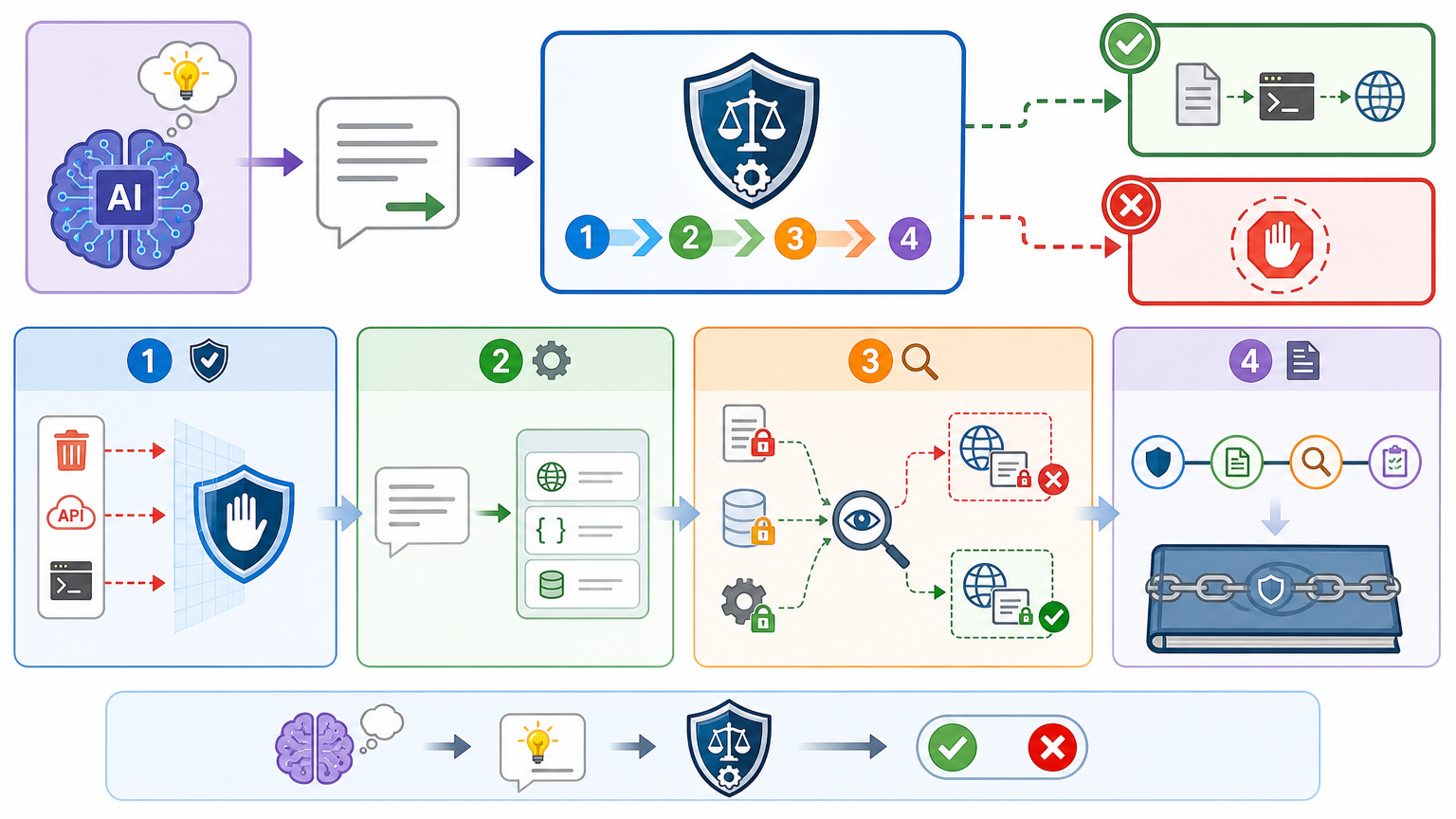
这套流程的厉害之处,在于它不管AI“说”了什么,只盯着它“要做什么”和“用了什么数据”。测试里,它能在AgentDojo的攻击样本里拦下94%的危险操作,在复杂工作流里实现100%预警——这是靠提示词过滤或沙箱隔离根本做不到的。
之前大家对付AI风险,要么用沙箱把AI关在笼子里,要么用语义护栏过滤敏感词,但这俩都有致命缺陷:沙箱关太严,AI连正常工作都费劲;护栏只会看字面意思,绕个弯就被突破了。
ArbiterOS不一样,它是带着“上下文判断力”的治理内核。比如沙箱只会一刀切禁止AI访问外部API,而ArbiterOS会先看:这个API调用是AI完成任务必须的吗?调用的数据来自哪里?如果是用户授权的公开数据,就放行;如果是从私密文件里“偷”来的数据,就拦截。再比如语义护栏只会盯着“私钥”“密码”这些关键词,但攻击者把私钥藏在一段看似正常的文本里,护栏就瞎了——ArbiterOS却能通过污点追踪,发现这段文本来自敏感文件,直接把风险掐灭在执行前。
当然它也不是万能的。目前它还依赖开发者把智能体的动作边界、风险点清晰定义成规则,要是规则没覆盖到的新风险,它也可能漏掉。而且面对极端复杂的多智能体协同,如何追踪跨智能体的数据流污染,也是还没完全解决的问题。
现在的AI还只是单个的“自主工人”,但未来会是成千上万AI协同工作的“智能体社会”——到那时候,光靠每个AI自己“守规矩”肯定不够,得有一套像交通规则一样的底层治理体系。

ArbiterOS的意义,就是给这套体系打了个样。它不绑定特定的AI框架,不管是OpenClaw还是HermesAgent,只要开发者定义好规则,就能快速接入。这意味着它能成为一个通用的“治理底座”,就像现在的操作系统一样,给不同的AI应用提供统一的安全保障。
更重要的是,它把AI治理从“靠模型自觉”的软约束,变成了“靠技术强制执行”的硬规则。以前AI泄露数据,你只能事后查日志;现在它能在数据要出去的瞬间就拦下来,还能告诉你为什么拦——是触发了哪条规则,数据来自哪里。这种可审计、可追溯的能力,正是金融、医疗这些高敏感行业最需要的。
当我们谈论AI安全时,最容易陷入的误区是:总想让AI“变乖”,却忘了给它装个“可控的刹车”。ArbiterOS的出现,其实是换了个思路:与其在AI脑子里反复灌输“不能做什么”,不如在它动手前,先确认“能不能做”。
未来的智能体社会,信任的基础从来不是AI“不会犯错”,而是“犯了错能被及时拦住”。ArbiterOS做的,就是给这个社会铺上第一块信任的砖——让每一个AI的动作,都有迹可循、有规可依。
金句:AI自主的前提,是动作可控。